

性能优化主要围绕CPU、GPU和内存三大方面进行
电子说
描述
项目的性能优化主要围绕CPU、GPU和内存三大方面进行。本文和大家分享内存方面的优化心得。
无论是游戏还是VR应用,内存管理都是其研发阶段的重中之重。然而,在我们测评过的大量项目中,90%以上的项目都存在不同程度的内存使用问题。就目前基于Unity引擎开发的移动游戏和移动VR游戏而言,内存的开销无外乎以下三大部分:
资源内存占用;
引擎模块自身内存占用;
托管堆内存占用。
如果您的项目存在内存问题,一定逃不出以上三种情况。今天,我们就这三种情况逐一进行解释。
1、资源内存占用
在一个较为复杂的大中型项目中,资源的内存占用往往占据了总体内存的70%以上。因此,资源使用是否恰当直接决定了项目的内存占用情况。一般来说,一款游戏项目的资源主要可分为如下几种:纹理(Texture)、网格(Mesh)、动画片段(AnimationClip)、音频片段(AudioClip)、材质(Material)、着色器(Shader)、字体资源(Font)以及文本资源(Text Asset)等等。其中,纹理、网格、动画片段和音频片段则是最容易造成较大内存开销的资源。
一、纹理
纹理资源可以说是几乎所有游戏项目中占据最大内存开销的资源。一个6万面片的场景,网格资源最大才不过10MB,但一个2048x2048的纹理,可能直接就达到16MB。因此,项目中纹理资源的使用是否得当会极大地影响项目的内存占用。
那么,纹理资源在使用时应该注意哪些地方呢?
(1) 纹理格式
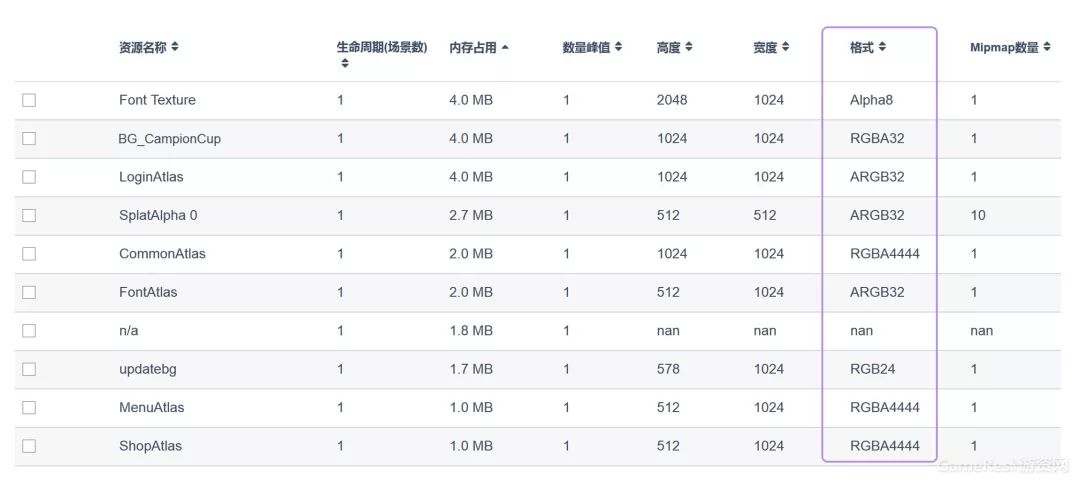
纹理格式是研发团队最需要关注的纹理属性。因为它不仅影响着纹理的内存占用,同时还决定了纹理的加载效率。一般来说,我们建议开发团队尽可能根据硬件的种类选择硬件支持的纹理格式,比如Android平台的ETC、iOS平台的PVRTC、Windows PC上的DXT等等。因此,我们在UWA测评报告中,将纹理格式进行详细罗列,以便开发团队进行快速查找,一步定位。
在使用硬件支持的纹理格式时,你可能会遇到以下几个问题:
色阶问题
由于ETC、PVRTC等格式均为有损压缩,因此,当纹理色差范围跨度较大时,均不可避免地造成不同程度的“阶梯”状的色阶问题。因此,很多研发团队使用RGBA32/ARGB32格式来实现更好的效果。但是,这种做法将造成很大的内存占用。比如,同样一张1024x1024的纹理,如果不开启Mipmap,并且为PVRTC格式,则其内存占用为512KB,而如果转换为RGBA32位,则很可能占用达到4MB。所以,研发团队在使用RGBA32或ARGB32格式的纹理时,一定要慎重考虑,更为明智的选择是尽量减少纹理的色差范围,使其尽可能使用硬件支持的压缩格式进行储存。
