

三种回归算法及其优缺点,将会为我们理解和选择算法提供很好的帮助
电子说
描述
任何一个机器学习问题都有着不止一种算法来解决,在机器学习领域“没有免费的午餐”的意思就是没有一个对于所有问题都很好的算法。机器学习算法的表现很大程度上与数据的结构和规模有关。所以判断算法性能最好的办法就是在数据上运行比较结果。
不过与此同时我们对于算法的优缺点有一定的了解可以帮助我们找需要的算法。本文将会介绍三种回归算法及其优缺点,将会为我们理解和选择算法提供很好的帮助。
线性和多项式回归
在这一简单的模型中,单变量线性回归的任务是建立起单个输入的独立变量与因变量之间的线性关系;而多变量回归则意味着要建立多个独立输入变量与输出变量之间的关系。除此之外,非线性的多项式回归则将输入变量进行一系列非线性组合以建立与输出之间的关系,但这需要拥有输入输出之间关系的一定知识。训练回归算法模型一般使用随机梯度下降法(SGD)。
优点:
建模迅速,对于小数据量、简单的关系很有效;
线性回归模型十分容易理解,有利于决策分析。
缺点:
对于非线性数据或者数据特征间具有相关性多项式回归难以建模;
难以很好地表达高度复杂的数据。
神经网络
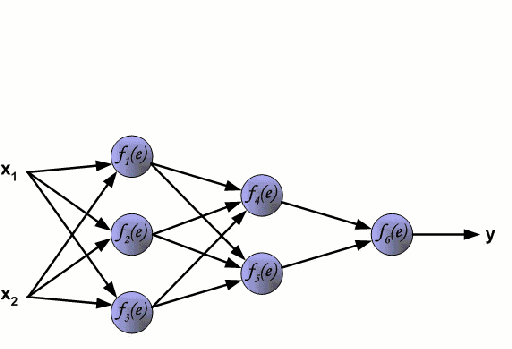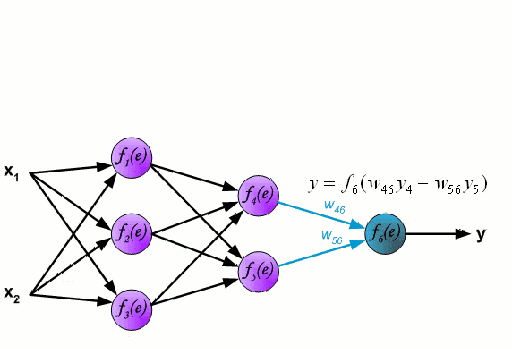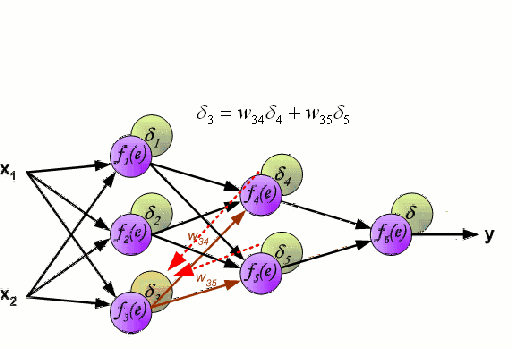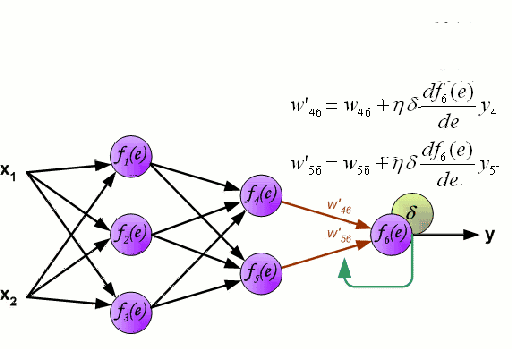
神经网络由一系列称为神经元的节点通过内部网络连接而成,数据的特征通过输入层被逐级传递到网络中,形成多个特征的线性组合,每个特征会与网络中的权重相互作用。随后神经元对线性组合进行非线性变化,这使得神经网络模型具有对多特征复杂的非线性表征能力。神经网络可以具有多层结构,以增强对于输入数据特征的表征。人们一般利用随机梯度下降法和反向传播法来对神经网络进行训练,请参照上述图解。
优点:
多层的非线性结构可以表达十分复杂的非线性关系;
模型的灵活性使得我们不需要关心数据的结构;
数据越多网络表现越好。
缺点:
模型过于复杂,难以解释;
训练过程需要强大算力、并且需要微调超参数;
对数据量依赖大,但常规机器学习问题则使用较小量数据。
回归树和回归森林
