

哈夫曼算法的理解及原理分析,算法实现,构造哈夫曼树的算法
人工智能
描述
哈夫曼树的介绍
Huffman Tree,中文名是哈夫曼树或霍夫曼树,它是最优二叉树。
定义:给定n个权值作为n个叶子结点,构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树。 这个定义里面涉及到了几个陌生的概念,下面就是一颗哈夫曼树,我们来看图解答。
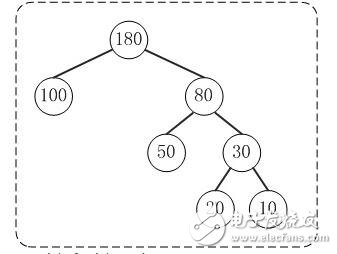
(1) 路径和路径长度
定义:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
例子:100和80的路径长度是1,50和30的路径长度是2,20和10的路径长度是3。
(2) 结点的权及带权路径长度
定义:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
例子:节点20的路径长度是3,它的带权路径长度= 路径长度 * 权 = 3 * 20 = 60。
(3) 树的带权路径长度
定义:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
例子:示例中,树的WPL= 1*100 + 2*50 + 3*20 + 3*10 = 100 + 100 + 60 + 30 = 290。
比较下面两棵树
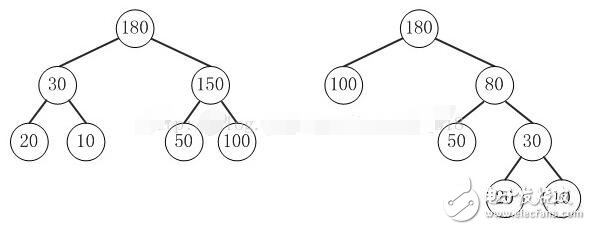
上面的两棵树都是以{10, 20, 50, 100}为叶子节点的树。
左边的树WPL=2*10 + 2*20 + 2*50 + 2*100 = 360
右边的树WPL=290
左边的树WPL 》 右边的树的WPL。你也可以计算除上面两种示例之外的情况,但实际上右边的树就是{10,20,50,100}对应的哈夫曼树。至此,应该对哈夫曼树的概念有了一定的了解了,下面看看如何去构造一棵哈夫曼树。
哈夫曼树的图文解析
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,哈夫曼树的构造规则为:
1. 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
2. 在森林中选出根结点的权值最小的两棵树进行合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
3. 从森林中删除选取的两棵树,并将新树加入森林;
4. 重复(02)、(03)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
以{5,6,7,8,15}为例,来构造一棵哈夫曼树。
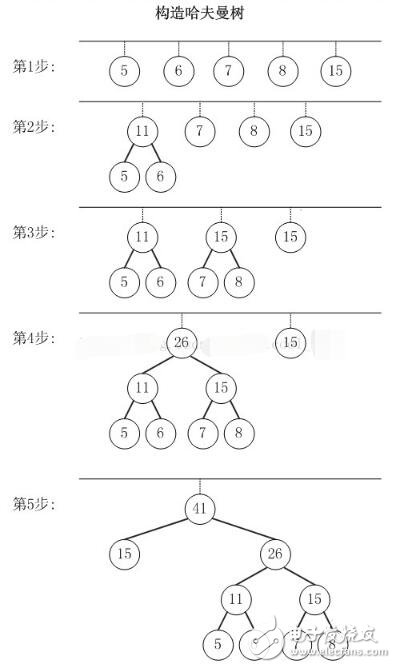
第1步:创建森林,森林包括5棵树,这5棵树的权值分别是5,6,7,8,15。
第2步:在森林中,选择根节点权值最小的两棵树(5和6)来进行合并,将它们作为一颗新树的左右孩子(谁左谁右无关紧要,这里,我们选择较小的作为左孩子),并且新树的权值是左右孩子的权值之和。即,新树的权值是11。 然后,将“树5”和“树6”从森林中删除,并将新的树(树11)添加到森林中。
第3步:在森林中,选择根节点权值最小的两棵树(7和8)来进行合并。得到的新树的权值是15。 然后,将“树7”和“树8”从森林中删除,并将新的树(树15)添加到森林中。
第4步:在森林中,选择根节点权值最小的两棵树(11和15)来进行合并。得到的新树的权值是26。 然后,将“树11”和“树15”从森林中删除,并将新的树(树26)添加到森林中。
第5步:在森林中,选择根节点权值最小的两棵树(15和26)来进行合并。得到的新树的权值是41。 然后,将“树15”和“树26”从森林中删除,并将新的树(树41)添加到森林中。
此时,森林中只有一棵树(树41)。这棵树就是我们需要的哈夫曼树!
