

AVA新技术让剧照清晰又好看
描述
电影、剧集等视频的创作、生产、分销等环节已经可以通过算法优化提升效率。Netflix的AVA平台可以自动的甄选最有代表性的剧照,从而针对不同人群推送最能打动观众的剧照。
在Netflix公司,无论是内容平台工程师团队,还是全球产品创意团队都知道,观众在寻找新的节目和电影观看时,封面插图扮演着非常重要的角色。我们可以透过封面插图,揭示故事的独特元素,而这些元素将我们的观众与不同的角色和故事线索联系起来。我们为此感到很自豪。随着我们的原创内容不断增多,我们的技术专家的任务是寻找新的方式来处理不多扩展的资源,并使我们的创意可以摆脱不断增长的令人厌烦的数字宣传需求。其中的一个方法是直接从我们的源视频中采集静态图像帧,以提供更加灵活的原始插图来源。
商业案例
宣传剧照是直接从源视频内容中获取的静态视频帧,用于扩大Netflix服务的标题范围。在一个一小时的新剧集中,有近86,000个静态视频帧。
通常来说,这些宣传剧照是由影片的策划人或编辑人工选择的,他们需要对打算呈现的源内容有深入的了解。通过A / B测试我们了解到,通过尽可能多地变换各种不同的标题,我们可以有效地推动预期和意外受众群体进行更多地观看。说到标题艺术,我们喜欢测试一个标题的许多艺术表现形式,以便为正确的观众找到“正确的”作品插图。虽然这为创新和测试提供了一个令人兴奋的机会,但它同时也提出了一个非常严峻的挑战,即在我们不断增长的全球内容目录中的每个标题上实践这种体验。
AVA
AVA是一个工具和算法的集合,旨在从我们服务的视频中提取高质量的图像。平均一个电视节目(约10集)包含近900万个总帧数。要求创意编辑们从许多视频帧中有效筛选出来一个能够吸引观众注意力的视频帧是乏味并且缺乏效率的。我们着手构建了一个工具,能够快速有效地识别Netflix服务上哪些帧能够最佳地表达主题和标题。
为了实现这个目标,我们首先提出了客观信号,它可以促使我们使用帧注解来衡量视频的每一帧。因此,我们可以收集视频的每个帧的有效表示。随后,我们创建了排序算法,使我们能够对符合审美、创意和多样性目标的视频帧子集进行排序,以准确地为我们产品的各种画面呈现内容。
由AVA提供的备选图像
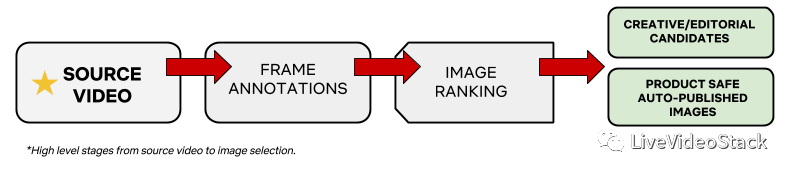
从源视频到编辑备选图像的高级阶段
帧注解
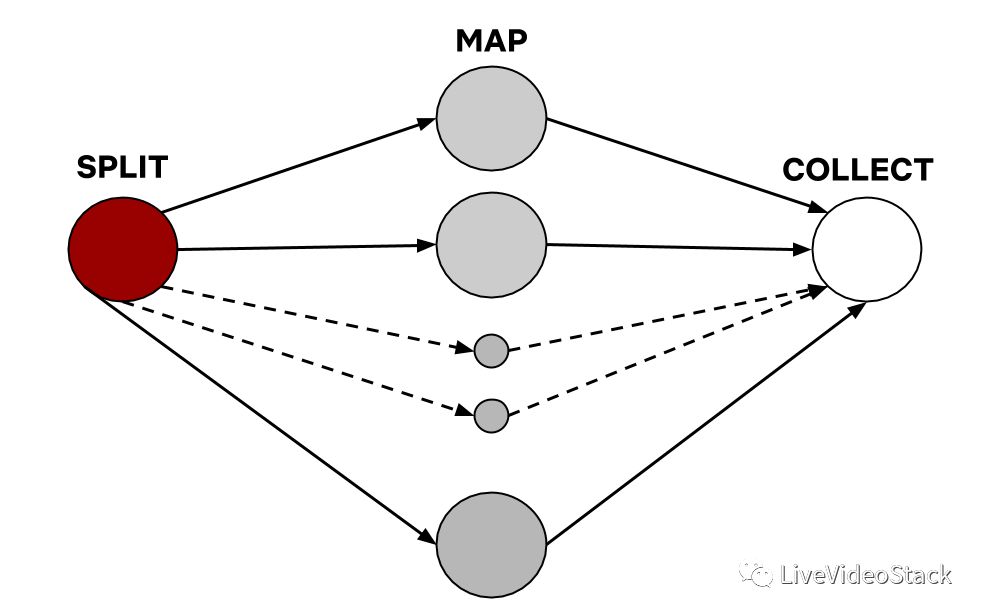
作为我们自动化流水线的一部分,我们在视频的每个帧中都处理和注释不同的变量,以便最好地得出帧的内容,并理解该帧对于故事是否重要。为了进行横向扩展,并为不断增长的内容目录提供可预测的SLA,我们利用Archer框架更有效地处理视频。Archer允许我们把视频分成更小的可以并行处理的视频块。这使我们能够通过提高视频处理流水线的效率来扩展规模,并允许我们将越来越多的内容智能算法集成到我们的工具集中。
通过一系列计算机视觉算法处理一段内容中的每一帧视频,以收集客观帧元数据、帧的潜在表示,以及这些帧所包含的一些上下文元数据。我们处理和应用到视频帧的注解属性大致可以分为三大类:
视觉元数据
通常这些属性是客观的、可测量的,并且主要包含在像素级。视觉属性包括亮度、颜色、对比度和运动模糊等等。
我们在帧级捕获到的一些视觉属性的例子。
上下文元数据
上下文元数据由多个元素的组合组成,这些元素被聚合以从帧的角色、对象和摄影机的动作或移动中获得含义。下面是一些例子:
人脸识别。使用面部特征跟踪、姿态估计和情感分析技术 —— 这使我们能够估计该帧中主体的姿势和情绪。
运动估计—— 这使我们能够估计特定镜头中包含的运动量(包括摄影机运动和主体运动)。这使我们能够控制诸如运动模糊之类的元素,以及识别产生高质量静止图像的摄影机移动。
摄影机拍摄识别—— (例如,近距离拍摄与移动摄影车拍摄)这提供了对电影摄影师意图的洞察,使我们能够快速识别并显现出摄影师选择的体裁风格,以提供对主题表达的情绪、基调和流派的更深入洞察。
