

基于Linux进程管理的详细剖析
电子说
描述
上一篇嵌入式未来一段时间还是Linux天下,一位嵌入式er初探Linux kernel经验,我们讲到了Linux内核开发和应用程序开发,今天我们来讲讲Linux重点部分Linux的进程管理。
OS是干啥的?处理提供对硬件层的抽象以外,还担负着很多的硬件管理功能,而这些功能,用一句话来说,就是来处理各个部件的时空复用问题(时间和空间的重用问题,如cpu是分时重用的(当然还有多核cpu的特例,而内存是即分时又分空的……)。
往古至今,大牛们对OS的定义不下其数,而本人认为最有说服力的OS的定义就是:“所有软件(特指应用程序)的交集”,料想计算机诞生初期都是专用机,在一款机器上只能跑订制的专用程序,而这个程序要自己做好所有硬件的协调且还要完成他应有的本分工作,慢慢的计算机向通用型发展,为了提高系统利用率和避免盲目且重复的底层实现,OS随着需求一步步形成且不断完善……
不知你发现没有,好多东西都是在历史舞台上重复出现的,仿佛对应着“20年后又是一条好汉”这句话,看现在的google的Chrome OS,其实最初的原型说白了就是把chrome浏览器必要的底层重新从OS中剥离,使其具有独立运行的能力,这不是有点最早的专用机的味道,计算机这东西很是神奇,一个好的点子就可能改变整个市场,甚至一个世纪……
扯远了,重新回来,回到复用性说起吧,因为cpu要跑的程序很多,但是cup个数有限,这就牵扯到cpu的重用,也就是被多个进程重用(进程与程序的区别就不多说了,自己熟悉OS知识去吧,简单的提一下程序运行的本质就是从内核申请个进程,再把程序包中的代码拷贝到对应进程的代码域并设置好相关变量数据令进程跑起来,所以程序只是静态的代码,而进程是一个不断从程序加载代码的执行过程),这是由于进程间要复用cpu,所以就要求有人来负责他们有组织有纪律的复用,并协调进程间的轻重缓急、切换规则、切换后的一些处理……
另外还有怎样生产进程、怎样切换、怎样销毁……这些由谁完成?当然是OS,对于linux,当然是kernel了。毕竟OS就是用来跑程序的,而进程就是程序的灵魂,可见进程管理的重要性,咱就从进程说起先。
虽然吧,进程是处于执行期的程序,但是要明白,进程并不仅仅局限于一段可执行的代码,你想,要想跑进程,你得知道是谁的进程,要区别于其他进程;还要保证当前进程不能随意访问其他进程的地址空间,要是连这都不限制,那写个黑客程序多随意啊;还牵扯到多线程问题;另外,由于进程间是复用cpu的,就是一会儿这个执行,一会儿换另一个,那你还要保证它可以接着上次的执行啊,要不不就乱了套了……如此说来,进程需要的东西大概有:
打开的文件
挂起的信号 (linux一个事件的处发是基于信号机制的,就像windows的事件机制)
内核内部数据 (这就是传说中恢复现场用的,要还原到进程切换前的状态需要保存现场)
处理器状态 (没理解错的话,这也是现场保持的一部分,因为有些程序的执行是)
地址空间
一个或多个执行线程(Linux下的线程实现非常有趣,也非常简单,本质上也就是几个共享进程,没有设置专门的线程数据结构)
以上是Linux下进程的主要组成部分,当然了,进程管理么,有了进程还要有管理,管理相关着进程的策略和生命周期等一些东西,我们会慢慢讲来。
话说很久很久以前,进程自创建时刻起就开始存活了,活在Linux世界的进程爹fork()系统调用一下,就会生个小进程,比和女儿国的水来的还快。进程这东西没耳朵没眼睛的,他爹咋知道啥时候生好了。既然fork()是生婆,那这是生婆最懂了。fork()系统调用会返回两次:一次回到父进程,一次回到子进程。
新的进程是为了立即执行新的不同的程序,而接着调用exec*()这族函数就可以创建新的地址空间,并把新的程序载入。(fork()实际上是由clone()系统调用实现的。)
最终,程序会通过exit()系统调用退出执行。这个函数会终结进程并将其占用的资源释放。父进程会通过wait4()系统调用来查询子进程是否终结,这就使得进程拥有了等待特定进程执行的能力。进程退出后被设置为僵死状态,直到父进程调用wait()或waitpid()为止。
知道了进程不仅仅是由一段执行代码组成的,咱们就说说linux下的进程的大概过程。其实一个进程就相当于一个软件的动态执行(严格的说是某个软件子系统的动态执行,当然我们可以把该子系统想象成一个子软件,这样会便于理解)。Linux中创建一个进程要用到fork()系统调用,一个子进程的生成是通过拷贝父进程来实现的。fork以后,会返回两次:一次回到父进程,一次回到子进程。为何要返回两次,两次又是如何区别的呢??刚开始我也在像这个问题,因为子进程拷贝了父进程的代码,返回时处于fork()返回点的上下文是一样的,但是返回的值不一样,借此来区分是父进程还是子进程……
