

谷歌提出对加速智能体的学习过程
电子说
描述
在强化学习问题中,关于任务目标的制定,往往需要开发人员花费很多的精力,在本文中,谷歌大脑联合佐治亚理工学院提出了正向-反向强化学习(Forward-Backward Reinforcement Learning,FBRL),它既能从开始位置正向进行探索,也可以从目标开始进行反向探索,从而加速智能体的学习过程。
一般来说,强化学习问题的目标通常是通过手动指定的奖励来定义的。为了设计这些问题,学习算法的开发人员必须从本质上了解任务的目标是什么。然而我们却经常要求智能体在没有任何监督的情况下,在这些稀疏奖励之外,独自发现这些任务目标。虽然强化学习的很多力量来自于这样一种概念,即智能体可以在很少的指导下进行学习,但这一要求对训练过程造成了极大的负担。
如果我们放松这一限制,并赋予智能体关于奖励函数的知识,尤其是目标,那么我们就可以利用反向归纳法(backwards induction)来加速训练过程。为了达到这个目的,我们提出训练一个模型,学习从已知的目标状态中想象出反向步骤。
我们的方法不是专门训练一个智能体以决策该如何在前进的同时到达一个目标,而是反向而行,共同预测我们是如何到达目标的。我们在Gridworld和汉诺塔(Towers of Hanoi)中对我们的研究进行了评估,并通过经验证明了,它的性能比标准的深度双Q学习(Deep Double Q-Learning,DDQN)更好。
强化学习(Reinforcement Learning,RL)问题通常是由智能体在对环境的任务奖励盲然无知的情况下规划的。然而,对于许多稀疏奖励问题,包括点对点导航、拾取和放置操纵、装配等等目标导向的任务,赋予该智能体以奖励函数的知识,对于学习可泛化行为来说,既可行又实用。
通常,这些问题的开发人员通常知道任务目标是什么,但不一定知道如何解决这些问题。在本文中,我们将介绍我们如何利用对目标的知识,使我们甚至能够在智能体到达这些领域之前学习这些领域中的行为。相比于那些从一开始就将学习初始化的方法,这种规划性方案可能更容易解决。
例如,如果我们知道所需的位置、姿势或任务配置,那么我们就可以逆转那些将我们带到那里的操作,而不是迫使智能体独自通过随机发现来解决这些难题。
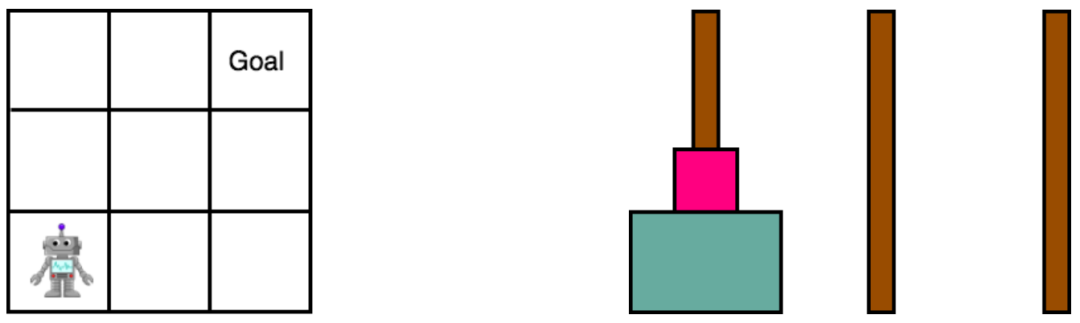
Gridworld和汉诺塔环境
本文中,我们介绍了正向-反向强化学习(Forward-Backward Reinforcement Learning,FBRL),它引入反向归纳,使我们的智能体能够及时进行逆向推理。通过一个迭代过程,我们既从开始位置正向进行了探索,也从目标开始进行了反向探索。
