

一文读懂处理器流水线
处理器/DSP
描述
本文将讨论处理器的一个重要的基础知识:“流水线”。熟悉计算机体系结构的读者一定知道,言及处理器微架构,几乎必谈其流水线。处理器的流水线结构是处理器微架构最基本的一个要素,犹如汽车底盘对于汽车一般具有基石性的作用,它承载并决定了处理器其他微架构的细节。本文将简要介绍处理器的一些常见流水线结构,让您真正读懂处理器流水线。
1 从经典的五级流水线说起
流水线的概念来源于工业制造领域,以汽车装配为例来解释流水线的工作方式,假设装配一辆汽车需要四个步骤:
第一步冲压:制作车身外壳和底盘等部件。
第二步焊接:将冲压成形后的各部件焊接成车身。
第三步涂装:将车身等主要部件清洗、化学处理、打磨、喷漆和烘干。
第四步总装:将各部件(包括发动机和向外采购的零部件)组装成车。
汽车装配则同时对应需要冲压、焊接、涂装和总装四个工人。最简单的方法是一辆汽车依次经过上述四个步骤装配完成之后,下一辆汽车才开始进行装配,最早期的工业制造就是采用的这种原始的方式,即同一时刻只有一辆汽车在装配。不久之后人们发现,某个时段中一辆汽车在进行装配时,其它三个工人都处于闲置状态,显然这是对资源的极大浪费,于是思考出能有效利用资源的新方法,即在第一辆汽车经过冲压进入焊接工序的时候,立刻开始进行第二辆汽车的冲压,而不是等到第一辆汽车经过全部四个工序后才开始,这样在后续生产中就能够保证四个工人一直处于运行状态,不会造成人员的闲置。这样的生产方式就好似流水川流不息,因此被称为流水线。
计算机体系结构教材中被提及最多的经典MIPS五级流水线如图1所示。在此流水线中一条指令的生命周期分为:
取指:
指令取指(Instruction Fetch)是指将指令从存储器中读取出来的过程。
译码:
指令译码(Instruction Decode)是指将存储器中取出的指令进行翻译的过程。经过译码之后得到指令需要的操作数寄存器索引,可以使用此索引从通用寄存器组(Register File,Regfile)中将操作数读出。
执行:
指令译码之后所需要进行的计算类型都已得知,并且已经从通用寄存器组中读取出了所需的操作数,那么接下来便进行指令执行(Instruction Execute)。指令执行是指对指令进行真正运算的过程。譬如,如果指令是一条加法运算指令,则对操作数进行加法操作;如果是减法运算指令,则进行减法操作。
在“执行”阶段的最常见部件为算术逻辑部件运算器(Arithmetic Logical Unit,ALU),作为实施具体运算的硬件功能单元。
访存:
存储器访问指令往往是指令集中最重要的指令类型之一,访存(Memory Access)是指存储器访问指令将数据从存储器中读出,或者写入存储器的过程。
写回:
写回(Write-Back)是指将指令执行的结果写回通用寄存器组的过程。如果是普通运算指令,该结果值来自于“执行”阶段计算的结果;如果是存储器读指令,该结果来自于“访存”阶段从存储器中读取出来的数据。
在工业制造中采用流水线可以提高单位时间的生产量,同样在处理器中采用流水线设计也有助于提高处理器的性能。以上述的五级流水线为例,由于前一条指令在完成了“取指”进入“译码”阶段后,下一条指令马上就可以进入“取指”阶段,依次类推,如图2所示,如果流水线没有停顿,理论上可以取得每个时钟周期都完成一条指令的性能。
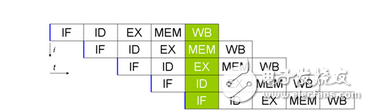
图1 MIPS五级流水线结构图
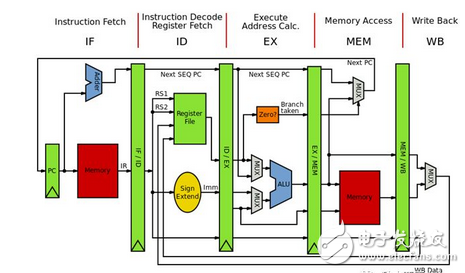
图2 MIPS五级流水线运行图
2 可不可以不要流水线——流水线和状态机的关系
言及处理器微架构,几乎必谈流水线。那么,我们能否挑战一下权威提出一个有意思的问题:处理器难道就一定需要流水线吗?可否不要流水线呢?
