

hbase协处理器概念及知识点总结
处理器/DSP
描述
HBase是一种Hadoop数据库,经常被描述为一种稀疏的,分布式的,持久化的,多维有序映射,它基于行键、列键和时间戳建立索引,是一个可以随机访问的存储和检索数据的平台。HBase不限制存储的数据的种类,允许动态的、灵活的数据模型,不用SQL语言,也不强调数据之间的关系。HBase被设计成在一个服务器集群上运行,可以相应地横向扩展。
HBase使用场景和成功案例
互联网搜索问题:爬虫收集网页,存储到BigTable里,MapReduce计算作业扫描全表生成搜索索引,从BigTable中查询搜索结果,展示给用户。
抓取增量数据:例如,抓取监控指标,抓取用户交互数据,遥测技术,定向投放广告等
内容服务
信息交互
入门
1、API
和数据操作有关的HBase API有5个,分别是 Get(读),Put(写),Delete(删),Scan(扫描)和Increment(列值递增)
2、操作表
首先要创建一个configuration对象
Configuration conf = HBaseConfiguration.create();
使用eclipse时的话还必须将配置文件添加进来。
conf.addResource(new Path(“E:\\share\\hbase-site.xml”));
conf.addResource(new Path(“E:\\share\\core-site.xml”));
conf.addResource(new Path(“E:\\share\\hdfs-site.xml”));
使用连接池创建一张表。
HTablePool pool = new HTablePool(conf,1);
HTableInterface usersTable = pool.getTable(“users”);
3、写操作
用来存储数据的命令是put,往表里存储数据,需要创建Put实例。并制定要加入的行
Put put = new Put(byte[] row) ;
Put的add方法用来添加数据,分别设定列族,限定符以及单元格的指
put.add(byte[] family , byte[] qualifier , byte[] value) ;
最后提交命令给表
usersTable.put(put);
usersTable.close();
修改数据,只需重新提交一次最新的数据即可。
HBase写操作的工作机制:
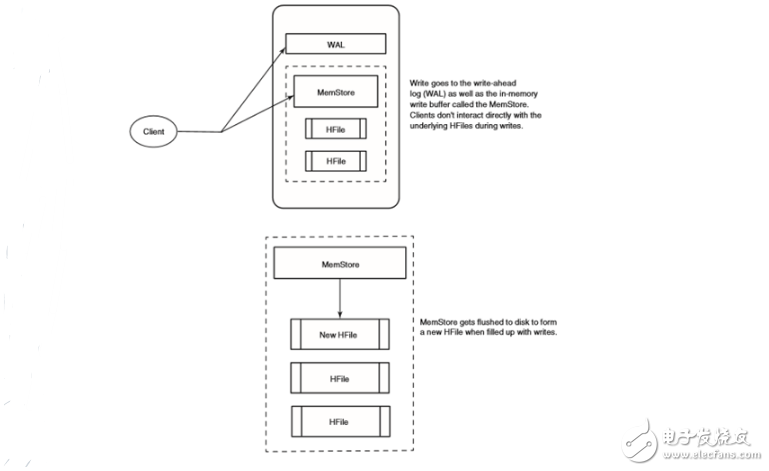
HBase每次执行写操作都会写入两个地方:预写式日志(write-ahead log,也称HLog)和MemStore(写入缓冲区),以保证数据持久化,只有当这两个地方的变化信息都写入并确认后,才认为写动作完成。MemStore是内存里的写入缓冲区,HBase中数据在永久写入硬盘之前在这里累积,当MemStore填满后,其中的数据会刷写到硬盘,生成一个HFile。
4、读操作
