

hbase和关系型数据库的区别
编程语言及工具
描述
HBase相对于关系数据库能解决的问题是什么?
关于HBase与关系数据的区别问题其实就是关系数据库与HBase各自的优缺点。
关系数据库的缺憾:
1) 扩展困难
2) 维护复杂
HBase就是解决可伸缩行的问题。通过简单增加节点来获取线性扩展性。不支持SQL。
图解Nosql(hbase)与传统数据库的区别
对于大多数做技术的人员,都知道我们传统数据库是什么样子的,那么如下图所示,我们操作的对象是行。也就是增删改查,都是以为对象
1. 传统数据库增加删除介绍

下面我们以mysql为例:
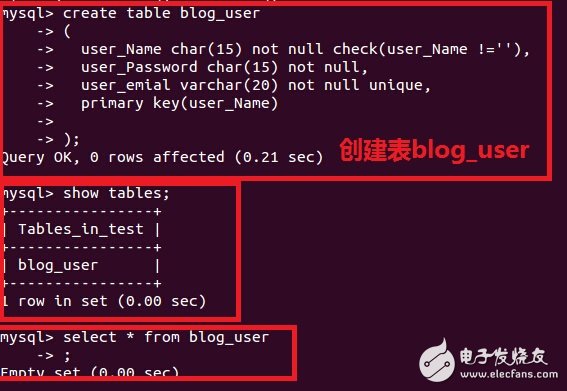
插入数据
mysql》INSERT INTO blog_user (`user_Name`,`user_Password`,`user_emial`)VALUES (‘aboutyun’,‘aboutyun’, ‘aboutyun@sina.com’);

删除数据:
mysql》 delete from blog_user where user_name=“aboutyun”;

2. Nosql数据库增加删除介绍
以hbase为例:
创建表:
create ‘blog_user’,‘userInfo’

插入数据
这里是关键点,也是很多人不容易理解的地方
hbase(main):012:0》 put‘blog_user’,‘www.aboutyun.com’,‘userInfo:user_Name’,‘aboutyun’
0 row(s) in 1.7530 seconds

上面我们看到了
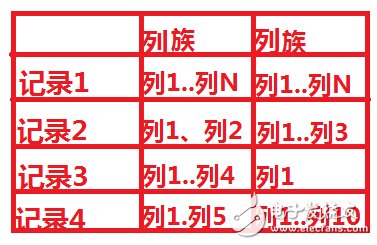
1所示是什么,我们在传统数据块里面根本没有,这是nosql所特有的,是一个rowkey,是系统自带的,也是nosql中一条记录的唯一标识。但是这个唯一标识,有跟我们的传统数据库是有所差别的。如图1所示,“记录1”便是rowkey.
2所示是我们插入的列user_Name,这也是最难以理解的地方,列竟然可以插入。并且其’value‘为3即‘aboutyun’
我们插入了列,下面我们来查看一下效果:

下面来解释一下上面的含义:
我们会看到
1为rowkey,插入数据’www.aboutyun.com‘,
2为列族下面列的名字user_Name
3我们并没有在设计的添加这个列族,所以这个是系统自带的,这个是记录的操作时间,以时间戳的形式放到hbase里面。
4是我们插入的user_Name的值
下面我们在插入password:
1. hbase(main):015:0》 put‘blog_user’,‘www.aboutyun.com’,‘userInfo:user_Password’,‘aboutyun’

再次查询结果:
1. hbase(main):016:0》 scan ‘blog_user’
2. ROW COLUMN+CELL
3. www.aboutyun.com column=userInfo:user_Name, timestamp=1400663775901, value=aboutyun
4. www.aboutyun.com column=userInfo:user_Password, timestamp=1400665203430, value=aboutyun
5. 1 row(s) in 0.0390 seconds

到这里,我们看到两行记录,传统数据块认为这是两行数据,对于nosql,这是一条记录。
删除列数据
删除数据分为删除列和删除记录
1.删除列
这里面的删除,没有删除
delete ‘blog_user’,‘www.aboutyun.com’,‘userInfo:user_Password’