哈夫曼树是一种树形结构,用哈夫曼树的方法解编程题的算法就叫做哈夫曼算法。树并不是指植物,而是一种数据结构,因为其存放方式颇有点象一棵树有树叉因而称为树。 最简哈夫曼树是由德国数学家冯。哈夫曼 发现的,此树的特点就是引出的路程最短。
哈夫曼算法
哈夫曼树是一种树形结构,用哈夫曼树的方法解编程题的算法就叫做哈夫曼算法。树并不是指植物,而是一种数据结构。
定义:它是由n个带权叶子结点构成的所有二叉树中带权路径长度最短的二叉树。因为这种树最早由哈夫曼(Huffman)研究,所以称为哈夫曼树,又叫最优二叉树。
构造哈夫曼树
[html] view plain copy/*
* 创建Huffman树
*
* @param 权值数组
*/
public Huffman(int a[]) {
HuffmanNode parent = null;
MinHeap heap;
// 建立数组a对应的最小堆
heap = new MinHeap(a);
for(int i=0; i《a.length-1; i++) {
HuffmanNode left = heap.dumpFromMinimum(); // 最小节点是左孩子
HuffmanNode right = heap.dumpFromMinimum(); // 其次才是右孩子
// 新建parent节点,左右孩子分别是left/right;
// parent的大小是左右孩子之和
parent = new HuffmanNode(left.key+right.key, left, right, null);
left.parent = parent;
right.parent = parent;
// 将parent节点数据拷贝到“最小堆”中
heap.insert(parent);
}
mRoot = parent;
// 销毁最小堆
heap.destroy();
}
首先创建最小堆,然后进入for循环。
每次循环时:
(1) 首先,将最小堆中的最小节点拷贝一份并赋值给left,然后重塑最小堆(将最小节点和后面的节点交换位置,接着将“交换位置后的最小节点”之前的全部元素重新构造成最小堆);
(2) 接着,再将最小堆中的最小节点拷贝一份并将其赋值right,然后再次重塑最小堆;
(3) 然后,新建节点parent,并将它作为left和right的父节点;
(4) 接着,将parent的数据复制给最小堆中的指定节点。
哈夫曼算法原理
1952年, David A. Huffman提出了一个不同的算法,这个算法可以为任何的可能性提供出一个理想的树。香农-范诺编码(Shanno-Fano)是从树的根节点到叶子节点所进行的的编码,哈夫曼编码算法却是从相反的方向,暨从叶子节点到根节点的方向编码的。
1.为每个符号建立一个叶子节点,并加上其相应的发生频率
2.当有一个以上的节点存在时,进行下列循环:
1)把这些节点作为带权值的二叉树的根节点,左右子树为空
2)选择两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且至新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
3)把权值最小的两个根节点移除
4)将新的二叉树加入队列中。
5)最后剩下的节点暨为根节点,此时二叉树已经完成。
哈夫曼树的应用
哈夫曼编码:
哈夫曼树可以直接应用于通信及数据传送中的二进制编码。设: D={d1,d2,d3…dn}为需要编码的字符集合。
W={w1,w2,w3,…wn}为D中各字符出现的频率。 现要对D中的字符进行二进制编码,使得:
(1) 按给出的编码传输文件时,通信编码的总长最短。
(2) 若di不等于dj,则di的编码不可能是dj的编码的开始部分(前缀)。
满足上述要求的二进制编码称为最优前缀编码。 上述要求的第一条是为了提高传输的速度,第二条是为了保证传输的信息在译码时无二性,所以在字符的编码中间不需要添加任意的分割符。
对于这个问题,可以利用哈夫曼树加以解决:用d1,d2,d3…dn作为外部结点,用w1,w2,w3…wn作为外部结点的权,构造哈夫曼树。在哈夫曼树中把从每个结点引向其左子结点的边标上二进制数“0”,把从每个结点引向右子节点的边标上二进制数“1”,从根到每个叶结点的路径上的二进制数连接起来,就是这个叶结点所代表字符的最优前缀编码。通常把这种编码称为哈夫曼编码。例如:
D={d1,d2,d3,d4,d5,d6,d7,d8,d9,d10,d11,d12,d13} W={2,3,5,7,11,13,17,19,23,29,31,37,41} 利用哈夫曼算法构造出如下图所示的哈夫曼树:
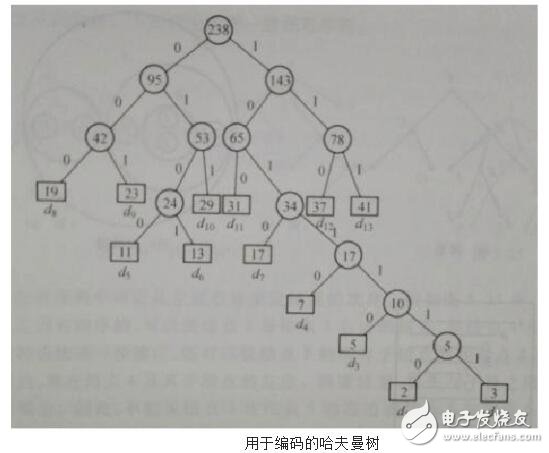
从而得到各字符的编码为:
d1:1011110 d2:1011111
d3:101110 d4:10110
d5:0100 d6:0101
d7:1010 d8:000
d9:001 d10:011
d11:100 d12:110
d13:111
编码的结果是,出现频率大的字符其编码较短,出现频率较小的字符其编码较长。
哈夫曼算法实现
实现的时候我们用vector《bool》记录每个char的编码;用map《char,vector《bool》》表示整个字典;
就得到了下面的代码(下面有两个,一对一错):
先放出来这个错的,以示警戒:
[cpp] view plain copy/************************************************************************/
/* File Name: Huffman.cpp
* @Function: Lossless Compression