这不,新的子进程创建好了,然后干什么?肯定是做不是当前进程的工作,要不创建他干什么?所以,这时候就接着调用exec*()这一族函数,该族函数可以创建新的地址空间,并加载到当前进程执行。
最后,程序通过exit() syscall(系统调用,以后都用这个代指了) 退出执行。这个函数会终结进程并将其占用的资源释放掉。父进程通过wait4() syscall来查询子进程是否终结,这使得进程拥有了等待特定进程执行完的能力(这不就是传说中的同步么?有木有?有木有?哈哈)。进程退出后被设置为僵死状态,知道父进程调用wait()或waitpid()为止(其实他们貌似都是基于wait4()实现的)。
上面就是进程创建到回收的简单过程。子进程由父进程创建,父进程回收,有点恢复现场的感觉,不过在比较安全的系统里面,哪里都可以看的“恢复现场”等类似概念的身影,就像借钱一样,“好借好还再借不难”,做程序也是这个道理,哈哈,慢慢体会,编程里面蕴含很多的哲学道理的。
1、进程描述符及任务结构
在软件设计中,第一就是抽象名词,一切名词都会在计算机中找到它的数据抽象,就是伟大的数据结构童鞋。他可能被抽象成一个变量,一个数组,一个struct,一个对象……可能是任何一种类型,只要满足你的需求,他就是最perfect的抽象。
进程在kernel中是被放在任务队列(task list)中的,task list 是个双向循环链表。链表中的每一项都是task_struct类型,即进程描述符。定义在中,包含着一个具体进程的所有信息。
1.1 分配进程描述符
进程有的表达了,但是不能胡乱表达啊,就像追女朋友一样,不能见人就表白,那不成耍流氓了,名额有限,见好就收啊。OS能多道并跑的进程也就那几个,若肆意创建进程,不跑瘫了机子,那就变成病毒程序了,狂吃cpu。Linux使用slab分配器分配task_struct 结构。由slab动态生成task_struct,只需在栈底创建一个新的thread_info ,再用这个结构的数据可以容易的计算出偏移量。
其中包含了task_struct 的指针和进程的相关信息。
1.2 进程描述符的存放
Kernel通过PID唯一标识一个进程,PID是pid_t类型,其实也是int型的,pid最大值是32768 (short int 的Max 值)。可以改其值,在/proc/sys/kernel/pid_max 中,因为大公司的web服务器集群工作时32768个进程多开貌似不够啊。
内核在处理进程时一般是直接通过task_struct进程的,都是通过current宏直接找到或计算当前task_struct的。有的平台寄存器丰富,不用专门计算其值,一直把当前运行进程的值保存在专用的寄存器中就OK。如powerPC用r2寄存器,而x86寄存器少要专门计算。
1.3 进程状态
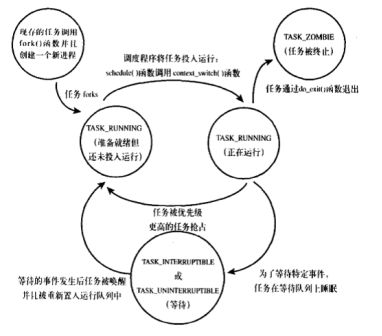
进程一直处于下面五种状态之一:
TASK_RUNNING//运行状态
TASK_INTERRUPTIBLE//可中断状态
TASK_UNINTRRUPTIBLE//不可中断状态
TASK_ZOMBIE//僵死
TASK_STOPPED//停止
下图是大概的转换过程。不很详细,大家可以search一下……
-
linux系统进程存在状态及管理2020-05-21 0
-
Linux的进程管理工具之Supervisor2020-06-12 0
-
Linux进程管理2009-04-28 338
-
Linux的进程管理2020-05-20 0
-
LINUX下的进程管理问题如何解决2020-05-20 0
-
Linux 2.6进程调度2009-06-13 430
-
Linux进程管理:什么是进程?进程的生命周期2019-02-15 7451
-
学会Linux进程管理的方法2019-05-16 674
-
简要剖析Linux系统的进程管理机制_LINUX_操作系统_脚本之家2019-04-02 447
-
Linux进程间通信方法之管道2022-05-14 1601
-
Linux开发_Linux下进程编程2022-09-17 1106
-
Linux进程是如何创建出来的?2022-11-15 442
-
Linux使用Systemd管理进程服务2022-12-12 339
-
深度剖析Linux中进程控制(上)2023-05-12 333
-
深度剖析Linux中进程控制(下)2023-05-12 327
全部0条评论

快来发表一下你的评论吧 !
