

Arm的人工智能策略:人工智能将会无处不在
电子说
描述
经历了十数年的高速发展之后,以智能手机为代表的移动设备开始迈入下半场。大家对新设备的关注重点从过往的多核、RAM和ROM大小转移到了人工智能、3D游戏和混合现实等新方向上来。这就吸引了包括高通、华为、苹果和联发科等众多移动SoC厂商密锣紧鼓地投入其中。作为全球移动芯片基石的Arm也正在加紧布局,拥抱新时代。
Arm资深市场营销总监Ian Smythe表示,现代人类使用设备的的方式增加了对设备性能的期望值,这就促使Arm达到一个新的愿景——所有人都能够使用这些新技术。这就要求Arm让这些处理器能够胜任各种各样的计算任务,这首先体现在人工智能方面。其实Arm现在在人工方面的表示也不错。根据IDC的调查数据显示,现在市场上有人工智能能力的设备,80%是基于Arm的处理器实现的。但在Ian Smythe看来,这还不够。
Arm的人工智能策略
根据他的看法,人工智能将会无处不在,应用也会多元化,实现人工智能的关键——机器学习往“边缘”转移是一个必然的趋势,因为只有在“边缘”部署,才能解决带宽、功耗、成本、延迟、可靠性和安全等几方面的问题。针对AI的这些特点,Arm升级了他们的AI布局,首先祭出了他们的项目:机器学习运算平台Project Trillium。这是一套包括新的高度可扩展处理器的Arm IP组合,这些产品可以提供增强的机器学习和神经网络功能。
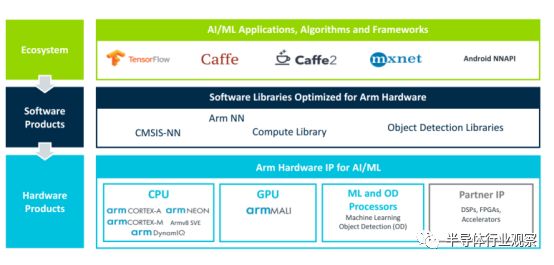
Arm Project Trillium项目
从上图我们可以看出,在Arm的这个项目里,Arm本身的CPU、GPU、ML(Machine Learning)和OD(Obeject Detect)处理器,加上合作伙伴的DSP、FPGA等加速器IP会是整个项目中最基本的硬件支持。
在中间的软件产品层,Project Trillium提供了专门针对Arm硬件优化的软件库,其中包括了Arm NN、CMSIS-NN、Compute Library和Object Detection Libraries。
在应用方面,项目会对TsensorFlow、Caffe、Caffe2、Mxnet和Android NNAPI等主流框架的支持。
Ian Smythe告诉记者:“Arm Project Trillium提供了相应的接入硬件、软件的框架,并相应地为CPU和GPU提供了针对机器学习的加速,这样开发人员就能更好地基于Arm的所有硬件去进行开发,还能非常方便地获得这些开发框架和一些工具系统”。那就意味着开发者如果要开发一个手机应用,不需要去担心这个手机硬件本身的适配性能问题,只需要关心出来的手机应用的性能是最好的。
举个例子,如果开发人员用的是安卓神经网络的API,那么底层的硬件无论是CPU、GPU还是OD、ML都不重要,因为Project Trillium都能够实现最优的处理器的性能,同时也会提供去访问这些Arm底层硬件处理器的软件库,这样就可以节约开发人员大量的精力。
CPU和GPU是Arm AI芯片先锋
由上可知,底层硬件是Arm人工智能策略的关键,而其实对于这些芯片的应用,Arm方面也有了明确清晰的定位。如应用广泛的CPU和GPU将会是他们的AI芯片先锋。
首先是Cortex-A系列处理器。Ian Smythe表示,经过了多年的迭代,Arm的Cortex-A系列处理器的SIMD性能有了极大的提升,尤其是在引入了DynamIQ技术之后,这系列处理器对人工智能的支持有了质的飞跃。
DynamIQ是Arm公司针对机器学习和人工智能应用,面向新一代Cortex-A处理器推出的技术,不同于之前的多核处理设计,DynamIQ能够对单一计算集群上的大小核进行配置,例如1+3或者1+7的SoC设计配置,而这在过去是不可能的。
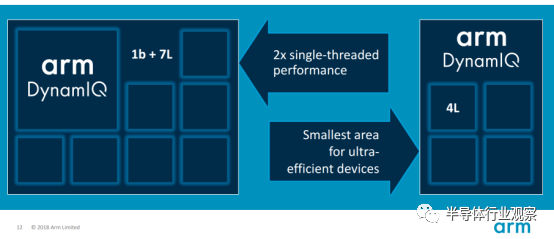
Arm DynamIQ的作用
据Arm介绍,第一代采用DynamIQ的Cortex-A系列处理器在优化应用后,能够在未来三到五年内实现比基于Cortex-A73的设备高50倍的人工智能性能,最多可将CPU和SoC上特定硬件加速器的反应速度提升10倍;
同时,SoC设计者还可以在单个集群中最多部署8个核心,而且每一个核心都可以有不同的性能特性。这些先进的能力可以为机器学习和人工智能带去更快的响应速度。全新设计的内存子系统也将实现更快的数据读取和更加高效的节能特性;
另外还能通过对每一个处理器进行独立的频率控制,高效地在不同的任务间切换最合适的处理器,所以能够在严苛的发热限制实现更高的性能。当然还有更安全的自动安全系统,能够让合作伙伴在故障情况下也能实现安全运行。
Arm同时也为Cortex-M系列其引入包括机器学习、内核加速的计算库,也就是CMSIS-NN,这就让这系列的处理器能够很好地支持机器学习的算法。