创建一个Get命令实例,包含要查询的行
Get get = new Get(byte[] row) ;
执行addColumn()或addFamily()可以设置限制条件。
将get实例提交到表会返回一个包含数据的Result实例,实例中包含行中所有列族的所有列。
Result r = usersTable.get(get) ;
可以对result实例检索特定的值
byte[] b = r.getValue(byte[] family , byte[] qualifier) ;
工作机制:
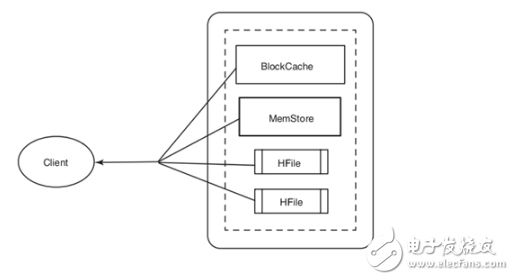
BlockCache用来保存从HFile中读入内存的频繁访问的数据,避免硬盘读,每个列族都有自己的BlockCache。从HBase中读出一行,首先会检查MemStore等待修改的队列,然后检查BlockCache看包含该行的Block是否最近被访问过,最后访问硬盘上的对应HFile。
5、删除操作
创建一个Delete实例,指定要删除的行。
Delete delete = new Delete(byte[] row) ;
可以通过deleteFamily()和deleteColumn()方法指定删除行的一部分。
6表扫描操作
Scan scan = new Scan() 可以指定起始行和结束行。
setStartRow() , setStopRow() , setFilter()方法可以用来限制返回的数据。
addColumn()和addFamily()方法还可以指定列和列族。
HBase模式的数据模型包括:
表:HBase用表来组织数据。
行:在表里,数据按行存储,行由行键唯一标识。行键没有数据类型,为字节数组byte[]。
列族:行里的数据按照列族分组,列族必须事先定义并且不轻易修改。表中每行拥有相同的列族。
列限定符:列族里的数据通过列限定符或列来定位,列限定符不必事先定义。
单元:存储在单元里的数据称为单元值,值是字节数组。单元由行键,列族或列限定符一起确定。
时间版本:单元值有时间版本,是一个long类型。
一个HBase数据坐标的例子:
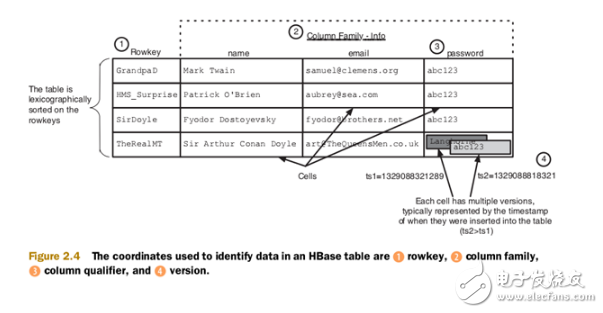
HBase可以看做是一个键值数据库。HBase的设计是面向半结构化数据的,数据记录可能包含不一致的列,不确定大小等。
三、分布式的HBase、HDFS和MapReduce
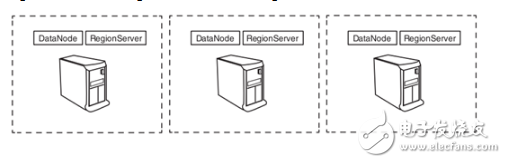
1、分布式模式的HBase
HBase将表会切分成小的数据单位叫region,分配到多台服务器。托管region的服务器叫做RegionServer。一般情况下,RgionServer和HDFS DataNode并列配置在同一物理硬件上,RegionServer本质上是HDFS客户端,在上面存储访问数据,HMaster分配region给RegionServer,每个RegionServer托管多个region。