ETC1 不支持透明通道问题
在Android平台上,对于使用OpenGL ES 2.0的设备,其纹理格式仅能支持ETC1格式,该格式有个较为严重的问题,即不支持Alpha透明通道,使得透明贴图无法直接通过ETC1格式来进行储存。对此,我们建议研发团队将透明贴图尽可能分拆成两张,即一张RGB24位纹理记录原始纹理的颜色部分和一张Alpha8纹理记录原始纹理的透明通道部分。然后,将这两张贴图分别转化为ETC1格式的纹理,并通过特定的Shader来进行渲染,从而来达到支持透明贴图的效果。该种方法不仅可以极大程度上逼近RGBA透明贴图的渲染效果,同时还可以降低纹理的内存占用,是我们非常推荐的使用方式。
当然,目前已经有越来越多的设备支持了OpenGL ES 3.0,这样Android平台上你可以进一步使用ETC2甚至ASTC,这些纹理格式均为支持透明通道且压缩比更为理想的纹理格式。如果你的游戏适合人群为中高端设备用户,那么不妨直接使用这两种格式来作为纹理的主要存储格式。
(2)纹理尺寸
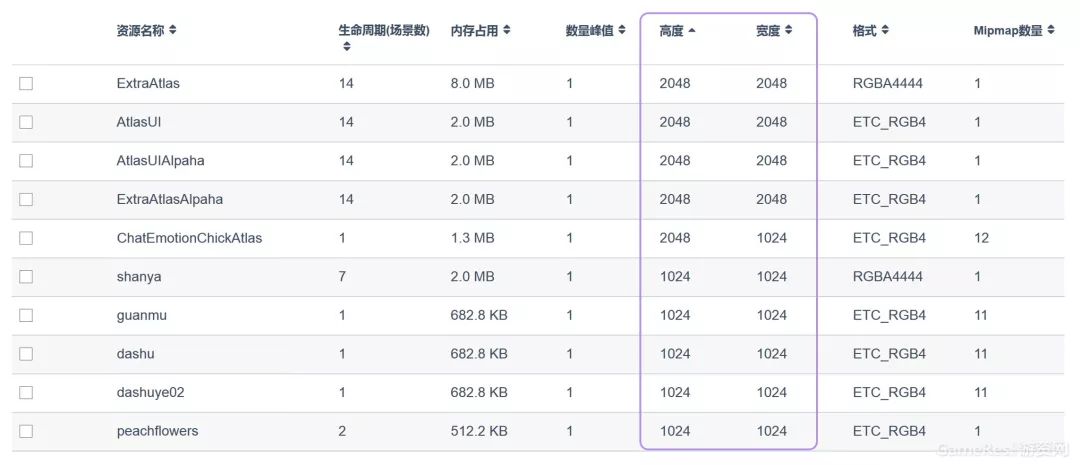
一般来说,纹理尺寸越大,则内存占用越大。所以,尽可能降低纹理尺寸,如果512x512的纹理对于显示效果已经够用,那么就不要使用1024x1024的纹理,因为后者的内存占用是前者的四倍。因此,我们在UWA测评报告中,将纹理的尺寸进行详细展示,以便开发团队进行快速检测。
(3) Mipmap功能
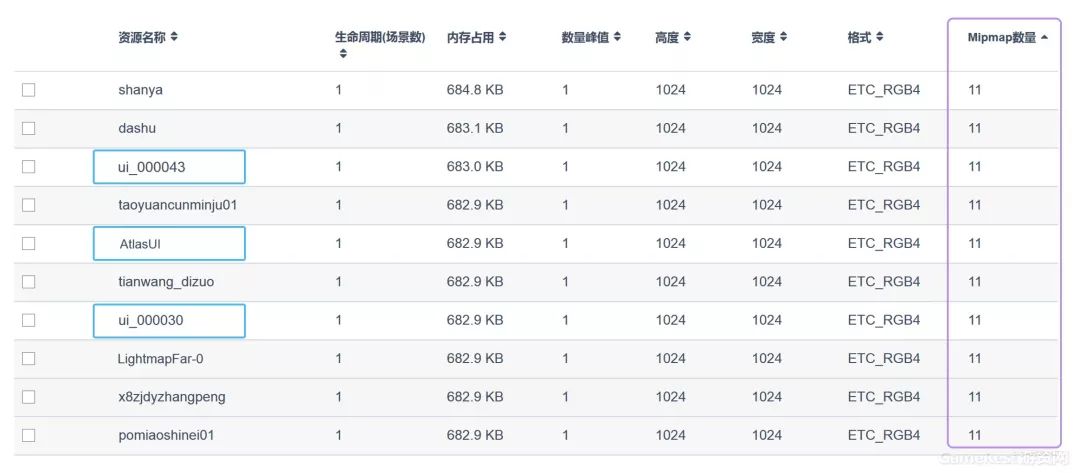
Mipmap旨在有效降低渲染带宽的压力,提升游戏的渲染效率。但是,开启Mipmap会将纹理内存提升1.33倍。对于具有较大纵深感的3D游戏来说,3D场景模型和角色我们一般是建议开启Mipmap功能的,但是在我们的测评项目中,经常会发现部分UI纹理也开启了Mipmap功能。这其实就没有必要的,绝大多数UI均是渲染在屏幕最上层,开启Mipmap并不会提升渲染效率,反倒会增加无谓的内存占用。因此,建议研发团队在UWA的测评报告中通过Mipmap一项进行排序,详细检测开启Mipmap功能的资源是否为UI资源。
(4) Read & Write
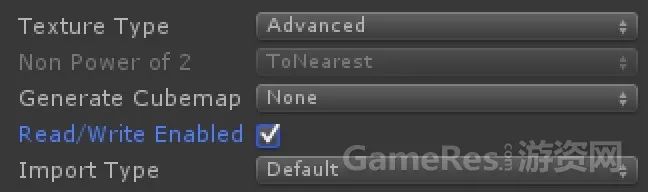
一般情况下,纹理资源的“Read & Write”功能在Unity引擎中是默认关闭的。但是,我们仍然在项目深度优化时发现了不少项目的纹理资源会开启该选项。对此,我们建议研发团队密切关注纹理资源中该选项的使用,因为开启该选项将会使纹理内存增大一倍。
