

从深度学习的原理和基础出发阐述了深度学习的局限性
电子说
描述
在过去几十年中,深度学习作为人工智能领域的头号种子选手,成为了激动人心的科技创新。在诸如语音识别、癌症检测等对于传统软件模型难以解决的领域中,深度学习已经初露锋芒。
深度学习的原理经常被用来与人类学习的过程相类比,专家们相信深度学习过程将会更快,更深入的延伸至更多的领域中。在某些情况下,人们会担心深度学习会威胁人类在社会和经济生活中的关键地位,造成诸如失业甚至是人类被机器奴役的后果。
毫无疑问,机器学习和深度学习对某些任务而言是十分有效的,然而它并不是可以解决所有问题、凌驾于所有科技之上的万能钥匙。事实上,相比于过度炒作夸大的概念,仍有许多的制约和挑战使得该技术在某些方面仍不足以和人类,甚至无法达到人类孩童的能力。
让我们回忆儿时的童年经历:第一次接触超级玛丽时只玩了几个小时便初步形成了粗浅的关于平台游戏(platform game)的概念。下次玩到类似的游戏(诸如prince of persia, sonic hedgehog, crash bandicoot 或是donkye kong country)时,便可以将之前在超级玛丽游戏中的实战经验应用于它们。如果之后它们升级成了3d版本(正如90年代中期出现的),也可以毫不费力的上手。同时,也可以轻而易举的将现实生活中的经验应用于游戏之中,遇到深坑时我马上知道要操作马里奥跳过它,遇到有刺的植物时,我马上知道要避开。
我们算不上优秀的游戏玩家,但对于深度学习算法而言,完成上述过程却充满了挑战,即使是最聪明的游戏算法也要从零开始学起。
人类可以通过抽象、类比、演绎,对不同的概念进行借鉴和学习,达到举一反三的效果。深度学习的算法却无法做到如此,它需要大量精准的训练来实现。
在最近的一篇题为“深度学习的客观评价”一文中,前Uber人工智能领导,纽约大学教授Gray Marcus讲述了深度学习遇到的限制与挑战,他从深度学习的原理和基础出发阐述了深度学习的局限性,但也对未来面对的挑战表达了殷切的期许。
深度学习的原理
通过对人脑处理信息时所采用方法的抽象总结和模拟,提出了神经网络的概念。未经处理的数据(图像,声音信息或者文字信息)被输入至输出层的“输入单元”;输入信息经过一定的映射输出至输出层的“输出节点”。映射的方法根据用户定义,比如说,输入的图画中有猫咪,输入的声音片段中有“hello”。深度学习是一种通过多层神经网络对信息进行抽取和表示,并实现分类、检测等复杂任务的算法架构。深度神经网络作为深度学习算法的核心组成部分,在输入与输出层之间包含有多层隐藏层,使得算法可以完成复杂的分类关系。
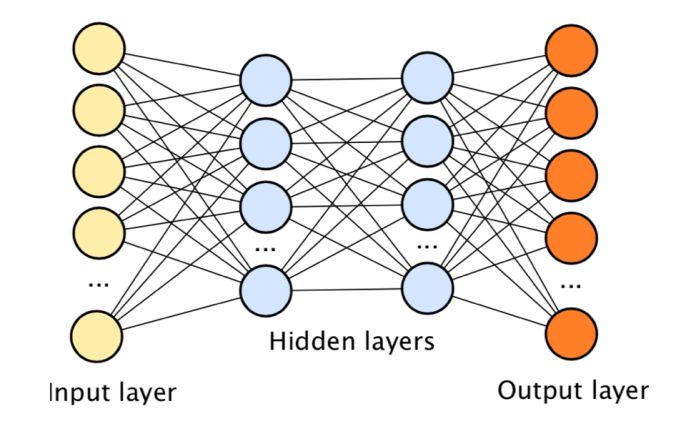
图:深度神经网络结构示意图
深度学习算法需要大量的数据做训练,比如说如果你想从图片中准确的识别出是否包含“猫咪”,那么你需要事先用成千上万张图片来训练它。训练的数据量越大,模型的准确性越高。大公司之间正在不惜一切代价的争夺数据,甚至愿意免费提供服务以换取数据。拥有越多的数据,就拥有越高的算法准确性和越有效的服务,并将吸引更多的用户,从而在竞争中形成良性循环。
深度学习需要大量的数据燃料
如果在一个拥有无限数据和计算资源的世界中,除了机器学习之外的其他技术便没有存在的必要性。但显而易见的是现实世界并非如此。机器学习算法永远不可能是全面的,必须要通过插补或推演来对它从未听到过的声音或看到过的图像来给出可能的答案。
对于深度学习算法来说,缺乏“下定义”的过程,既:从特殊到一般的提炼过程,好的效果必须依托于成千上万甚至更多的训练样本之上。
那么如果不能进行大量有效的训练,会发生什么?答案是:令人瞠目结舌的错误!错误的算法可能无法分清楚来福抢和直升飞机,大猩猩和人类。
深度学习错误识别的例子
对于数据的过度依赖也带来了使用安全性上的问题。Marcus说过:“深度学习非常善于对特定领域的绝大多数现象作出判断,另一方面它也会被愚弄。” 这便涉及到对抗样本对于深度学习算法的攻击。通过对交通标志很小的涂改,深度学习算法就会误判停止与限速的交通标记,还有可能无法区分沙堆与肉色针织物。
深度学习并不深刻