对象检测—— 道具和动画对象的分割检测使我们能够找到该帧中重要的非人类主体。
面部特征和姿势估计的例子; 我们用一些因子来检测帧特征,发现有令人信服的面部表情出现。
用于预测摄影机运动的光流分析示例,以估计Black Mirror的拍摄手法(缩小和平移镜头)。
构图元数据
构图元数据是指我们根据摄影、电影拍摄和视觉美学设计中的一些核心原理确定和定义的一组特殊的启发式特征。有一些构图的基本原则:三分法原则、景深原则和对称原则。
对象检测和语义分割的例子,以识别三分法美学的前景对象。
图像排名
在给定视频中的每一帧都经过处理和注解后,下一步就是通过一个自动艺术品流水线从这些帧中选出最佳的候选图像。这样,当我们的创意团队准备好开始一段内容的工作时,他们会自动提供一个高质量的图像集供您选择。下面,我们概述一些我们用来为给定标题提供最佳图像的关键考虑元素。
演员
演员在艺术品中起着非常重要的作用。我们确定给定情节的关键角色的一种方法是利用脸部聚类和角色识别的组合来对主要角色,而不是次要角色或额外角色进行优先顺序。为了达到这个目的,我们训练了一个深度学习模型,从所有符合帧注解的候选帧中追踪面部相似性,以找到并排序该标题的主要演员,而不知道该剧演员的任何情况。
除了演员重要性之外,我们还会考虑演员的姿势,面部标志以及角色的整体位置。
Wynona Ryder出演Joyce Byers时的帧排名和最佳选择范例。
由于次优的面部表情、姿势和动作模糊而排名较低的图像的示例
帧分类
创意和视觉分类是一个非常主观的学科,因为有很多不同的方式来感知和定义图像的多样性。在该解决方案中,图像分类更具体地指的是算法捕捉在单个电影或情节中自然发生的具有启发式变化的能力。在此过程中,我们希望为设计师和创意人员提供一个可扩展的机制,以便快速了解哪些视觉元素最能代表主题,以及哪些元素无法准确代表主题。我们在AVA中引入的一些视觉启发式变量为一个标题提供了不同的图像集,包括摄影机镜头类型(远景vs中景)、视觉相似性(三分法则,亮度,对比度)、颜色(最突出的颜色)和显著图(识别负面空间和复杂度)。通过结合这些启发式变量,我们可以基于定制矢量对图像帧进行有效聚类后再分类。此外,通过合并多个向量,我们能够构建一个多样性指数,针对某个特定情节或电影的所有候选图像进行评分。
AVA的镜头检测分集的例子; (左)中景,(中心)特写,(右)极端特写。
成人图像过滤器
考虑到内容敏感度和受众成熟度等原因,我们还需要确保排除了包含有害或令人反感元素的帧。编辑排除的标准示例,比如: 性/裸露、文字、标志/未经授权的品牌,以及暴力/血腥。为了降低含有这些元素的帧的优先级,我们将这些变量中的每一个的概率作为向量,使我们能够量化并最终为这些帧赋予较低的分数。
我们还添加了标题流派,内容格式,成人度评分等元素作为次要元素或次要特征,并作为反馈,提供给排名预测模型。
-
coolset新技术2012-08-14 0
-
航空电子故障诊断新技术2013-08-02 0
-
电源新技术2013-09-09 0
-
LED显示屏新技术2014-09-17 0
-
哈哈,分享硬件知识:智能硬件新技术2015-04-08 0
-
2015 Cadence新技术研讨会2015-05-19 0
-
如何高效学习一门新技术2016-06-16 0
-
极致4K音视频传输行业又添一家“国家级高新技术企业”,你知道吗?2017-03-20 0
-
特斯拉线圈胖的好看还是瘦的好看?2018-10-08 0
-
电源突破性的新技术2019-07-16 0
-
寻找电源领域的最新技术?2020-08-05 0
-
电能计量基础及新技术2020-10-02 0
-
手机的新技术盘点2020-10-22 0
-
如何寻找电源领域的最新技术?2020-12-03 0
-
音频创新技术主要应用在哪些领域?2021-06-16 0
全部0条评论

快来发表一下你的评论吧 !
