

基于matlab的文字识别算法
matlab实验
描述
前言
从图像中提取文字属于信息智能化处理的前沿课题,是当前人工智能与模式识别领域中的研究热点。由于文字具有高级语义特征,对图片内容的理解、索引、检索具有重要作用,因此,研究图片文字提取具有重要的实际意义。又由于静态图像文字提取是动态图像文字提取的基础,故着重介绍了静态图像文字提取技术。
随着计算机科学的飞速发展,以图像为主的多媒体信息迅速成为重要的信息传递媒介,在图像中,文字信息(如新闻标题等字幕) 包含了丰富的高层语义信息,提取出这些文字,对于图像高层语义的理解、索引和检索非常有帮助。
图像文字提取又分为动态图像文字提取和静态图像文字提取两种,其中,静态图像文字提取是动态图像文字提取的基础,其应用范围更为广泛,对它的研究具有基础性,所以本文主要讨论静态图像的文字提取技术。静态图像中的文字可分成两大类: 一种是图像中场景本身包含的文字, 称为场景文字; 另一种是图像后期制作中加入的文字, 称为人工文字,如右图所示。场景文字由于其出现的位置、小、颜色和形态的随机性, 一般难于检测和提取;而人工文字则字体较规范、大小有一定的限度且易辨认,颜色为单色, 相对与前者更易被检测和提取, 又因其对图像内容起到说明总结的作用,故适合用来做图像的索引和检索关键字。对图像中场景文字的研究难度大,目前这方面的研究成果与文献也不是很丰富,本文主要讨论图像中人工文字提取技术。
静态图像中文字的特点
静态图像中文字(本文特指人工文字,下同)具有以下主要特征:
(1)文字位于前端,且不会被遮挡;
(2)文字一般是单色的;
(3)文字大小在一幅图片中固定,并且宽度和高度大体相同,从满足人眼视觉感受的角度来说,图像中文字的尺寸既不会过大也不会过小;
(4)文字的分布比较集中;
(5)文字的排列一般为水平方向或垂直方向;
(6)多行文字之间,以及单行内各个字之间存在不同于文字区域的空隙。在静态图片文字的检测与提取过程中, 一般情况下都是依据上述特征进行处理的。
数字图象处理
静态图像文字提取一般分为以下步骤:文字区域检测与定位、文字分割与文字提取、文字后处理。其流程如图所示。
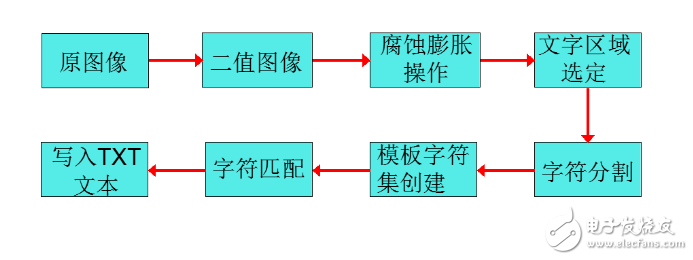
文字提取、识别的详细步骤
1. 在Matlab中调用i1=imread(‘字符.jpg’),可得到原始图像,如图所示:
2. 调用i2=rgb2gray(i1),则得到了灰度图像,如图所示:
调用a=size(i1);b=size(i2);可得到:a=3,b=2 即三维图像变成了二维灰度图像
3. 调用i3=(i2》=thresh);其中thresh为门限,
图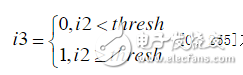 之间这里,
之间这里, 
得到二值图像,如图所示:

4. 把二值图像放大观察,可看到离散的黑点 对其采用腐蚀膨胀处理,得到处理后的图像,如图所示

可见,腐蚀膨胀处理后的图像质量有了很大的改观。 横向、纵向分别的腐蚀膨胀运算比横向、纵向同时的腐蚀膨胀运算好上很多,图6可看出差别:

5、对腐蚀膨胀后的图像进行Y方向上的区域选定,限定区域后的图像如图所示: 扫描方法:中间往两边扫

纵向扫描后的图像与原图像的对照,如图8所示:

6、对腐蚀膨胀后的图像进行X方向上的区域选定,限定区域后的图像如图9所示: 扫描方法:两边往中间扫

纵向扫描后的图像与原图像的对照,如图所示:

7. 调用i8=(iiXY~=1),使背景为黑色(0),字符为白色(1),便于后期处理。 背景交换后的图像如图11所示:
8. 调用自定义函数(字符获取函数)i9=getchar(i8),得到图像如图所示:
9、调用自定义的字符获取函数对图像进行字符切割,并把切割的字符装入一维阵列,切割 过程如图12所示:
10.调用以下代码,可将阵列word中的字符显示出来,如图13所示:
for j=1:cnum %cnum为统计的字符个数
subplot(5,8,j),imshow(word{j}),title(int2str(j)); %显示字符
end
可以看到,字符宽度不一致
11. 调用以下代码,将字符规格化,便于识别: for j=1:cnum word{j}=imresize(word{j},[40 40]); %字符规格化成40×40的 end 得到规格化之后的字符如图14所示:
12. 调用以下代码创建字符集:
code=char(‘由于作者水平有限书中难免存在缺点和疏漏之处恳请读批评指正,。’);
将创建的字符集保存在一个文件夹里面,以供匹配时候调用,如图15所示:
13. 字符匹配采用模板匹配算法:将现有字符逐个与模板字符相减,认为相减误差最小的现 有字符与该模板字符匹配。

也就是说,字符A与模板字符T1更相似,我们可以认为字符集中的字符T2就是字符A。 经模板匹配,可得字符信息如下: 由于读者书评有限书中难免存在缺点和纰漏之处,恳请读者批评指正。 效果如图16所示:

14、调用以下代码,将字符放入newtxt.txt文本:
new=[‘newtxt’,‘.txt’]; c=fopen(new,‘a+’); fprintf(c,‘%s ’,Code(1:cnum)); fclose(c); newtxt.txt文本内容如图17所示:

总结
1、算法具有局限性。对于左右结构的字符(如:川)容易造成误识别,“川”字将会被识别成三部分。当图片中文字有一定倾斜角度时,这将造成识别困难。
2、模板匹配效率低。对于处理大小为m×m的字符,假设有n个模板字符,则识别一个字符至
少需要m×m×n×2次运算,由于汉字有近万个,这将使得运算量十分巨大!此次字符识 别一共花了2.838秒。
3、伸缩范围比较小。对于受污染的图片,转换成二值图像将使字符与污染源混合在一起。
对于具体的图片,需反复选择合适的thresh进行二值化处理,甚至在处理之前必须进行各种滤波。
- 相关推荐
- matlab
-
众家兄弟姐妹,用MATLAB软件编程对银行印章识别自动算法...2013-04-25 0
-
《MATLAB优化算法案例分析与应用》2014-10-10 0
-
【超值干货】 揭秘车牌识别算法2017-05-25 0
-
基于SnapDragonBoard410C文字识别2018-09-26 0
-
Matlab-LMS算法演示2021-08-17 0
-
基于AI通用文字识别能力,检测和识别文档翻拍、街景翻拍等图片中的文字2021-08-27 0
-
怎样通过Matlab-LMS算法去进行系统识别呢2021-11-19 0
-
用ocr识别文字表格后,格式内容很乱,有没有什么算法可恢复成原有的数据结构?2022-08-26 0
-
指纹识别matlab源代码2016-01-20 1158
-
车牌识别-matlab2016-06-16 894
-
Android文字识别2016-12-20 807
-
BP算法及其matlab实现2017-12-02 460
-
如何使用MATLAB进行语音识别算法研究的论文资料免费下载2018-12-21 1422
-
浅析HarmonyOS基于AI的通用文字识别技术2021-08-20 2853
-
基于MATLAB的遗传算法2022-09-30 459
全部0条评论

快来发表一下你的评论吧 !