@Author: Sophia Zhang
@Create Time: 2012-9-26 10:40
@Last Modify: 2012-9-26 11:10
*/
/************************************************************************/
#include“iostream”
#include “queue”
#include “map”
#include “string”
#include “iterator”
#include “vector”
#include “algorithm”
using namespace std;
#define NChar 8 //suppose use at most 8 bits to describe all symbols
#define Nsymbols 1《《NChar //can describe 256 symbols totally (include a-z, A-Z)
typedef vector《bool》 Huff_code;//8 bit code of one char
map《char,Huff_code》 Huff_Dic; //huffman coding dictionary
class HTree
{
public :
HTree* left;
HTree* right;
char ch;
int weight;
HTree(){left = right = NULL; weight=0;}
HTree(HTree* l,HTree* r,int w,char c){left = l; right = r; weight=w; ch=c;}
~HTree(){delete left; delete right;}
int Getweight(){return weight?weight:left-》weight+right-》weight;}
bool Isleaf(){return !left && !right; }
bool operator 《 (const HTree tr) const
{
return tr.weight 《 weight;
}
};
HTree* BuildTree(int *frequency)
{
priority_queue《HTree*》 QTree;
//1st level add characters
for (int i=0;i《Nsymbols;i++)
{
if(frequency[i])
QTree.push(new HTree(NULL,NULL,frequency[i],(char)i));
}
//build
while (QTree.size()》1)
{
HTree* lc = QTree.top();
QTree.pop();
HTree* rc = QTree.top();
QTree.pop();
HTree* parent = new HTree(lc,rc,parent-》Getweight(),(char)256);
QTree.push(parent);
}
//return tree root
return QTree.top();
}
void Huffman_Coding(HTree* root, Huff_code& curcode)
{
if(root-》Isleaf())
{
Huff_Dic[root-》ch] = curcode;
return;
}
Huff_code& lcode = curcode;
Huff_code& rcode = curcode;
lcode.push_back(false);
rcode.push_back(true);
Huffman_Coding(root-》left,lcode);
Huffman_Coding(root-》right,rcode);
}
int main()
{
int freq[Nsymbols] = {0};
char *str = “this is the string need to be compressed”;
//statistic character frequency
while (*str!=‘\0’)
freq[*str++]++;
//build tree
HTree* r = BuildTree(freq);
Huff_code nullcode;
nullcode.clear();
Huffman_Coding(r,nullcode);
for(map《char,Huff_code》::iterator it = Huff_Dic.begin(); it != Huff_Dic.end(); it++)
{
cout《《(*it).first《《‘\t’;
Huff_code vec_code = (*it).second;
for (vector《bool》::iterator vit = vec_code.begin(); vit!=vec_code.end();vit++)
{
cout《《(*vit)《《endl;
}
}
}
上面这段代码,我运行出来不对。在调试的时候发现了一个问题,就是QTree优先队列中的排序出了问题,说来也是,上面的代码中,我重载小于号是对HTree object做的;而实际上我建树时用的是指针,那么优先级队列中元素为指针时该怎么办呢?
那我们将friend bool operator 》(Node node1,Node node2)修改为friend bool operator 》(Node* node1,Node* node2),也就是传递的是Node的指针行不行呢?