为了实现这一点,我们引入了一个已学习的反向动态模型,以从已知的的目标状态开始进行反向探索,并在这个局部领域中更新值。这就产生了“展开”稀疏奖励的效果,从而使它们更容易发现,并因此加速了学习过程。
标准的基于模型的方法旨在通过正向想象步骤并使用这些产生幻觉的事件来增加训练数据,从而减少学习优秀策略所必需的经验的数量。然而,并不能保证预期的状态会通向目标,所以这些转出结果可能是不充分的。
预测一个行为的结果的能力并不一定能提供指导,告诉我们哪些行为会通向目标。与此相反,FBRL采用了一种更有指导性的方法,它给定了一个精确的模型,我们相信,每一个处于反向步骤中的状态都有通向目标的路径。
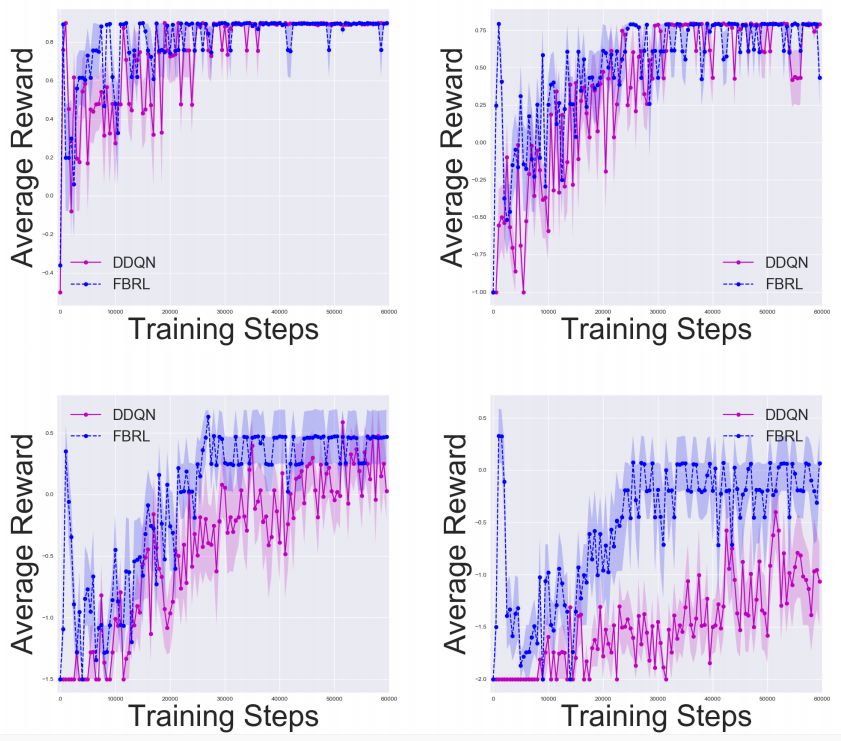
Gridworld中的实验结果,其中n =5、10、15、20。我们分别使用50、100、150、200步的固定水平,结果是10次实验的平均值。
相关研究
当我们访问真正的动态模型时,可以使用纯粹基于模型的方法(如动态编程)来计算所有状态的值(Sutton和Barto于1998年提出),尽管当状态空间较大或连续时,难以在整个状态空间中进行迭代。Q-Learning是一种无模型方法,它通过直接访问状态以在线方式更新值,而函数逼近技术(如Deep Q-Learning)可以泛化到未见的数据中(Mnih等人于2015年提出)。
基于模型和无模型信息的混合方法也可以使用。例如,DYNA-Q(Sutton于1990年提出)是一种早期的方法,它使用想象的转出出来更新Q值,就如同在真实环境中经历过一样。最近出现了更多方法,例如NAF(Gu等人于2016年提出)和I2A(Weber等人于2017年提出)。但这些方法只使用正向的想象力。
与我们自己的方法相似的方法是反向的值迭代(Zang等人于2007年提出),但这是一种纯粹基于模型的方法,并且它不学习反向模型。一个相关的方法从一开始就实现双向搜索和目标(Baldassarre于2003年提出),但这项研究只是学习值,而我们的目标是学习行动和值。
另一项相似的研究是通过使用接近目标状态的反向课程来解决问题(Florensa等人于2017年提出)。但是,该方法假设智能体可以在目标附近得以初始化。我们不做这个假设,因为了解目标状态并不意味着我们知道该如何达到这一状态。
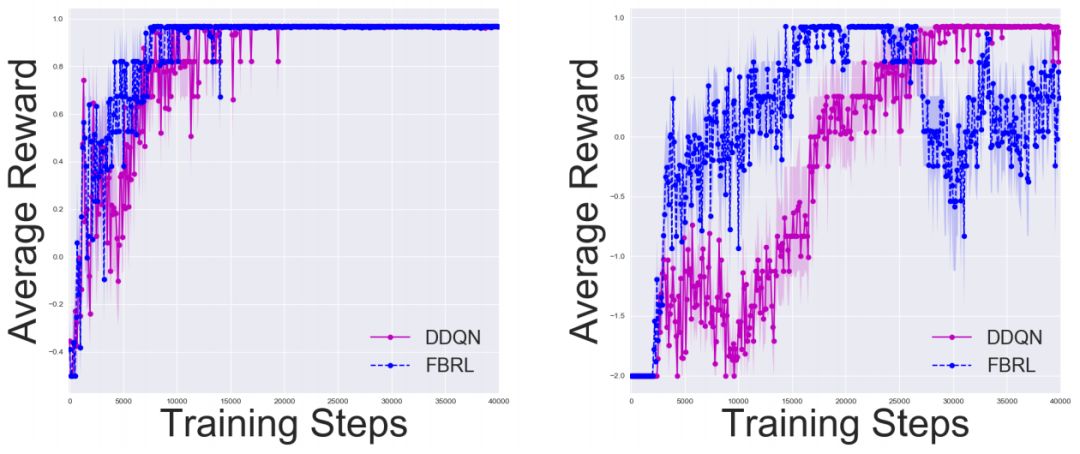
汉诺塔中的实验结果,其中n = 2、3。我们分别使用50、100步的固定水平。 结果是10次试验的平均值。
