

使用Tensorflow实现线性支持向量机的形式来作为 Tensorflow 的“应用式入门教程
电子说
描述
本文拟通过使用 Tensorflow 实现线性支持向量机(LinearSVM)的形式来作为 Tensorflow 的“应用式入门教程”。虽说用 mnist 做入门教程项目几乎是约定俗成的事了,但总感觉照搬这么个东西过来当专栏有些水……所以还是自己亲手写了个 LinearSVM ( σ'ω')σ
在实现之前,先简要介绍一下 LinearSVM 算法(详细介绍可以参见这里):
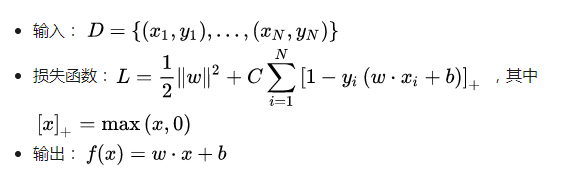
以及介绍一下 Tensorflow 的若干思想:
Tensorflow 的核心在于它能构建出一张“运算图(Graph)”,我们需要做的是往这张 Graph 里加入元素
基本的元素有如下三种:常量(constant)、可训练的变量(Variable)和不可训练的变量(Variable(trainable=False))
由于机器学习算法常常可以转化为最小化损失函数,Tensorflow 利用这一点、将“最小化损失”这一步进行了很好的封装。具体而言,你只需要在 Graph 里面将损失表达出来后再调用相应的函数、即可完成所有可训练的变量的更新
其中第三点我们会在实现 LinearSVM 时进行相应说明,这里则会把重点放在第二点上。首先来看一下应该如何定义三种基本元素以及相应的加、减、乘、除(值得一提的是,在 Tensorflow 里面、我们常常称处于 Graph 之中的 Tensorflow 变量为“Tensor”,于是 Tensorflow 就可以理解为“Tensor 的流动”)(注:Tensor 这玩意儿叫张量,数学上是挺有来头的东西;然而个人认为如果不是做研究的话就完全可以不管它数学内涵是啥、把它当成高维数组就好 ( σ'ω')σ):
import tensorflow as tf
# 定义常量、同时把数据类型定义为能够进行 GPU 计算的 tf.float32 类型
x = tf.constant(1, dtype=tf.float32)
# 定义可训练的变量
y = tf.Variable(2, dtype=tf.float32)
# 定义不可训练的变量
z = tf.Variable(3, dtype=tf.float32, trainable=False)
x_add_y = x + y
y_sub_z = y – z
x_times_z = x * z
z_div_x = z / x
此外,Tensorflow 基本支持所有 Numpy 中的方法、不过它留给我们的接口可能会稍微有些不一样。以“求和”操作为例:
# 用 Numpy 数组进行 Tensor 的初始化
x = tf.constant(np.array([[1, 2], [3, 4]]))
# Tensorflow 中对应于 np.sum 的方法
axis0 = tf.reduce_sum(x, axis=0) # 将会得到值为 [ 4 6 ] 的 Tensor
axis1 = tf.reduce_sum(x, axis=1) # 将会得到值为 [ 3 7 ] 的 Tensor
更多的操作方法可以参见这里(https://zhuanlan.zhihu.com/p/26657869)
最后要特别指出的是,为了将 Graph 中的 Tensor 的值“提取”出来、我们需要定义一个 Session 来做相应的工作。可以这样理解 Graph 和 Session 的关系(注:该理解可能有误!如果我确实在瞎扯的话,欢迎观众老爷们指出 ( σ'ω')σ):
Graph 中定义的是一套“运算规则”
Session 则会“启动”这一套由 Graph 定义的运算规则,而在启动的过程中、Session 可能会额外做三件事:
从运算规则中提取出想要的中间结果
更新所有可训练的变量(如果启动的运算规则包括“更新参数”这一步的话)
赋予“运算规则”中一些“占位符”以具体的值
其中“更新参数”和“占位符”的相关说明会放在后文进行,这里我们只说明“提取中间结果”是什么意思。比如现在 Graph 中有这么一套运算规则:,而我只想要运算规则被启动之后、y 的运算结果。该需求的代码实现如下:
x = tf.constant(1)
y = x + 1
z = y + 1
print(tf.Session().run(y)) # 将会输出 2
如果我想同时获得 y 和 z 的运算结果的话,只需将第 4 行改为如下代码即可:
print(tf.Session().run([y, z])) # 将会输出 [2, 3]
最后想要特别指出一个非常容易犯错的地方:当我们使用了 Variable 时,必须要先调用初始化的方法之后、才能利用 Session 将相应的值从 Graph 里面提取出来。比如说,下面这段代码是会报错的:
x = tf.Variable(1)
print(tf.Session().run(x)) # 报错!