从上面我们看出列被删除了
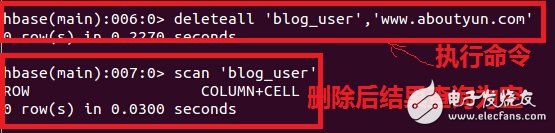
2.删除记录:
1. deleteall ‘blog_user’,‘www.aboutyun.com’
2. 这是删除之前显示结果,这里已经是

删除后结果
结论:
对于传统数据库,增加列对于一个项目来讲,改变是非常大的。但是对于nosql,插入列和删除列,跟传统数据库里面的增加记录和删除记录类似
HBase有哪些基本的特征?
HBase是类似于google的bigtable的开源实现,拥有以下特征:
1)在HDFS之上
2) 基于列存储的分布式数据库
3) 用于实时地读、写大规模数据集
其他HBase的特性:
1)没有真正的索引,行顺序存储,也没有所谓的索引膨胀问题。
2) 自动分区,表增长时,自动分区到新的节点上。
3) 线性扩展和区域会自动重新平衡,运行RegionServer,达到负载均衡的目的。
4)容错和普通商用的硬件支持。这点同hadoop类似。
HBase与RDBMS的区别?
1) 表的设计:HBase的表可以很高,很宽,可伸缩性很强。而且表的模式是物理存储的直接反映。
2) 拓扑: HBase能水平分区并在上千个节点上自动复制。
3) 应用形式: 开发者必须承担更多的责任来正确地利用HBase的检索和存储方式。
4) RDBMS 遵循固定的模式,如“codd 12 规则”,强调事务的“强一致性”、参照完整性、SQL支持、数据的逻辑与物理形式相对独立。等等。适用于中小规模的数据,但对于数据的规模和并发读写方面进行大规模扩展时,RDBMS会性能大大降低,分布式更为困难,因为其需要放弃很多RDBMS的易用的特性。
HBase适用于上亿、上千亿级的数据,如果是只有上千、上百万级别是数据,传统的RDBMS是更好的选择。
HBase需要更多硬件,如果硬件较少,如5个,干不成什么好事。
如果从RDBMS移植到HBase,需要消除RDBMS的很多额外特性,如列数据类型、第二索引、事务、高级查询等。
HBase的数据模式是怎么样的?即有哪些元素?如何存储?
1) 数据模式
如下列三个表:
第一个是一个稀疏的表,实际上它是一个虚表,仅是一个概念视图,不是真实的存储形式,它来源于后两个表。
而后两个表才是真正的表,物理视图,他们是实际的存储形式,而且它们是按列族进行存储的。
2) HBase的基本元素:
表、行、列、单元格: 表的基本要素
键:一般是指行的键,即唯一标识某行的元素。表中的行,可以根据键进行排序,而对表的访问,也通过键。
列族:所有列族成员拥有相同的前缀,某列族的成员,需要预先定义,但也可以直接进行追加。
列族成员会一起放进存储器。而HBase面向列的存储,是面向列族的数据存储(这个通过上面那个表的示例可以看出来),数据存储与调优都在这个层次,HBase表与RDBMS中表类似,行是排序的,客户端可以把列添加到列族中去。
单元格cell: 单元格中存放的是不可分割的字节数组。并且每个单元格拥有版本信息。HBase的是按版本信息倒序排列。
区域region:将表水平划分,是HBase集群分布数据的最小单位。在线的所有区域就构成了表的内容。
加锁:对数据行进行更新,都需加锁。保持原子性。
3) 数据模型有哪些操作?
Get、Scan、Put、Delete,即返回特定行的属性,多行属性、插入、删除数据。
这些都需要一个HTable实例来操作。分别有Get、Scan、Put、Delete类来指定相应的参数、属性。
4) 返回结果的排序方式是什么?
先是行、再是列族、再是列修饰符,最后是时间戳(反向排序,最新的在前面)。
5)最后,HBase不支持联合查询
6)mapreduce与HBase表配合使用,默认mapreduce的任务分割是根据HBase表中region的多少来分割,一个region就有一个map。
HBase的模式Schema设计的一些概念和原则
1)模式的创建与更新
可以使用HBase Shell或HBase Admin来创建和编辑HBase的模式。
在0.90.x 版本,只能先禁用表,再修改列族,而0.92.x版本以后,支持在线修改。
而且表和列族修改后,如size, region, block size等,在下次 主紧缩 或 存储文件时 起作用。