许多研究通过使用域知识来帮助加速学习,例如奖励塑造(Ng等人于1999年提出)。另一种方法是更有效地利用回放缓冲区中的经验。优先经验复现(Schaul等人于2015年提出)旨在回放具有高TD误差的样本。事后经验回放(Hindsight experience replay)将环境中的每个状态视为一个潜在目标,这样即使系统无法达到所需的目标,也可以进行学习。
使用反向动力学的概念类似于动力学逆过程(Agrawal等人于2016年,Pathak等人于2017年提出)。在这些方法中,系统预测在两个状态之间产生转换的动态。我们的方法是利用状态和动作来预测前一个状态。此函数的目的是进行反向操作,并使用此分解来学习靠近目标的值。
本文中,我们介绍了一种加速学习具有稀缺奖励问题的方法。我们介绍了FBRL,它从目标的反向过程中得到了想象步骤。我们证明了该方法在Gridworld和诺塔中的性能表现优于DDQN。这项研究有多个扩展方向。
我们对于评估一个反向计划方法很感兴趣,但我们也可以运用正向和反向的想象力进行训练。另一项进步是改善规划策略。我们使用了一种具有探索性和贪婪性的方法,但没有评估如何在两者之间进行权衡。我们可以使用优先扫描(Moore和Atkeson等人于1993年提出),它选择那些能够导致具有高TD误差状态的行为。
-
谷歌地图新添“驾驶模式”智能判断目的地2016-01-14 0
-
谷歌为人工智能提出5项安全要求:机器人伤人是因为太“蠢”了?2016-08-13 0
-
智能家居APP控制2017-10-11 0
-
谷歌深度学习插件tensorflow2018-07-04 0
-
谷歌配屏幕智能音箱曝光,类似亚马逊Echo Show2018-08-31 0
-
好奇~!谷歌的 Edge TPU 专用 ASIC 旨在将机器学习推理能力引入边缘设备2019-03-05 0
-
科研人员提出可加速AI的计算与存储器混合技术吗2020-05-21 0
-
一种基于聚类和竞争克隆机制的多智能体免疫算法2021-12-29 0
-
英特尔与谷歌合作 加速进军智能手机领域2011-09-15 321
-
谷歌机器学习获重大突破2016-01-29 715
-
谷歌加码人工智能 新设一家实验室意在深度学习_人工智能,生物识别,深度学习2016-11-23 411
-
谷歌聚焦人工智能,以机器学习为主,确认在中国招募人才2017-11-30 708
-
DeepMind携手Unity,加速机器学习和人工智能研究2018-09-28 1269
-
谷歌云人工智能为机器学习提供帮助分析2020-11-16 1526
-
谷歌模型框架是什么软件?谷歌模型框架怎么用?2024-03-01 210
全部0条评论

快来发表一下你的评论吧 !