二、网格
网格资源在较为复杂的游戏中,往往占据较高的内存。对于网格资源来说,它在使用时应该注意哪些方面呢?
Normal、Color和Tangent
在我们深度优化过的大量项目中,Mesh资源的数据中经常会含有大量的Color数据、Normal数据和Tangent数据。这些数据的存在将大幅度增加Mesh资源的文件体积和内存占用。其中,Color数据和Normal数据主要为3DMax、Maya等建模软件导出时设置所生成,而Tangent一般为导入引擎时生成。
更为麻烦的是,如果项目对Mesh进行Draw Call Batching操作的话,那么将很有可能进一步增大总体内存的占用。比如,100个Mesh进行拼合,其中99个Mesh均没有Color、Tangent等属性,剩下一个则包含有Color、Normal和Tangent属性,那么Mesh拼合后,CombinedMesh中将为每个Mesh来添加上此三个顶点属性,进而造成很大的内存开销。正因如此,我们在UWA测评报告中为每个Mesh展示了其Normal、Color和Tangent属性的具体使用情况,研发团队可以直接针对每种属性进行排序查看,直接定位出现冗余数据的资源。
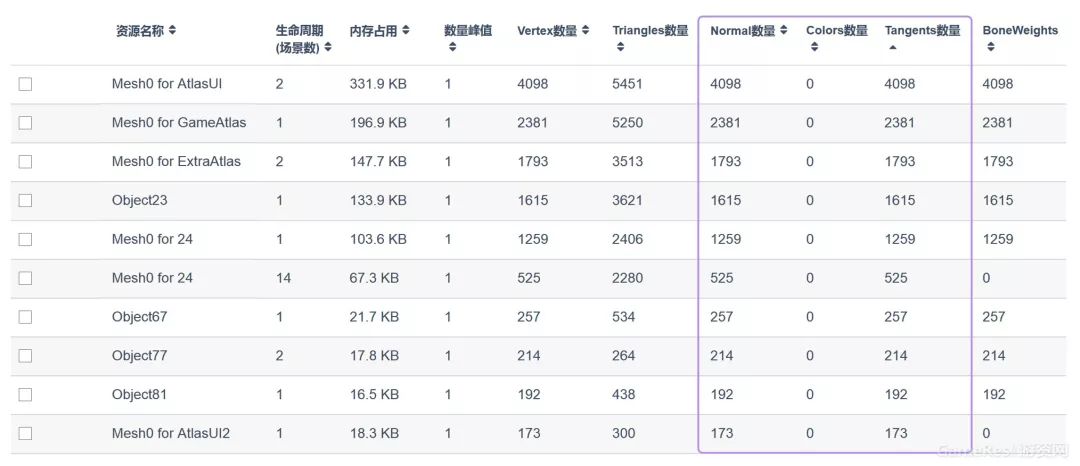
一般来说这些数据主要为Shader所用,来生成较为酷炫的效果。所以,建议研发团队针对项目中的网格资源进行详细检测,查看该模型的渲染Shader中是否需要这些数据进行渲染。
限于篇幅,我们今天只针对纹理和网格资源进行详细介绍,对于动画片段、音频片段等其他资源,建议您直接通过UWA测评报告中进行查看。
2、引擎模块自身占用
引擎自身中存在内存开销的部分纷繁复杂,可以说是由巨量的“微小”内存所累积起来的,比如GameObject及其各种Component(最大量的Component应该算是Transform了)、ParticleSystem、MonoScript以及各种各样的模块Manager(SceneManager、CanvasManager、PersistentManager等)...
一般情况下,上面所指出的引擎各组成部分的内存开销均比较小,真正占据较大内存开销的是这两处:WebStream 和 SerializedFile。其绝大部分的内存分配则是由AssetBundle加载资源所致。简单言之,当您使用new WWW或CreateFromMemory来加载AssetBundle时,Unity引擎会加载原始数据到内存中并对其进行解压,而WebStream的大小则是AssetBundle原始文件大小 + 解压后的数据大小 + DecompressionBuffer(0.5MB)。