

嵌入式神经网络赋予人工智能视觉、听觉和分析能力
电子说
描述
人工智能(AI)潜在的应用与日俱增。不同的神经网络(NN)架构能力经过测试、调整和改进,解决了不同的问题,也开发出以AI优化数据分析的各种方法。当今大部份的AI应用,例如Google翻译(Google Translate)和亚马逊(Amazon) Alexa语音识别和视觉识别系统,都利用了云端的力量。
藉由依赖常时连网(always-on)的因特网联机、高带宽链路和网络服务,物联网(IoT)产品和智能手机应用也可以整合AI功能。到目前为止,大部份的注意力都集中在基于视觉的人工智能上,部份原因在于它易于出现在新闻报导和视频中,另外一部份的原因则是它更类似于人类的活动。
在影像识别中,针对一个2D影像进行分析——每次处理一组像素,透过神经网络的连续层识别更大的特征点。一开始检测到的边缘是具有高对比度差异的部份。以人脸为例,最早识别的部位是在眼睛、鼻子和嘴巴等特征外围。随着检测过程深入神经网络,将会检测到整个脸部的特征。
而在最后阶段,结合这些特征及其位置信息,就能在可用的数据库中识别到具有最匹配的一张特定人脸。
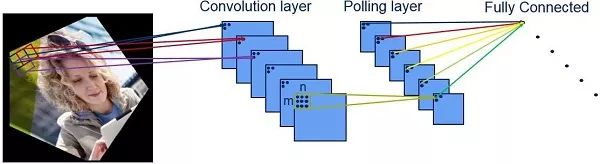
神经网络的特征提取
为了匹配经由相机拍摄或撷取的物体,希望能透过神经网络在其数据库中找到匹配机率最高的人脸。其巧妙之处在于撷取物体时并不需要与数据库中的照片拍摄角度或场景完全相同,也不必处于相同的光线条件下。
AI这么快就流行起来,在很大程度上是因为开放的软件工具(也称为架构),使得建构和训练神经网络实现目标应用变得容易起来,即使是使用各种不同的编程语言。两个常见的通用架构是TensorFlow和Caffe。对于已知的识别目标,可以脱机定义和训练神经网络。一旦训练完成,神经网络就可以很容易地部署到嵌入式平台上。这是一种很聪明的划分方式,能够藉由开发PC或云端的力量来训练神经网络,而功耗敏感的嵌入式处理器只需为了识别目的而使用训练数据。
这种类似人类的人/物识别能力与流行的应用密切相关,例如工业机器人和自动驾驶车。然而,人工智能在音频领域同样具有吸引力和强大的能力。它采用和影像特征分析同样的方式,可以将音频分解成特征点而馈入神经网络。其中一种方法是使用梅尔频率倒谱系数(MFCC)将音频分解成有用的特性。一开始,音频样本被分解成短时间的讯框,例如20ms,然后再对信号进行傅利叶转换(Fourier transforms),使用重迭三角窗将音频频谱的功率映像到非线性尺度上。
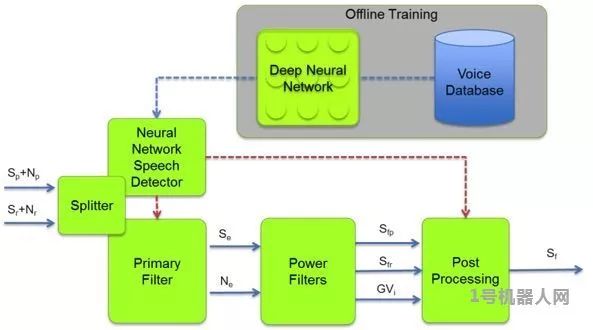
声音神经网络分解图
透过这些提取的特征,神经网络可以用来确定音频样本和音频样本数据库中词汇或者语音的相似度。就像影像识别一样,神经网络为特定词汇在数据库中提取了可能的匹配。对于那些想要复制Google和亚马逊的‘OK Google’或‘Alexa’语音触发(VT)功能的业者来说,KITT.AI透过Snowboy提供了一个解决方案。触发关键词可以上传到他们的平台进行分析,导出一个档案后再整合进嵌入式平台上的Snowboy应用程序,这样语音触发(VT)的关键词在脱机情况下也可以被检测到。音频识别并不局限于语言识别。TensorFlow提供了一个iOS上的示例,可以区分男性和女性的声音。
另一个替代应用是检测我们居住的城市和住宅周围动物和其他声音。这已经由安装在英国伦敦伊丽莎白女王奥林匹克公园(Queen Elizabeth Olympic Park)的深度学习蝙蝠监控系统验证过了。它提供了将视觉和听觉识别神经网络整合于一个平台的可能性。例如透过音频识别别特定的声音,可以用来触发安全系统进行录像。
有很多基于云端的AI应用是不实际的,一方面存在数据隐私的问题,另一方面由于数据连接性差或带宽不够造成服务不能持续。另外,实时性能也是一个值得关注的问题。例如工业制造系统需要实时响应,以便实时操作生产线,如果连接云端服务的延迟就太长了。
因此,将AI功能移动到“边缘”(edge)越来越受到关注。也就是说,在使用中的装置上发挥人工智能的力量。很多IP供货商都提供了解决方案,如CEVA的CEVA-X2和NeuPro IP核心和配套软件,都很容易和现有的神经网络架构进行整合。这为开发具备人工智能的嵌入式系统提供了可能性,同时提供了低功耗处理器的灵活性。以一个语音识别系统为例,可以利用整合在芯片上的功耗优化人工智能,以识别一个语音触发关键词和语音命令(VC)的最小化组合。更复杂的语音命令和功能,可以在应用从低功耗的语音触发状态下唤醒之后,由基于云端的AI完成。
最后,卷积神经网络(CNN)也可以用来提高文本到语音(TTS)系统的质量。一直以来,TTS用于将同一个配音员的许多高质量录音片段,整合成连续的声音。虽然所输出的结果是人类可以理解的,但由于输出结果存在奇怪的语调和音调,仍然感觉像是机器人的声音。如果试图表现出不同的情绪则需要一组全新的录音。Google的WaveNet改善了当前的情况,透过CNN以每秒16,000个样本产生TTS波形。与之前的声音样本相比,其输出结果是无缝连接的,明显表现出更自然、更高质量的声音。
-
嵌入式人工智能的就业方向有哪些?2024-02-26 0
-
嵌入式系统与人工智能2019-02-28 0
-
【专辑精选】人工智能之神经网络教程与资料2019-05-07 0
-
人工智能:超越炒作2019-05-29 0
-
在人工智能神经网络ADC设计方面各位有什么见解呢?2021-06-24 0
-
嵌入式与人工智能关系是什么2021-10-27 0
-
什么叫嵌入式人工智能2021-10-28 0
-
嵌入式人工智能简介2021-10-28 0
-
嵌入式人工智能的相关资料分享2021-11-08 0
-
什么叫嵌入式,以及与人工智能的关系2021-11-08 0
-
嵌入式中的人工神经网络的相关资料分享2021-11-09 0
-
人工智能对汽车芯片设计的影响是什么2021-12-17 0
-
如何实现开发嵌入式神经网络2021-12-23 0
-
嵌入式与人工智能关系是什么?2021-12-27 0
-
嵌入式人工智能学习路线2022-09-16 0
全部0条评论

快来发表一下你的评论吧 !
