

深度学习如何确定最佳深度?
工业控制
描述
确定最佳深度可以降低运算成本,同时可以进一步提高精度。针对深度置信网络深度选择的问题,文章分析了通过设定阈值方法选择最佳深度的不足之处。从信息论的角度,验证了信息熵在每层玻尔兹曼机(RBM)训练达到稳态之后会达到收敛,以收敛之后的信息熵作为判断最佳层数的标准。通过手写数字识别的实验发现该方法可以作为最佳层数的判断标准。
*基金项目: 福建省自然科学基金资助项目(2014J01234);福建省教育厅基金资助项目(JA15061)
人工神经网络是从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。2006年之前,多数的分类、回归等学习方法通常都只是包含一层隐藏层的浅层学习模型,其局限性在于在有限样本和计算单元情况下对复杂函数的表示能力有限。在2006年,多伦多大学的Hinton教授提出的深度信念网络(Deep Belief Network,DBN)的深度学习,使得人工神经网络又掀起了另一次浪潮。传统的浅层神经网络随机初始化网络中的权值,容易出现收敛到局部最小值。针对这一问题,Hinton教授提出使用无监督训练的方法先初始化权值,再通过反向微调权值的方法来确定权值从而达到更好的效果。除此之外,Mikolov提出的基于时间的深度神经网络(Recurrent Neural Network,RNN)主要用于序列数据的预测,有一定的记忆效应。而之后对于DBN的研究又扩展了一些其他的变种,比如卷积深度置信网络(Convolutional Deep Belief Networks,CDBN)等。
目前深度学习在语音识别、计算机视觉等领域已经取得了巨大的成功。
但是对于深度学习的研究是近些年才开始的,建模问题是其中的关键问题之一,如何针对不同的应用构建合适的深度模型是一个很有挑战性的问题。DBN目前在应用中依然使用经验值法来判断DBN所选用的层数及其节点数,研究发现增加DBN的层数到一定的峰值之后,再次增加DBN的层数并不能提升系统性能,反而导致训练的时间过长,从而增加了计算成本。
近年来针对DBN层数的确定已经有了一些初步的进展,其中高强利用中心极限定理证明了在受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)训练达到稳态后对应的权值系数矩阵元素服从正态分布,随着层数的增加,权值系数矩阵越来越趋于正态分布,以权值权重最趋近于正态分布的程度作为确定深度信念网络层数的依据,通过求出正态分布满足率来选择合适的层数。潘广源等人利用设定重构误差的阈值来确定层数,在重构误差未达到这个阈值时则增加一层,虽然重构误差能够在一定程度上反映RBM对训练数据的似然度,不过并不完全可靠。可以看出现在的方法基本上是设定一个阈值来进行判断,这样的做法可能会导致虽然达到了阈值但是效果并不是很好的情况。综合上述情况,本文提出利用在RBM训练达到稳态后通过计算隐藏层的信息熵来判断最佳层数,当增加一层RBM后,信息熵也会增加,当信息熵不再增加时则选取该层作为最佳层数。
1深度信念网络层数的确定
2006年,Hinton等人提出了深度置信神经网络,该模型是通过若干个RBM叠加而成。RBM是一个两层模型,分别为可见层和隐藏层,RBM的训练方法为首先随机初始化可见层,然后在可见层和隐藏层之间进行Gibbs采样,通过可见层用条件概率分布P(h|v)来得到隐藏层,之后同样利用P(v|h)来计算可见层,重复该过程使得可见层与隐藏层达到平衡,训练RBM网络的目标是使得计算后的可见层的分布最大可能地拟合初始可见层的分布。而以训练数据为初始状态,根据RBM的分布进行一次Gibbs采样后所获得样本与原数据的差异即为重构误差。
引入了RBM的训练精度随着深度的增加而提高,并且证明了重构误差与网络能量正相关,之后对重构误差的值设定一个阈值,如果没有达到该阈值则增加一层;如果达到该阈值则取该层为最佳层数。通过最后的实验可以发现,虽然选取第4层为最佳层数,但重构误差在第5层和第6层依然在降低,如果阈值选取得不好,虽然重构误差能够满足阈值的条件,但是选择的层数得出的结构并不能取得很好的效果。
故本文提出利用稳定后的隐藏层的信息熵来判断最佳层数。通过信息论可知,信息熵的物理含义表示信源输出后,信息所提供的平均信息量,以及信源输出前,信源的平均不确定性,同时信息熵也可以说是系统有序化程度的一个度量,一个系统越是有序,信息熵则越低,反之信息熵越高。而训练RBM的目标是使得系统的能量函数越小,使系统越有序。所以在RBM训练完之后,信息熵将会收敛于一个较小值。
假设输入的矩阵为V=(v1,v2,v3,…,vi),经过RBM训练之后的输出矩阵为Y=(y1,y2,y3,…,yj),经过RBM的训练模型可以通过已知的可视节点得到隐藏节点的值,即:
P(Y)=S(WV+B)(1)
其中W为权重矩阵,B为偏置矩阵,S(x)为激活函数,一般选取Sigmoid函数,即:
信息熵的求解公式为:
根据Hinton提出的对比散度的算法[13],权重和偏置会根据下式进行更新:
wi,j=wi,j+[P(hi=1|V(0))v(0)j-P(hi=1|V(k))v(k)j](4)
bi=bi+[P(hi=1|V(0))-P(hi=1|V(k))](5)
当RBM训练到达终态后,则权值wi,j和偏置bi会逐渐收敛,而v是输入数据,是确定值,所以在训练达到终态后,p(yi)也会逐渐收敛,同样信息熵H(Y)会收敛于一个较小值。
当训练完一层之后,将隐藏层作为第2层的可见层输入并开始训练第2层RBM。根据信息熵的另一个物理含义平均信息量可知,在消除不确定性后,信息熵越大则表示所获得的信息量越多,则隐藏层对于抽取的特征信息量也越大。所以当信息熵不再增加时,所表示的信息量也不再增大,将每层的RBM看作为一个信源,则最后一层的RBM收敛之后信息熵应该比其他层的大,这样输入到有监督学习中的信息量才会最大。所以当信息熵不再增加时,则选择该层作为最佳层数。
2实验
本实验使用MATLAB进行仿真,数据库利用MNIST手写数字图片作为实验数据库,该数据库包含各种手写数字图片,同时也包含每一张图片对应的标签,以供机器学习进行监督学习的训练,已有很多不同模式识别技术(如KNN、SVM等)利用该数据库作为实验数据库,故该数据库是评估新方法的比较理想的方式。本实验将10 000个样本用于无监督学习。其中MNIST的图像为28×28的像素,所以第一层的输入为784个节点,之后每层神经元为100个节点。
通过MATLAB计算出信息熵,每次更新wi,j和bi后计算一次信息熵,由于有10 000个样本,而每次输入的均为100个样本,分100次进行输入,每一层的RBM训练都设定为50次的迭代次数。故需要迭代的次数为5 000次,每更新一次后计算出新的信息熵,第2层的信息熵如图1所示。可以看到当训练次数增加时,系统逐渐趋于稳定,信息熵逐渐下降并逐渐趋于收敛。
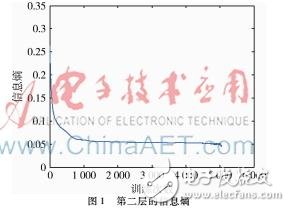
由于要达到平稳后信息熵最大才能使平均信息量最大,所以选取每层3 000次训练之后的信息熵,对这些信息熵求平均值,作为该层的信息熵。表1为不同深度的训练数据。通过表1可以看出,随着深度的增加,信息熵逐渐增加,在增加到第5层时,信息熵相比于第4层计算的信息熵有所下降,所以选择第4层作为最佳层数。通过表1可以看出,在第4层时误差率最低,而正确率最高。所以通过信息熵可以判断出最佳层数。