Arm Cortex-A、Cortex-M和GPU对ML的支持
至于Mali-GPU,由于GPU本身的产品特性,让它成为Arm人工智能策略中不可或缺的一部分。作为智能手机领域出货量最大的一系列产品,搭载Mali-GPU的SoC在去年出货总计达到12亿套。高度的客户认同感,驱使Arm更积极地将它推向了人工智能,完善AI芯片布局。
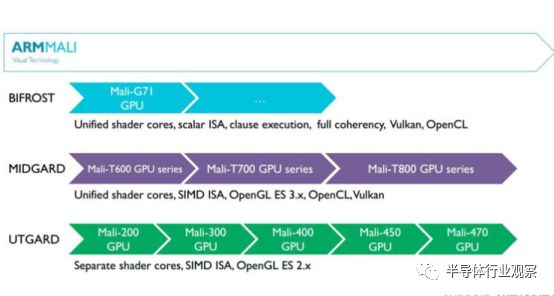
Arm的GPU架构
日前,Arm更是推出了Bifrost架构之下的第二代产品Mali-G52 。作为Arm GPU的新一代架构,全新的Bifrost 针对几大方向做了改良:分别是藉由Claused Shaders 技术,以及基于查表索引的向量着色架构与Wire Light 管线设计所带来的能源效率(Energy Efficiency)提升、结合CCI-550,可让CPU和GPU存取同一快取区块的异构计算(Heterogeneous computing)的一致性最佳化,以及最重要的Vulkan API 支援。这让G52能更好的满足产品的设计要求。
Mali –G52 GPU
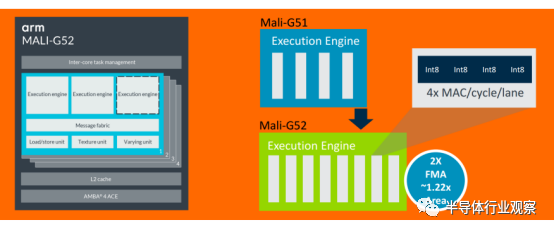
据Ian Smythe介绍,这个GPU采用了典型的四核布局,不同于上一代产品的四线程执行引擎,新的GPU将这个数据提高到八线程,因此在复杂的指令方面,就能实现两倍的性能提升;另外,通过添加一些具体的指令,G52能够更好地支持机器学习,在性能方面也有了更大的改善。这样的提升势必会给中端设备带来非常高质量的表现。
Mali G52出色的机器学习性能
从测试结果也看到,G52较上一代提高了30%的性能密度,能效提高了15%,机器学习性能更是上一代的3.6倍。
ML和OD处理器是重要组成部分
除了CPU和GPU,Arm AI芯片库里还有ML和OD处理器这两个重要部分。在前面介绍Project Trillium的时候,我们曾经提到了这两个产品。这一段里,我们会深入探讨Arm对这两个芯片的期望。
其实关于Arm 的AI芯片,市场上有很多说法,最多的是在大家都在争先恐后拥有人工智能,华为甚至在Kirin 970中引入了寒武纪的NPU芯片,作为智能手机芯片的最大IP供应商的Arm似乎无动于衷,但随着Project Trillium的公布,Arm的专门AI芯片终于揭开了其神秘面纱。
Ian Smythe告诉记者,ML和OD处理器是Arm公司从零开始的设计。与CPU和GPU相比,他们的性能和效率有了大幅的提升;另外,Arm还很有想法地加入DSP的功能。这让这两系列处理器非常适合于机器学习。首先我们先来了解一下ML处理器。
据Arm方面介绍,这个全新架构的处理器是7nm工艺下实现的,拥有非常高的性能性能密度,能够实现每平方毫米多达4.6万亿次的计算能力。这款处理器将会在2018年中,通过合作伙伴推向市场。

