

文本数据分析:文本挖掘还是自然语言处理?
电子说
描述
数据分析师Seth Grimes曾指出“80%的商业信息来自非结构化数据,主要是文本数据”,这一表述可能夸大了文本数据在商业数据中的占比,但是文本数据的蕴含的信息价值毋庸置疑。KDnuggets的编辑、机器学习研究者和数据科学家Matthew Mayo就在网站上写了一个有关文本数据分析的文章系列。本文是该系列的第一篇,主要讲述了文本数据分析的大致步骤和框架。以下是论智对原文的编译。
虽然NLP和文本挖掘不是一回事儿,但它们仍是紧密相关的:它们处理同样的原始数据类型、在使用时还有很多交叉。下面我们就来描述一下这些任务的处理步骤。
如今的文本数据量非常之大,许多都是从日常生活中产生的,其中既有结构化的,也有半结构化甚至混乱的数据。我们对此能做什么?事实上,能做的有很多,这取决于你的目标是什么。
文本挖掘还是自然语言处理?
自然语言处理(NLP)关注的是人类的自然语言与计算机设备之间的相互关系。NLP是计算机语言学的重要方面之一,它同样也属于计算机科学和人工智能领域。而文本挖掘和NLP的存在领域类似,它关注的是识别文本数据中有趣并且重要的模式。
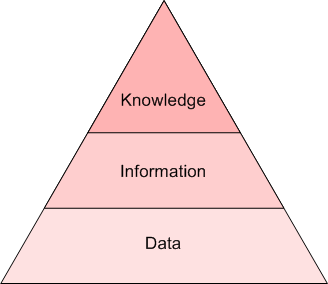
但是,这二者仍有不同。首先,这两个概念并没有明确的界定(就像“数据挖掘”和“数据科学”一样),并且在不同程度上二者相互交叉,具体要看与你交谈的对象是谁。我认为通过洞见级别来区分是最容易的。如果原始文本是数据,那么文本挖掘就是信息,NLP就是知识,也就是语法和语义的关系。下面的金字塔表示了这种关系:
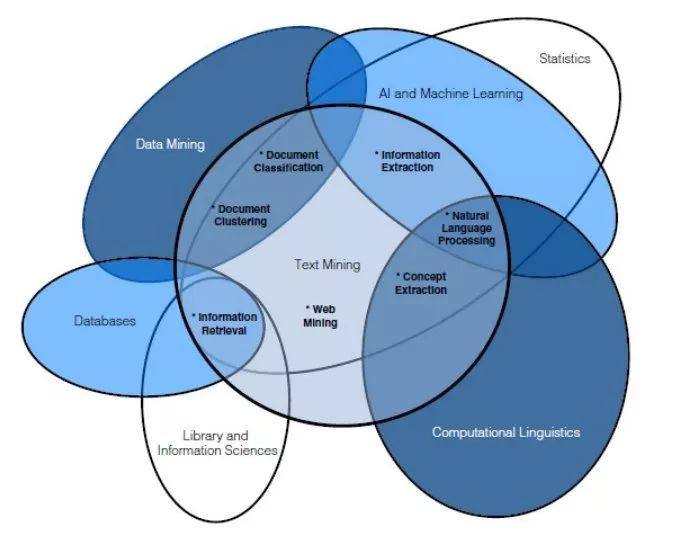
另一种区分这两个概念的方法是用下方的韦恩图区分,其中也涉及其他相关概念,从而能更好地表示它们之间重叠的关系。
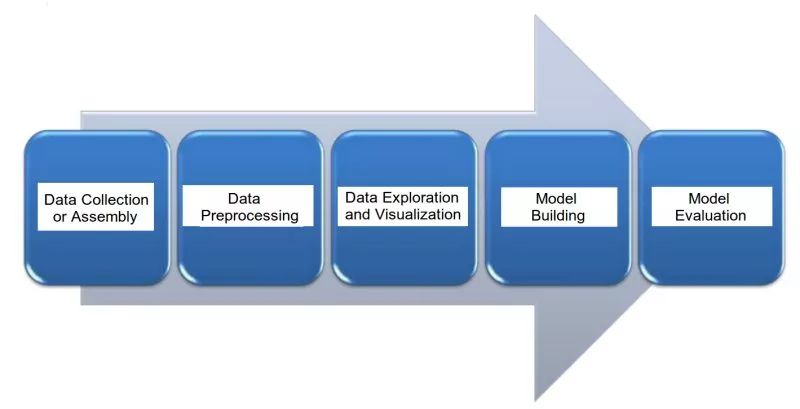
我们的目的并不是二者绝对或相对的定义,重要的是要认识到,这两种任务下对数据的预处理是相同的。
努力消除歧义是文本预处理很重要的一个方面,我们希望保留原本的含义,同时消除噪音。为此,我们需要了解:
关于语言的知识
关于世界的知识
结合知识来源的方法
除此之外,下图所示的六个因素也加大了文本数据处理的难度,包括非标准的语言表述、断句问题、习惯用语、新兴词汇、常识以及复杂的名词等等。

文本数据科学任务框架
我们能否为文本数据的处理制作一个高效并且通用的框架呢?我们发现,处理文本和处理其他非文本的任务很相似,可以查看我之前写的KDD Process作为参考。
以下就是处理文本任务的几大主要步骤:
1.数据收集
获取或创建语料库,来源可以是邮箱、英文维基百科文章或者公司财报,甚至是莎士比亚的作品等等任何资料。
2.数据预处理
在原始文本语料上进行预处理,为文本挖掘或NLP任务做准备
数据预处理分为好几步,其中有些步骤可能适用于给定的任务,也可能不适用。但通常都是标记化、归一化和替代的其中一种。
3.数据挖掘和可视化
无论我们的数据类型是什么,挖掘和可视化是探寻规律的重要步骤
常见任务可能包括可视化字数和分布,生成wordclouds并进行距离测量
4.模型搭建
这是文本挖掘和NLP任务进行的主要部分,包括训练和测试
在适当的时候还会进行特征选择和工程设计
语言模型:有限状态机、马尔可夫模型、词义的向量空间建模
机器学习分类器:朴素贝叶斯、逻辑回归、决策树、支持向量机、神经网络
序列模型:隐藏马尔可夫模型、循环神经网络(RNN)、长短期记忆神经网络(LSTMs)
5.模型评估
模型是否达到预期?
度量标准将随文本挖掘或NLP任务的类型而变化
即使不做聊天机器人或生成模型,某种形式的评估也是必要的
在下篇连载中,我将为大家带来在文本数据任务中,对数据预处理的框架的进一步探索,敬请关注。
-
自然语言处理怎么最快入门?2018-11-28 0
-
python自然语言2018-05-02 0
-
NLPIR语义分析是对自然语言处理的完美理解2018-10-19 0
-
灵玖软件:NLPIR智能挖掘系统专注中文处理2019-01-21 0
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
NLPIR平台实现文本挖掘的一站式应用2019-11-07 0
-
什么是自然语言处理2021-09-08 0
-
自然语言处理技术可助力机器学习加快挖掘数据2020-04-11 1683
-
自然语言处理(NLP)的学习方向2020-07-06 12545
-
自然语言处理的图像文本建模相关研究及分析2021-03-24 482
-
NLA自然语言分析,助力解决数据分析的难题2022-06-02 362
-
自然语言处理包括哪些内容 自然语言处理技术包括哪些2023-08-03 3881
-
自然语言理解问答对话文本数据,赋予计算机智能交流的能力2023-08-07 413
-
自然语言处理和人工智能的区别2023-08-28 928
全部0条评论

快来发表一下你的评论吧 !