3结论
深度学习在各个方面都有着很好的应用前景,但是其中依然有着诸如建模问题等。本文针对深度置信网络(DBN)深度难以选择的问题进行分析,并且指出现有的阈值选择方法有可能在阈值选取不好时选取的层数并不是最佳层数。因此本文提出利用信息熵作为选择层数的选择标准,当信息熵没有明显增加时则选择该层作为最佳层数,通过实验发现可以选取到最佳层数,使得效果最好。本文只是针对深度的选择问题进行研究,而对于RBM依然有超参数的选择问题,下一步可以探究其他超参数的选取,从而进一步提高算法的收敛速度。
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 0
-
深度学习与数据挖掘的关系2018-07-04 0
-
什么是深度学习?2020-11-11 0
-
深度学习DeepLearning实战2021-01-09 0
-
深度强化学习实战2021-01-10 0
-
深度学习是什么2021-07-19 0
-
深度学习存在哪些问题?2021-10-14 0
-
深度学习模型是如何创建的?2021-10-27 0
-
深度学习介绍2022-11-11 0
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 0
-
深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解2018-08-23 992
-
深度学习算法简介 深度学习算法是什么 深度学习算法有哪些2023-08-17 6664
-
什么是深度学习算法?深度学习算法的应用2023-08-17 1437
-
深度学习框架是什么?深度学习框架有哪些?2023-08-17 1699
-
深度学习框架和深度学习算法教程2023-08-17 695
全部0条评论

快来发表一下你的评论吧 !