在回答这个问题之前,我们先探讨下流水线的本质:
流水线并不限于处理器设计,在所有的ASIC电路实现中都广泛采用流水线的思想。流水线本质上可以理解为是一种以面积换性能(Trade Area for Performance)、以空间换时间(Trade Space for Timing)的手段。
譬如,以5级流水线为例,其增加了5组寄存器,每一个流水线级数内部都有各自的组合逻辑数据通路,彼此之间没有复用资源,因此,其面积开销是比较大的,但是由于可以让不同的流水线级数同时做不同的事情,而达到流水的效果,提高了性能,优化了时序,增加了吞吐率。
与流水线相对应的另外一种策略是状态机,状态机是流水线的“取反”,同样在所有的ASIC电路实现中都广泛采用。状态机本质上可以理解为是一种以性能换面积(Trade Performance for Area)、以时间换空间(Trade Timing for Space)的手段。
“流水线”和“状态机”的关系,还有一种说法称之为“展开”和“折叠”的关系。本质上都是一种电路设计时,选择侧重时间(性能)还是空间(面积)的一种取舍。
通过上述分析,假设处理器不采用流水线,而是使用一个状态机来完成,则需要多个时钟周期才能完成一条指令的所有操作,每个时钟周期完成状态机的一个状态(譬如分别为取指、译码、执行、访存和写回)。通过使用状态机,可以省掉上述流水线中的寄存器开销,还可以复用组合逻辑数据通路,因此面积开销比较小,但是每条指令都需要5个周期才能完成,吞吐率和性能很差。
谈及此处,就不得不提及8位单片机时代的传奇老炮儿8051内核,早期原始的8051内核微架构就是采用了类似状态机的实现方式而不是流水线。因此,回到最开始我们提出的问题,处理器可否不要流水线,答案是:当然可以,传奇老炮儿8051内核就没有流水线。
所以说从功能能上来讲,处理器完全可以不使用流水线,而使用状态机的方式来实现,只不过由于这种方式性能比较差,在现代处理器设计中比较罕见而已。
3 深处种菱浅种稻,不深不浅种荷花——流水线的深度
流水线的级数(又称深度)多少最好呢?要回答这个问题,就需要了解流水线的深浅各自的优劣。此处有一个常见面试题,题目便是:处理器的流水线是否越深越好?在此我们给出答案:
早期的经典流水线是5级流水线,分别为取指、译码、执行、访存和写回。现代的处理器往往具有极深的流水线级数,譬如高达十几级,或者二十几级的深度。流水线就像一根黄瓜,切五刀下去得到的每一截长度和切二十到下去得到的每一截长度肯定是不一样的。当流水线的级数越多,那么意味着流水线被切的很细,每一级流水线内容纳的硬件逻辑便越少,熟悉数字同步电路设计的读者应该比较熟悉,在两级寄存器(每一级流水线由寄存器组成)之间的硬件逻辑越少,则意味能够运行到更高的主频。因此现代的处理器流水线极深主要是由于处理器追求高频的指标所驱使,高端的ARM Cortex-A系列由于有十几级的流水线,所以能够运行到高达2GHz的主频,而Intel的x86处理器甚至采用几十级的流水线深度将主频推到3-4GHz的高度。主频越高也意味着流水线的吞吐率越高从而性能越高,这是流水线加深的正面意义。
由于每一级流水线都由寄存器组成,那么意味着更多的流水线级数要消耗更多的寄存器,也意味着更多的面积开销。这是流水线加深的负面意义。
同时流水线越深,由于每一级流水线需要进行握手,流水线最后一级的反压信号可能会一直串扰到最前一级造成严重的时序问题,需要使用一些比较高级的技巧来解决此类反压时序问题。这是流水线加深的负面意义。
较深的处理器流水线还有一个问题,由于在流水线的取指令阶段无法得知条件跳转的结果是跳还是不跳,因此只能进行预测,而到了流水线的末端才能够通过实际的运算得知该分支是真的该跳还是不该跳,如果发现真实的结果(譬如该跳)与之前预测的结果(譬如预测为不跳)不相符,则意味着预测失败,需要将所有预取的错误指令流全部丢弃掉,而重新取正确的指令流,这个过程叫做流水线冲刷(Pipeline Flush),虽然可以使用分支预测器来保证前期的分支预测尽可能的准确,但是也无法做到万无一失。那么,流水线的深度越深,则意味着已经预取了很多的错误指令流,需要将其全部抛弃然后重启,不仅白白的浪费了功耗,还造成了性能的损失。流水线越深则意味着浪费和损失越严重,流水线越浅则浪费和损失越少。这是流水线加深的另一个主要的负面意义。
综上,所谓深处种菱浅种稻,不深不浅种荷花,流水线的不同深度皆有其优缺点,需要根据不同的应用背景合理地进行选择。
由于处理器流水线深浅的不同优劣,根据不同的应用场景,当今处理器的流水线深度在向着两个不同的极端发展,一方面级数越来越深,另一方面又越来越浅,下面我们结合不同的商用处理器例子予以探讨。
-
基于FPGA的移位寄存器流水线结构FFT处理器2012-08-18 0
-
FPGA中的流水线设计2020-10-26 0
-
如何设计一个基于FPGA移位寄存器流水线结构的FFT处理器2021-04-28 0
-
ARM流水线有什么作用2021-07-16 0
-
ARM架构系列中的流水线设计2022-04-11 0
-
现代RISC中的流水线技术2023-03-01 0
-
流水线结构的高效SAR快视成像处理器2009-05-08 539
-
周期精确的流水线仿真模型2009-12-31 1120
-
什么是流水线技术2010-02-04 3730
-
流水线操作,应用处理器,应用处理器的结构和原理是什么?2010-03-26 1187
-
数字信号处理器结构2_流水线2018-04-09 493
-
各种流水线特点及常见流水线设计方式2021-07-05 6256
-
CPU流水线的问题2022-09-22 1341
-
什么是流水线 Jenkins的流水线详解2023-05-17 642
-
什么是流水线?ARM处理器流水线简析2023-09-05 1193
全部0条评论

快来发表一下你的评论吧 !