应该改为:
x = tf.Variable(1)
with tf.Session().as_default() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(x))
其中 tf.global_variables_initializer() 的作用可由其名字直接得知:初始化所有 Variable
接下来就是 LinearSVM 的实现了,由前文的讨论可知,关键只在于把损失函数的形式表达出来(利用到了 ClassifierBase(https://link.zhihu.com/?target=https%3A//github.com/carefree0910/MachineLearning/blob/master/Util/Bases.py%23L196);同时为了简洁,我们设置C=1):
import tensorflow as tf
from Util.Bases import ClassifierBase
class TFLinearSVM(ClassifierBase):
def __init__(self):
super(TFLinearSVM, self).__init__()
self._w = self._b = None
# 使用 self._sess 属性来存储一个 Session 以方便调用
self._sess = tf.Session()
def fit(self, x, y, sample_weight=None, lr=0.001, epoch=10 ** 4, tol=1e-3):
# 将 sample_weight(样本权重)转换为 constant Tensor
if sample_weight is None:
sample_weight = tf.constant(
np.ones(len(y)), dtype=tf.float32, name="sample_weight")
else:
sample_weight = tf.constant(
np.array(sample_weight) * len(y), dtype=tf.float32, name="sample_weight")
# 将输入数据转换为 constant Tensor
x, y = tf.constant(x, dtype=tf.float32), tf.constant(y, dtype=tf.float32)
# 将需要训练的 w、b 定义为可训练 Variable
self._w = tf.Variable(np.zeros(x.shape[1]), dtype=tf.float32, name="w")
self._b = tf.Variable(0., dtype=tf.float32, name="b")
# ========== 接下来的步骤很重要!!! ==========
# 调用相应方法获得当前模型预测值
y_pred = self.predict(x, True, False)
# 利用相应函数计算出总损失:
# cost = ∑_(i=1)^N max(1-y_i⋅(w⋅x_i+b),0)+1/2 + 0.5 * ‖w‖^2
cost = tf.reduce_sum(tf.maximum(
1 - y * y_pred, 0) * sample_weight) + tf.nn.l2_loss(self._w)
# 利用 Tensorflow 封装好的优化器定义“更新参数”步骤
# 该步骤会调用相应算法、以减少上述总损失为目的来进行参数的更新
train_step = tf.train.AdamOptimizer(learning_rate=lr).minimize(cost)
# 初始化所有 Variable
self._sess.run(tf.global_variables_initializer())
# 不断调用“更新参数”步骤;如果期间发现误差小于阈值的话就提前终止迭代
for _ in range(epoch):
# 这种写法是比较偷懒的写法,得到的 cost 将不太精确
if self._sess.run([cost, train_step])[0] < tol:
break
然后就要定义获取模型预测值的方法——self.predict 了:
def predict(self, x, get_raw_results=False, out_of_sess=True):
# 利用 reduce_sum 方法算出预测向量
rs = tf.reduce_sum(self._w * x, axis=1) + self._b
if not get_raw_results:
rs = tf.sign(rs)