Arm ML处理器
OD处理器则是Arm AI芯片领域的另一个关注点。这是Arm公司基于2016年收购的Apical公司的技术开发的第二代产品。后者作为影像处理与嵌入式机器视觉技术市场的绝对专家,让我们坚信Arm OD处理器的实力。

Arm OD处理器
Ian Smythe指出,新一代的OD处理器能够实现非常高速的目标检测:在每秒钟可以实现无限次数量的帧的鉴别,这样就可以以非常搞的速度去检测丰富的内容。
比如说我们可以想象一个场景,在这个场景中OD处理器能以60FPS的速度,在全高清的环境下实时识别无限数量的物体,并找到这个识别目标物体的原数据,然后把原数据发给下一个要进行处理的处理器。
如果我们把Arm机器学习处理器和目标检测处理器合起来用,必然能很好地提升计算机的视觉能力。
更多的多媒体套件辅助
对于Arm包括AI在内的很多应用,想显示出来,就必须要有更好的多媒体条件支持,而Arm本身就是这样一个角色。在CPU、GPU和AI芯片之外,Arm还有DPU和VPU这样的产品,他们将是将Arm产品性能结果展示到用户面前的一个重要桥梁,Arm在日前也对其做了更新,首先就是Mali-D51。

Arm的多媒体套件赋能下一代技术
据介绍,Mali-D51是第一款基于Komeda架构构建的主流显示处理器,拥有2017年出品的高端显示处理器Mali-D71的众多优势,并将之整合至迄今为止Arm旗下最小的DPU上。,实现的性能包括:
与上一代的Mali-DP650相比较,D51实现了两倍的面积效率,30%的系统功耗额,内存延迟也降低了50%;场景复杂度也加倍,还与Mali-D71一样支持8层图像处理能力。Ian Smythe表示,经过全面优化,D51可与Mali多媒体套件中的其他IP无缝协作,结合Assertive Display 5技术使用,甚至可将HDR(高动态范围图像)带入主流设备;结合CoreLink MMU-600,可提升系统内存管理效率。
Arm的显示解决方案
视频处理器V52则是Arm的另一个高质量产品。与上一代的V61相比,V52在每一个核的解码性能是翻了一番,能够实现了4K,每秒30帧的高画质显示支持;在硅面积方面,与V61相比,同样实现4K60显示的情况下,V52的硅面积与后者相比,减少了38%。
而在解码质量方面,V52同样也有了20%的提升。换句话说,就是在达到同样的图像质量的前提之下,在比特数上面V52能够减少20%。对于一些非常关键的应用,比如说视频会议而言,如果带宽条件有限的话,其实这种更少的比特数是非常关键的。
这颗芯片能支持现在市面上包括HEVC、VP9、VP8、H.264、AVS+、Legacy在内的几乎所有标准。能够满足越来越多4K内容制作需求。
在GPU方面,Arm还带来了全新的G31。这是他们Bifrost架构家族中,G30系列的第一款GPU。主要是针对可能低端配置的智能手机和数字电视应用。它的总硅面积降低了20%,在性能密度上有20%的提高,同时在UI的性能方面有12%的提升。
这款产品具备可配置性的特点,让开发者在执行引擎方面,可以选择一个或者是两个;同时在显示时钟也可以配置每个是一个像素还是两个像素。据介绍,这款极小的GPU还能够以极低的成本支持OpenGL ES3.2和Vulkan,这势必将帮助开发者在低端产品里实现更高的性能。
在Arm这些的产品赋能下,一个全新的科技世界即将到来,你准备好迎接了吗?
-
人工智能是什么?2015-09-16 0
-
人工智能的前世今生 引爆人工智能大时代2016-03-03 0
-
人工智能传感技术2016-06-03 0
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 0
-
人工智能发展的好与坏2017-06-24 0
-
人工智能就业前景2018-03-29 0
-
人工智能的影响超乎你想象2018-06-22 0
-
解读人工智能的未来2018-11-14 0
-
什么是基于云计算的人工智能服务?2019-09-11 0
-
人工智能在英语教育领域2020-12-14 0
-
如何提高人工智能应用开发的生产效率2021-02-01 0
-
路径规划用到的人工智能技术2021-07-20 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
未来,人工智能无处不在2017-09-21 692
全部0条评论

快来发表一下你的评论吧 !