HBase中的两个特殊的表,-ROOT-和.META.,用来查找各种表的region位置在哪。-ROOT-指向.META.表的region,.META.表指向托管待查找的region的RegionServer。
一次客户端查找过程的3层分布式B+树如下图:
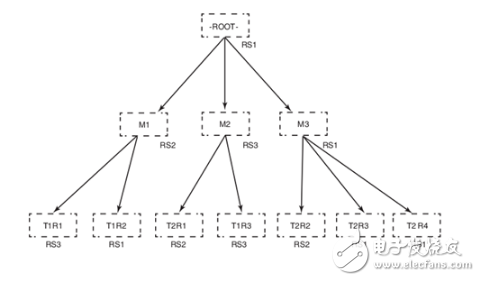
HBase顶层结构图:
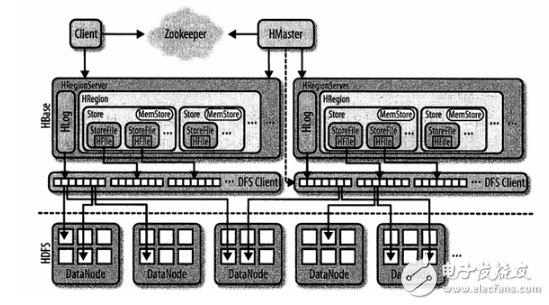
zookeeper负责跟踪region服务器,保存root region的地址。
Client负责与zookeeper子集群以及HRegionServer联系。
HMaster负责在启动HBase时,把所有的region分配到每个HRegion Server上,也包括-ROOT-和.META.表。
HRegionServer负责打开region,并创建对应的HRegion实例。HRegion被打开后,它为每个表的HColumnFamily创建一个Store实例。每个Store实例包含一个或多个StoreFile实例,它们是实际数据存储文件HFile的轻量级封装。每个Store有其对应的一个MemStore,一个HRegionServer共享一个HLog实例。
一次基本的流程:
a、 客户端通过zookeeper获取含有-ROOT-的region服务器名。
b、 通过含有-ROOT-的region服务器查询含有.META.表中对应的region服务器名。
c、 查询.META.服务器获取客户端查询的行键数据所在的region服务器名。
d、 通过行键数据所在的region服务器获取数据。
HFile结构图:
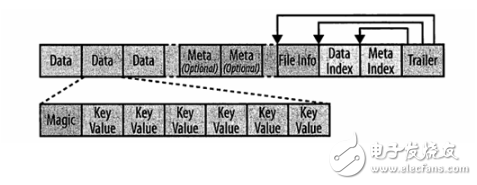
Trailer有指向其他块的指针,Index块记录Data和Meta块的偏移量,Data和Meta块存储数据。默认大小是64KB。每个块包含一个Magic头部和一定数量的序列化的KeyValue实例。
KeyValue格式:
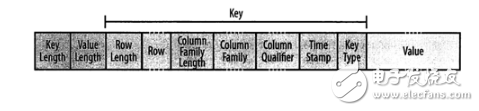
该结构以两个分别表示键长度和值长度的定长数字开始,键包含了行键,列族名和列限定符,时间戳等。
预写日志WAL:
每次更新都会写入日志,只有写入成功才会通知客户端操作成功,然后服务器可以按需自由地批量处理或聚合内存中的数据。
编辑流在memstore和WAL之间分流的过程:
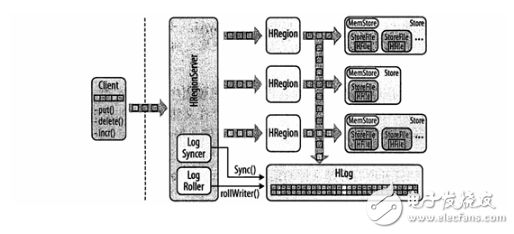
处理过程:客户端通过RPC调用将KeyValue对象实例发送到含有匹配region的HRegionServer。接着这些实例被发送到管理相应行的HRegion实例,数据被写入到WAL,然后被放入到实际拥有记录的存储文件的MemStore中。当memstore中的数据达到一定的大小以后,数据会异步地连续写入到文件系统中,WAL能保证这一过程的数据不会丢失。
1、为什么引入协处理器?