# 如果 out_of_sess 参数为 True、就要利用 Session 把具体数值算出来
if out_of_sess:
rs = self._sess.run(rs)
# 否则、直接把 Tensor 返回即可
return rs
之所以要额外用一个 out_of_sess 参数控制输出的原因如下:
Tensorflow 在内部进行 Graph 运算时是无需把具体数值算出来的、不如说使用原生态的 Tensor 进行运算反而会快很多
当模型训练完毕后,在测试阶段我们希望得到的当然是具体数值而非 Tensor、此时就需要 Session 帮我们把中间结果提取出来了
以上就是 LinearSVM 的完整实现,可以看到还是相当简洁的
这里特别指出这么一点:利用 Session 来提取中间结果这个过程并非是没有损耗的;事实上,当 Graph 运算本身的计算量不大时,开启、关闭 Session 所造成的开销反而会占整体开销中的绝大部分。因此在我们编写 Tensorflow 程序时、要注意避免由于贪图方便而随意开启 Session
在本文的最后,我们来看一下 Tensorflow 里面 Placeholder 这个东西的应用。目前实现的 LinearSVM 虽说能用,但其实存在着内存方面的隐患。为了解决这个隐患,一个常见的做法是分 Batch 训练,这将会导致“更新参数”步骤每次接受的数据都是“不固定”的数据——原数据的一个小 Batch。为了描述这个“不固定”的数据、我们就需要利用到 Tensorflow 中的“占位符(Placeholder)”,其用法非常直观:
# 定义一个数据类型为 tf.float32、“长”未知、“宽”为 2 的矩阵
Placeholder x = tf.placeholder(tf.float32, [None, 2])
# 定义一个 numpy 数组:[ [ 1 2 ], [ 3 4 ], [ 5 6 ] ]
y = np.array([[1, 2], [3, 4], [5, 6]])
# 定义 x + 1 对应的 Tensor
z = x + 1
# 利用 Session 及其 feed_dict 参数、将 y 的值赋予给 x、同时输出 z 的值 print(tf.Session().run(z, feed_dict={x: y}))
# 将会输出 [ [ 2 3 ], [ 4 5 ], [ 6 7 ] ]
于是分 Batch 运算的实现步骤就很清晰了:
把计算损失所涉及的所有 x、y 定义为占位符
每次训练时,通过 feed_dict 参数、将原数据的一个小 Batch 赋予给 x、y
占位符还有许多其它有趣的应用手段,它们的思想都是相通的:将未能确定的信息以 Placeholder 的形式进行定义、在确实调用到的时候再赋予具体的数值
事实上,基本所有 Tensorflow 模型都要用到 Placeholder。虽然我们上面实现的 TFLinearSVM 没有用到,但正因如此、它是存在巨大缺陷的(比如说,如果在同一段代码中不断地调用参数 out_of_sess 为 True 的 predict 方法的话,会发现它的速度越来越慢。观众老爷们可以思考一下这是为什么 ( σ'ω')σ)
以上就是 Tensorflow 的一个简要教程,虽然我是抱着“即使从来没用过 Tensorflow 也能看懂”的心去写的,但可能还是会有地方说得不够详细;若果真如此,还愿不吝指出 ( σ'ω')σ
- 相关推荐
- 人工智能
- tensorflow
-
关于 TensorFlow2018-03-30 0
-
使用 TensorFlow, 你必须明白 TensorFlow2018-03-30 0
-
干货 | TensorFlow的55个经典案例2018-10-09 0
-
Tensorflow的非线性回归2020-05-12 0
-
TensorFlow如何入门2020-05-27 0
-
tensorflow怎么入门2020-05-28 0
-
情地使用Tensorflow吧!2020-07-22 0
-
TensorFlow是什么2020-07-22 0
-
TensorFlow教程|常见问题2020-07-27 0
-
TensorFlow XLA加速线性代数编译器2020-07-28 0
-
TensorFlow指定CPU和GPU设备操作详解2020-07-28 0
-
TensorFlow常用Python扩展包2020-07-28 0
-
TensorFlow实现简单线性回归2020-08-11 0
-
TensorFlow实现多元线性回归(超详细)2020-08-11 0
-
Mali GPU支持tensorflow或者caffe等深度学习模型吗2022-09-16 0
全部0条评论

快来发表一下你的评论吧 !
