

机器学习与数据挖掘的关系
人工智能
描述
在大多数非计算机专业人士以及部分计算机专业背景人士眼中,机器学习(Data Mining)以及数据挖掘(Machine Learning)是两个高深的领域。在笔者看来,这是一种过高”瞻仰“的习惯性错误理解(在这里我加了好多定语)。事实上,这两个领域与计算机其他领域一样都是在融汇理论和实践的过程中不断熟练和深入,不同之处仅在于渗透了更多的数学知识(主要是统计学),在后面的文章中我会努力将这些数学知识以一种更容易理解的方式讲解给大家。本文从基本概念出发浅析他们的关系和异同,不讲具体算法和数学公式。希望对大家能有所帮助。
一、概念定义
机器学习(Machine Learning,ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。其专门研究计算机是怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。
数据挖掘是从海量数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。数据挖掘中用到了大量的机器学习界提供的数据分析技术和数据库界提供的数据管理技术。
学习能力是智能行为的一个非常重要的特征,不具有学习能力的系统很难称之为一个真正的智能系统,而机器学习则希望(计算机)系统能够利用经验来改善自身的性能,因此该领域一直是人工智能的核心研究领域之一。在计算机系统中,“经验”通常是以数据的形式存在的,因此,机器学习不仅涉及对人的认知学习过程的探索,还涉及对数据的分析处理。实际上,机器学习已经成为计算机数据分析技术的创新源头之一。由于几乎所有的学科都要面对数据分析任务,因此机器学习已经开始影响到计算机科学的众多领域,甚至影响到计算机科学之外的很多学科。机器学习是数据挖掘中的一种重要工具。然而数据挖掘不仅仅要研究、拓展、应用一些机器学习方法,还要通过许多非机器学习技术解决数据仓储、大规模数据、数据噪声等实践问题。机器学习的涉及面也很宽,常用在数据挖掘上的方法通常只是“从数据学习”。然而机器学习不仅仅可以用在数据挖掘上,一些机器学习的子领域甚至与数据挖掘关系不大,如增强学习与自动控制等。所以笔者认为,数据挖掘是从目的而言的,机器学习是从方法而言的,两个领域有相当大的交集,但不能等同。
二、关系与区别
关系:数据挖掘可以认为是数据库技术与机器学习的交叉,它利用数据库技术来管理海量的数据,并利用机器学习和统计分析来进行数据分析。其关系如下图:
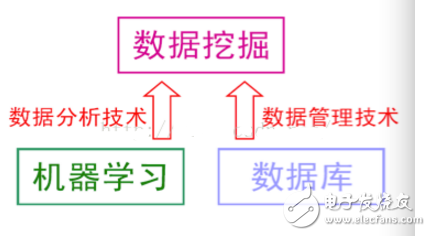
数据挖掘受到了很多学科领域的影响,其中数据库、机器学习、统计学无疑影响最大。粗糙地说,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学界往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。
区别:数据挖掘并非只是机器学习在工业上的简单应用,他们之间至少包含如下两点重要区别:
1.传统的机器学习研究并不把海量数据作为处理对象,因此,数据挖掘必须对这些技术和算法进行专门的、不简单的改造。
2.作为一个独立的学科,数据挖掘也有其独特的东西,即:关联分析。简单地说,关联分析就是希望从数据中找出“买尿布的人很可能会买啤酒”这样看起来匪夷所思但可能很有意义的模式。
几个相关示例
首先,给大家列举一些生活中与数据挖掘、机器学习相关的应用示例以帮助大家更好的理解。
示例1(关联问题):
经常去超市的同学可能会发现,我们事先在购物清单上列举好的某些商品可能会被超市阿姨摆放在相邻的区域。例如, 面包柜台旁边会摆上黄油、面条柜台附近一定会有老干妈等等。这样的物品摆放会让我们的购物过程更加快捷、轻松。
那么如何知道哪些物品该摆放在一块?又或者用户在购买某一个商品的情况下购买另一个商品的概率有多大?这就要利用关联数据挖掘的相关算法来解决。
示例2(分类问题):
在嘈杂的广场上,身边人来人往。仔细观察他们的外貌、衣着、言行等我们会不自觉地断论这个人是新疆人、东北人或者是上海人。又例如,在刚刚结束的2015NBA总决赛中,各类权威机构会大量分析骑士队与勇士队的历史数据从而得出骑士队或者勇士队是否会夺冠的结论。
在上述第一个例子中,由于地域众多,在对人进行地域分类的时候这是一个典型的多分类问题。而在第二个例子中各类机构预测勇士队是否会战胜骑士队夺冠,这是一个二分类问题,其结果只有两种。二分类问题在业界的出镜率异常高,例如在推荐系统中预测一个人是否会买某个商品、其他诸如地震预测、火灾预测等等。
示例3(聚类问题):
”物以类聚,人以群分“,生活中到处都有聚类问题的影子。假设银行拥有若干客户的历史消费记录,现在由于业务扩张需要新增几款面对不同人群的理财产品,那么如何才能准确的将不同的理财产品通过电话留言的方式推荐给不同的人群?这便是一个聚类问题,银行一般会将所有的用户进行聚类,有相似特征的用户属于同一个类别,最后将不同理财产品推荐给相应类别的客户。
示例4(回归问题):
回归问题或者称作预测问题同样也是一个生活中相当接地气的应用。大家知道,证券公司会利用历史数据对未来一段时间或者某一天的股票价格走势进行预测。同样,房地产商也会根据地域情况对不同面积楼层的房产进行定价预测。
上述两个示例都是回归问题的典型代表,这类问题往往根据一定的历史数据对某一个指定条件下的目标预测一个实数值。
相信经过上面通俗易懂的示例,大家应该初步了解数据挖掘以及机器学习会应用到哪些问题之上(这里列举的四类问题是很常见的,当然还有例如异常检测等应用),这就解决了面对一个新问题三要素中的Why。下面解释什么是机器学习与数据挖掘(即What)以及他们的关系和异同点。
-
【成都】招聘机器学习/数据挖掘/信号与信息处理工程师(可实习)2017-08-18 0
-
深度学习与数据挖掘的关系2018-07-04 0
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 0
-
人工智能、机器学习、数据挖掘有什么区别2020-05-14 0
-
机器学习与数据挖掘方法和应用2023-09-26 0
-
机器学习与数据挖掘的关系2018-01-05 10447
-
关于机器学习的前世今生和怎么用机器学习的方法去解决问题2018-05-18 1950
-
《机器学习与数据挖掘:方法和应用》2018-06-27 664
-
机器学习和数据挖掘的关系2022-06-29 4884
-
机器学习与数据挖掘的对比与区别2023-08-17 1158
-
python数据挖掘与机器学习2023-08-17 888
-
数据挖掘和机器学习有什么关系2023-08-17 2069
-
数据挖掘和机器学习之间的关系2023-08-17 2330
-
数据挖掘与机器学习专业就业方向2023-08-17 1213
-
机器学习与数据挖掘的区别 机器学习与数据挖掘的关系2023-08-17 1529
全部0条评论

快来发表一下你的评论吧 !