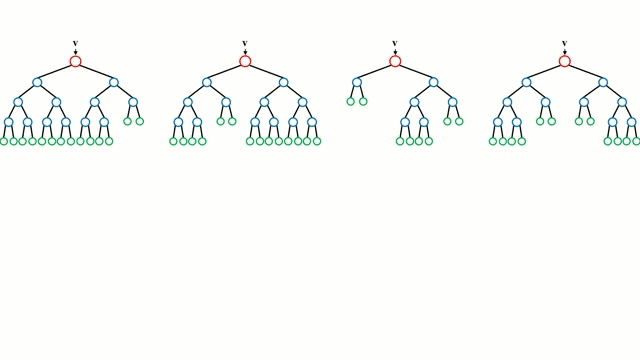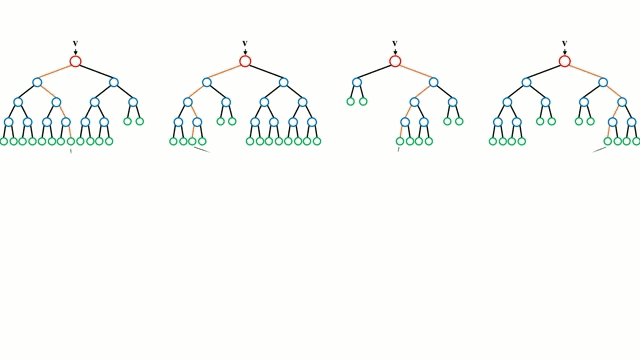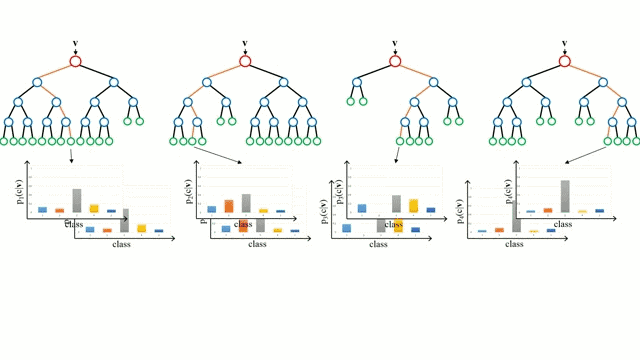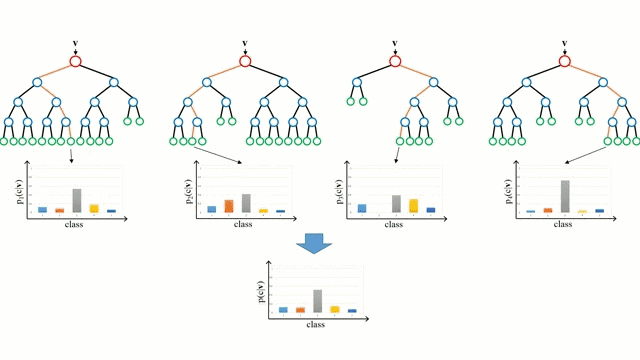
让我们从最基本的概念出发,决策树是通过遍历树的分支并根据节点的决策选择下一个分支的模型。树型感知利用训练数据作为数据,根据最适合的特征进行拆分,并不断进行循环指导训练数据被分到一类中去。建立树的过程中需要将分离建立在最纯粹的子节点上,从而在分离特征的情况下保持分离数目尽可能的小。纯粹性是来源于信息增益的概念,它表示对于一个未曾谋面的样本需要多大的信息量才能将它正确的分类。实际上通过比较熵或者分类所需信息的数量来定义。而随机森林则是决策树的简单集合,输入矢量通过多个决策树的处理,最终的对于回归需要对输出数据取平均、对于分类则引入投票机制来决定分类结果。
优点:
具有很高的复杂度和高度的非线性关系,比多项式拟合拥有更好的效果;
模型容易理解和阐述,训练过程中的决策边界容易实践和理解。
缺点:
由于决策树有过拟合的倾向,完整的决策树模型包含很多过于复杂和非必须的结构。但可以通过扩大随机森林或者剪枝的方法来缓解这一问题;
较大的随机数表现很好,但是却带来了运行速度慢和内存消耗高的问题。
-
机器算法学习比较2016-09-27 0
-
常见算法优缺点比较2017-12-02 0
-
FDTD和FEM算法各有什么优缺点2018-08-04 0
-
经典算法大全(51个C语言算法+单片机常用算法+机器学十大算法)2018-10-23 0
-
连接到物联网的三种常见无线通信技术优缺点对比2019-05-07 0
-
HFSS 仿真算法及其应用场景详解:有限元算法、积分方程算法、PO算法2019-09-20 0
-
干货 | 这些机器学习算法,你了解几个?2019-09-22 0
-
回归算法之逻辑回归的介绍2020-05-21 0
-
回归算法有哪些,常用回归算法(3种)详解2020-07-28 0
-
FOC中的三种电流采样方式,你知道怎么选择吗?2021-03-19 0
-
主流的三种RF方案及其优缺点对比分析2021-05-25 0
-
常用的无线传感器网络数据融合算法有什么优缺点?2021-06-03 0
-
算法的三种结构介绍2021-11-08 0
-
机器学习算法总结 机器学习算法是什么 机器学习算法优缺点2023-08-17 1072
全部0条评论

快来发表一下你的评论吧 !