在旧版(0.92HBase版本之前)的HBase中是没有引入协处理器的概念的。这样存在的问题是:创建二级索引较难,很难进行简单的排序、求和、计数等操作。这里是指在该版本限制下难以进行上述操作,不是不行。为了降低难度,提出了协处理器的概念。
这里补充索引相关的知识点:
索引的概念:
i)明确是针对数据库而言的,体现是一张表或者一种数据结构,一列或者多列,目的是用来快速访问数据库中的信息。包含的内容是:键的属性值和存储文件位置信息的指针。
ii)主索引:
主索引是包含两个定长字段的有序文件。字段1:主键;字段2:磁盘块的指针。 这两个字段的值是索引项的值。
ii)二级索引
二级索引的概念:
“二级索引也是有两个字段的有序文件:
第一个字段是索引字段,有相同的数据类型,并且是数据文件中的非排序字段,
第二个字段可以是一个块指针也可以是记录指针。二级索引(也称为非聚簇索引)用于在二级键上搜索文件,二级索引的搜索键指定了一个顺序,这个顺序与文件的排序顺序不同。”
2、协处理器的特性是什么?
允许用户执行region级的操作,使用类似触发器的功能
允许扩展现有的RPC协议引入自己的调用
提供一个非常灵活的、可用于建立分布式服务的数据模型
能够自动化扩展、负载均衡、应用请求路由
3.协处理器的使用场景:
维护辅助索引;维护数据间的应用完整性。
4.协处理器框架提供了两大类Observer、endPoint(以下是参考HBase权威指南第三版)
通过继承这两大类来扩展自己的功能。
1)Observer(观察者)
该类是与RDMS中的触发器类似。回调函数在一些特定的事件发生时被调用。
事件包括:用户产生的事件或者服务端内部产生的事件。
协处理器框架提供的接口如下:
a、RegionObserver:用户可以通过这种处理器来处理数据修改事件,它们与表的Region紧密关联。region级的操作。对应的操作是:put/delete/scan/get
b、MasterObserver:可以用作管理或DDL类型的操作,是集群级的操作。对应的操作是:创建、删除、修改表。
c、WALObserver:提供控制WAL的钩子函数。
Observer定义好钩子函数,服务端可以调用。
2)endPoint
该类的功能类似RDMS中的存储过程。将用户的自定义操作添加到服务器端,endPoint可以通过添加远程过程调用来扩展RPC协议。用户可以将自定义完成某项操作代码部署到服务器端。例如:服务器端的计算操作。
当二者结合使用可以决定服务器端的状态。
5、Coprocessor类
所有的协处理器都必须实现给接口,该接口定义了协处理器的基本约定和易于框架管理,并且定义协处理器的执行的优先级别。
1)协处理器的执行顺序
Coprocessor.Priority枚举类型定义了两个值:SYSTEM、USER。前者优于后者执行,后者定义的按顺序执行。
2)协处理器的生命周期
协处理器的生命周期是由框架管理的,接口定义两个方法start、stop。这两个方法的参数是:CoprocessorEnvironment。该类提供了访问HBase的版本、Coprocessor版本、协处理器优先级等方法。start/stop方法是被隐式调用的,且关于协处理器的状态的定义是有一个枚举类Coprocessor.State对应的。
3)协处理器环境和实例的维护
CoprocessorHost类来完成,其有相应的子类来完成维护region、master协处理器的实例和环境。
总结:Coprocessor、CoprocessorEnvironment、CoprocessorHost是三个类,在该三个类的基础上进行扩展功能,完成支持、管理、维护协处理器。
6、协处理器的加载/部署
在加载处理器的方式上有两种方式:1.通过配置文件静态加载 2.在集群运行时动态加载(在权威指南第三版中指出尚未有动态加载的API)。
1) 对于静态加载的方式
在HBase权威指南中P171页指出,在此不再赘述,是搬砖的苦力活。其中需要强调的是书中“配置文件中配置项的顺序非常重要,这个顺序决定了执行顺序”
2)特定表加载处理器是归属于静态加载的方式
对于特定表的协处理器加载是通过表描述符。所以该处理器的加载只针对该表的region,同时被服务端的region和region server调用,不能被master或WAL调用。在HBase权威指南的P173给出示例。
7、RegionObserver类
该类的描述:1.RegionObserver类是Observer类的子类2.明确是在响应region级别的操作。当region事件发生时,其定义的钩子函数被调用。该级别的操作可以分为两类:region生命周期变化或客户端API调用。