答案是不可以,因为根据c++primer中重载操作符中讲的“程序员只能为类类型或枚举类型的操作数定义重载操作符,在把操作符声明为类的成员时,至少有一个类或枚举类型的参数按照值或者引用的方式传递”,也就是说friend bool operator 》(Node* node1,Node* node2)形参中都是指针类型的是不可以的。我们只能再建一个类,用其中的重载()操作符作为优先队列的比较函数。
就得到了下面正确的代码:
[cpp] view plain copy/************************************************************************/
/* File Name: Huffman.cpp
* @Function: Lossless Compression
@Author: Sophia Zhang
@Create Time: 2012-9-26 10:40
@Last Modify: 2012-9-26 12:10
*/
/************************************************************************/
#include“iostream”
#include “queue”
#include “map”
#include “string”
#include “iterator”
#include “vector”
#include “algorithm”
using namespace std;
#define NChar 8 //suppose use 8 bits to describe all symbols
#define Nsymbols 1《《NChar //can describe 256 symbols totally (include a-z, A-Z)
typedef vector《bool》 Huff_code;//8 bit code of one char
map《char,Huff_code》 Huff_Dic; //huffman coding dictionary
/************************************************************************/
/* Tree Class elements:
*2 child trees
*character and frequency of current node
*/
/************************************************************************/
class HTree
{
public :
HTree* left;
HTree* right;
char ch;
int weight;
HTree(){left = right = NULL; weight=0;ch =‘\0’;}
HTree(HTree* l,HTree* r,int w,char c){left = l; right = r; weight=w; ch=c;}
~HTree(){delete left; delete right;}
bool Isleaf(){return !left && !right; }
};
/************************************************************************/
/* prepare for pointer sorting*/
/*because we cannot use overloading in class HTree directly*/
/************************************************************************/
class Compare_tree
{
public:
bool operator () (HTree* t1, HTree* t2)
{
return t1-》weight》 t2-》weight;
}
};
/************************************************************************/
/* use priority queue to build huffman tree*/
/************************************************************************/
HTree* BuildTree(int *frequency)
{
priority_queue《HTree*,vector《HTree*》,Compare_tree》 QTree;
//1st level add characters
for (int i=0;i《Nsymbols;i++)
{
if(frequency[i])
QTree.push(new HTree(NULL,NULL,frequency[i],(char)i));
}
//build
while (QTree.size()》1)
{
HTree* lc = QTree.top();
QTree.pop();
HTree* rc = QTree.top();
QTree.pop();
HTree* parent = new HTree(lc,rc,lc-》weight+rc-》weight,(char)256);
QTree.push(parent);
}
//return tree root
return QTree.top();
}
/************************************************************************/
/* Give Huffman Coding to the Huffman Tree*/
/************************************************************************/
void Huffman_Coding(HTree* root, Huff_code& curcode)
{
if(root-》Isleaf())
{
Huff_Dic[root-》ch] = curcode;
return;
}
Huff_code lcode = curcode;
Huff_code rcode = curcode;
lcode.push_back(false);
rcode.push_back(true);
Huffman_Coding(root-》left,lcode);
Huffman_Coding(root-》right,rcode);
}
int main()
{
int freq[Nsymbols] = {0};
char *str = “this is the string need to be compressed”;
//statistic character frequency
while (*str!=‘\0’)
freq[*str++]++;
//build tree
HTree* r = BuildTree(freq);
Huff_code nullcode;
nullcode.clear();
Huffman_Coding(r,nullcode);
for(map《char,Huff_code》::iterator it = Huff_Dic.begin(); it != Huff_Dic.end(); it++)
{
cout《《(*it).first《《‘\t’;
std::copy(it-》second.begin(),it-》second.end(),std::ostream_iterator《bool》(cout));
cout《《endl;
}
}
-
结构数据:5.6.2 哈夫曼树和哈夫曼算法-教学视频(1)#结构数据学习硬声知识 2022-12-16
-
结构数据:5.6.2 哈夫曼树和哈夫曼算法-教学视频(2)#结构数据学习硬声知识 2022-12-16
-
算法设计:6.6 哈夫曼树编程实现(1)#硬声创作季学习电子 2022-12-21
-
算法设计:6.6 哈夫曼树编程实现(2)#硬声创作季学习电子 2022-12-21
-
算法设计:哈夫曼编码(1)#硬声创作季学习电子 2022-12-21
-
[4.3]--哈夫曼编码算法_clip002jf_75936199 2023-01-06
-
哈夫曼树和哈夫曼编码(1)#数据结构与算法未来加油dz 2023-09-13
-
哈夫曼树和哈夫曼编码(2)#数据结构与算法未来加油dz 2023-09-13
-
哈夫曼树和哈夫曼编码(3)#数据结构与算法未来加油dz 2023-09-13
-
图书分享:卡尔曼滤波算法的几何解释2015-06-11 0
-
LabVIEW一维卡尔曼滤波算法2017-10-21 0
-
卡尔曼滤波算法是怎么实现对数据的预测处理的?2023-10-10 0
-
卡尔曼滤波算法对比其他的滤波算法有什么优点?2023-10-11 0
全部0条评论

快来发表一下你的评论吧 !