2)列族的数量
-列族数量越少越好,即使同时有两个列族,查询的时候总是访问其中一个列族,不会同时访问。
-当一个表存在多个列族,当基数差距很大时,如A族有100万行,B族10亿行,A族可能会被分散到很多区域region,导致扫描A的效率降低。
-另外,多个列族在flush和compaction时,会造成很多I/O负担。
3)行键设计RowKey
a. 不要将RowKey设计成有序的形式,因为这样容易阻塞并行性,将负载压都在一台机器上
b. 定位一个单元,需要行,列名和时间戳。如果一个单元格的坐标很大,会占用内存,索引用光。所以,解决方法:列族名尽量小,如一个字符a,短属性名,而行键长度可读即可(行键长度对数据访问无太大影响),将数字字符转换为数字字节模式(节省空间)。
c. 倒序时间戳有助于找到找到最近版本值
d. 行键是在列族范围内有效,不同列族中可以拥有同样的行键
e. 行键永远不能变
4)HBase支持所有能转换为字节数组的东西,如字符串、数字、复杂对象、计数器、甚至图像。
5)列族可以设置存活时间TTL,超时后,HBase自动删除数据
6)第二索引和查询: 这里面有很多东西,需要查看对应版本官方的文档更好些。
HBase的拓扑结构是什么?
1)拓扑结构: 类似于HDFS的mast与slave,mapreduce的tasktracker与jobtracker的关系,HBase也有master和RegionServer
2)HBase与ZooKeeper的关系是什么?
HBase必须管理一个ZooKeeper实例,它依赖ZooKeeper,主要目的是,通过ZooKeeper来协调区域内的服务器,它负责目录表、主控机地址等重要信息,若有服务器崩溃,HBase就可以通过ZooKeeper来协调分配。
RegionServer在HBase的配置文件conf/regionservers文件中,而HBase集群的站点配置在conf/hbase-site.xml和conf/hbase-env.sh中配置。HBase尽量遵循了Hadoop的规则。
3)HBase的内部结构管理状况:
其内部有-ROOT, -META的特殊目录表,用于维护当前集群上所有区域的列表、位置和状态。
-ROOT表包含 -META表的区域列表,而-META表示包含用户的的区域列表。
所以,HBase管理的流程是:
Client -- 链接到ZooKeeper -- 查找-ROOT表的位置 -- 查找-META表的位置 -- 查找用户的区域所在的节点、位置及其状态等 -- 直接管理指定区域的RegionServer并进行交互。
HBase支持Java及MapReduce的开发。
HBase提供了Thrift、REST及Avro的接口。HBase需要有一个相应的接口客户端负责与这些接口的交互。但是这些需要代理进行处理请求和响应,所以比java更慢。
%hbase-daemon.sh start/stop rest/thrift/avro //启动或终止对应的客户端
-
数据库连接2014-06-29 0
-
建立与数据库的连接2014-07-01 0
-
【2018开年知识盛会】15位大咖直播分享,全方位解析NoSQL数据库2018-01-15 0
-
阿里云云数据库开了一个未来大会,谈了谈2038年的数据库趋势2018-01-18 0
-
大数据时代数据库-云HBase架构&生态&实践2018-05-29 0
-
企业打开云HBase的正确方式,来自阿里云云数据库团队的解读2018-05-31 0
-
浅析对象数据库和NoSQL2019-05-27 0
-
使用NoSQL数据库的原因2019-05-27 0
-
关系型数据库与非关系数据库的区别浅析2019-06-03 0
-
hbase数据库方法2019-09-18 0
-
Hbase分布式非关系型数据库安装部署步骤2019-09-19 0
-
最新国产数据库排名2021-07-28 0
-
一款基于Java实现的小巧而强大的关系型数据库2021-10-27 0
-
HarmonyOS数据库的相关资料下载2022-03-28 0
-
HarmonyOS关系型数据库和对象关系数据库的使用方法2022-03-29 0
全部0条评论

快来发表一下你的评论吧 !