1)处理region生命周期事件
这里的生命周期事件体现的是region的状态变化,而触发器处理的时间发生在是状态变化的前、后。
下面是不同的状态的前后可以定义的协处理器(这里的协处理器就是指可以进行的操作):
状态1:pendingOpen,region将要被打开的状态。
协处理器以实现的方法是:
preOpen()/postOpen()。完成功能是:搭载或者阻止这次打开过程。
preWALRestore()/postWALRestore.完成的功能是:用户可以访问那些记录被修改了,监督那些记录被实施了。
状态2:open,这个状态的标志是:region被部署到一个region server上且正常工作时。
协处理器可以实现的方法是:
void preFlush()/void postFlush() 内存被持久到磁盘
void preSpilt()/void postSpilt() region达到足够大时进行拆分
状态3:pendingClose。region将要被关闭时的状态。
协处理器可以实现的方法是:
void preClose()/void postClose()
2)处理客户端API事件
这里是指在调用Java API 时,响应的事件。如:
void prePut()/void postPut、void preDelete()/postDelete()、void preGet()/void postGet()。。。。。。。。
3)RegionCoprocessorEnvironment类
实现RegionObserver类的协处理器环境类是基于RegionCoprocessorEnvironment类的,通过该类可以访问管理Region实例和共享RegionServerService实例
4)ObserverContext
RegionObserver类提供的所有回调函数都需要一个特殊的上下文作为共同参数。ObserverContext类提供了访问当前系统环境的入口,同时也添加一些关键功能用以通知协处理器框架在回到函数完成后需要做什么。讲解了byPass()/complete()方法,前者会停止当前服务进程处理过程,后者影响后面执行的协处理器。
5)BaseRegionObserver类
该类的作用是:可以作为实现所有监听类型协处理器的基类。需要注意的是要想实现自定义的功能必须重载这个类的方法。
8、MasterObserver类
协处理器定义明确为master服务器的所有回调函数。这些回调函数中的操作是类似DDL,创建、删除、修改表。
1)MasterCoprocessorEnvironment
MasterCoprocessorEnvironment封装了MasterObserver实例,通过该类可以访问MasterService实例。
2)BaseMasterServer
BaseMasterServer是MasterServer的空实现,可以通过实现相应的pre/post来自定义相关操作。 例如: void preCreateTable()/void postCreateTable() void preDeleteTable()/void postDeleteTable()。。。。。。
9、endPoint
提出endPoint原因?
CoprocessorProtocol接口
该接口可以使用户自定义RPC协议,它的实现代码被安装在服务端,在客户端HTable提供调用方法,使用该协议可以和协处理器实例之间通信。
-
NFC技术基础知识点总结的太棒了2021-05-21 0
-
关于图像处理器6538与8031的接口技术的知识点你想知道的都在这2021-06-03 0
-
自动控制原理知识点总结题型2021-07-12 0
-
单片机原理及应用知识点总结2021-07-14 0
-
微型计算机原理及应用知识点总结2021-07-16 0
-
单片机的知识点总结2021-07-21 0
-
关于C++的知识点总结的太棒了2021-10-11 0
-
关于电机与拖动的知识点总结的太棒了2021-10-20 0
-
C语言程序小知识点总结2021-11-05 0
-
UCOSIII的基础知识点汇总,总结的太棒了2021-11-30 0
-
关于程序变量和内存分配的知识点总结2022-02-28 0
-
高一数学知识点总结2016-02-23 658
-
高二数学知识点总结2016-02-23 633
-
嵌入式知识点总结2021-07-30 866
-
数字信号处理知识点总结2022-08-15 489
全部0条评论

快来发表一下你的评论吧 !