深度学习善于建立输入与输出之间的映射关系,却不善于总结发现其中的内在物理联系。事实上,“深度”这个概念,只是对于多层隐藏层的架构而言,并非指该算法对事物本身的理解有多么深入。Marcus认为:“通过此种算法建构的系统,并不能总结并抽象理解诸如正义,民主,干预之类的概念”。
返回到一开始文章中提到的游戏案例,通过大量的训练,深度学习算法可以打败最好的人类超级玛丽玩家,然而这并不代表人工智能对于游戏有着和人一样的领悟能力,当一个棒球砸向马里奥时,游戏玩家都知道通过跳起来躲避,而人工智能只懂得傻傻往前跑,直到被棒球砸中后背。通过反复的试错实验,它能够保证最后的胜率,但是稍微升级以下游戏或改变版本,人工智能却必须从头学起。
Marcus的文章中提到谷歌深度学习中的应用案例:在mastering of atari game breakout中,在游戏进行240分钟后,赢得游戏胜利的最佳方法是在墙上打隧道。然而,它并不明白墙,或者隧道是什么。它只是通过反复的试错实验直到,这样做可以在最短的时间内获得最高的分数。
深度学习是算法黑箱
依据规则而写的程序给出的执行结果,可以被追述到最后一个if else。机器学习和深度学习的算法却不能。这种不透明的性质被定义为“黑箱”问题。深度学习算法在几千个节点之间建立映射,并给出输入与输出之间的关系。即使是开发出此算法的亲生工程师也常常会对结果困惑不解。当深度学习应用于容错率较高的系统时,这个缺点看起来似乎无关紧要。但是想象一下,如果是应用于法庭判决嫌疑人的命运,或者医疗中决定对患者的处理之类的领域之中,任何微小的错误都会导致不可逆转的致命结果。
Marcus认为:”深度学习算法中的透明性问题至今无解,并且严重阻碍了它向金融交易、医疗诊断等人们看重并希望了解缘由的领域发展。“
基于对大量数据训练而得出的结果,使深度学习的方法常常表现出某些偏见,比如:男人比女人的收入更高,白人比黑人更具有外貌优势。这种错误在程序的调试阶段很难发现,却常常会由于其给出的结果,引起社会舆论的广泛关注和讨论。
深度学习注定会失败吗?
当然不是!但是需要现实检验。
Marcus认为:“深度学习可以作为简化复杂问题,基于较大的数据量,建立输入与输出之间映射关系的完美途径“。通过合理选择训的方法和足够的训练样本,深度学习可以作为一种高效的分类数据的手段。但是它并不拥有魔术般的力量,要认识清楚它的应用局限性和有效性。Marcus 还认为,深度学习还需要和其他的技术结合发展,比如说普通基于规则的编程或者其他的人工智能技术,比如强化学习。Starmind's Pascal Kaufmann 则认为,通过神经科学,从而实现人工智能能够像人类一样学习,也许也是行之有效的手段。
最后以Marcus的话来结束全文,并引出对深度学习何去何从的思考:“深度学习不会也不应该消失,但是以五年为期来检验深度学习的能与不能,并让社会各界清醒地接受和认识它的能力与局限性,无论对于技术本身还是社会的发展都具有重要的意义!”
-
34063的局限性2011-06-12 0
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 0
-
运算放大器的精度局限性是什么2021-03-11 0
-
基于FPGA的神经网络的性能评估及局限性2021-04-30 0
-
异常检测的深度学习:一项调查(翻译)精选资料分享2021-07-12 0
-
深度学习存在哪些问题?2021-10-14 0
-
深度学习模型是如何创建的?2021-10-27 0
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 0
-
深度学习引发人工智能浪潮同时也加速“AI泡沫”的到来2018-07-31 8818
-
如何使用深度学习进行视频行人目标检测2018-11-19 1255
-
近三年技术和产业发展的回顾,再论“深度学习已死2019-01-14 3389
-
对于深度学习优缺点的分析与其应用的局限性2021-03-05 6396
-
什么是深度学习算法?深度学习算法的应用2023-08-17 1439
-
深度学习框架是什么?深度学习框架有哪些?2023-08-17 1704
-
深度学习框架和深度学习算法教程2023-08-17 696
全部0条评论

快来发表一下你的评论吧 !