同时,由于Unity 5.3版本之前的AssetBundle文件为LZMA压缩,其压缩比类似于Zip(20%-25%),所以对于一个1MB的原始AssetBundle文件,其加载后WebStream的大小则可能是5~6MB,因此,当项目中存在通过new WWW加载多个AssetBundle文件,且AssetBundle又无法及时释放时,WebStream的内存可能会很大,这是研发团队需要时刻关注的。

对于SerializedFile,则是当你使用LoadFromCacheOrDownload、CreateFromFile或new WWW本地AssetBundle文件时产生的序列化文件。
对于WebStream和SerializedFile,你需要关注以下两点:
是否存在AssetBundle没有被清理干净的情况。开发团队可以通过Unity Profiler直接查看其使用具体的使用情况,并确定Take Sample时AssetBundle的存在是否合理;
对于占用WebStream较大的AssetBundle文件(如UI Atlas相关的AssetBundle文件等),建议使用LoadFromCacheOrDownLoad或CreateFromFile来进行替换,即将解压后的AssetBundle数据存储于本地Cache中进行使用。这种做法非常适合于内存特别吃紧的项目,即通过本地的磁盘空间来换取内存空间。
3、托管堆内存占用
对于目前绝大多数基于Unity引擎开发的项目而言,其托管堆内存是由Mono分配和管理的。“托管” 的本意是Mono可以自动地改变堆的大小来适应你所需要的内存,并且适时地调用垃圾回收(Garbage Collection)操作来释放已经不需要的内存,从而降低开发人员在代码内存管理方面的门槛。
但是这并不意味着研发团队可以在代码中肆无忌惮地开辟托管堆内存,因为目前Unity所使用的Mono版本存在一个很严重的问题,即:Mono的堆内存一旦分配,就不会返还给系统。这意味着Mono的堆内存是只升不降的。举个例子,项目运行时,在场景A中开辟了60MB的托管堆内存,而到下一场景B时,只需要使用20MB的托管堆内存,那么Mono中将会存在40MB空闲的堆内存,且不会返还给系统。这是我们非常不愿意看到的现象,因为对于游戏(特别是移动游戏)来说,内存的占用可谓是寸土寸金的,让Mono毫无必要地锁住大量的内存,是一件非常浪费的事情。所以,我们在UWA测评报告中,为研发团队统计了测试过程中累积的函数堆内存分配量,大家只需要通过查看堆内存分配Top10的函数,即可快速对其底层代码实现进行查看,定位是否有分配不必要堆内存的代码存在。
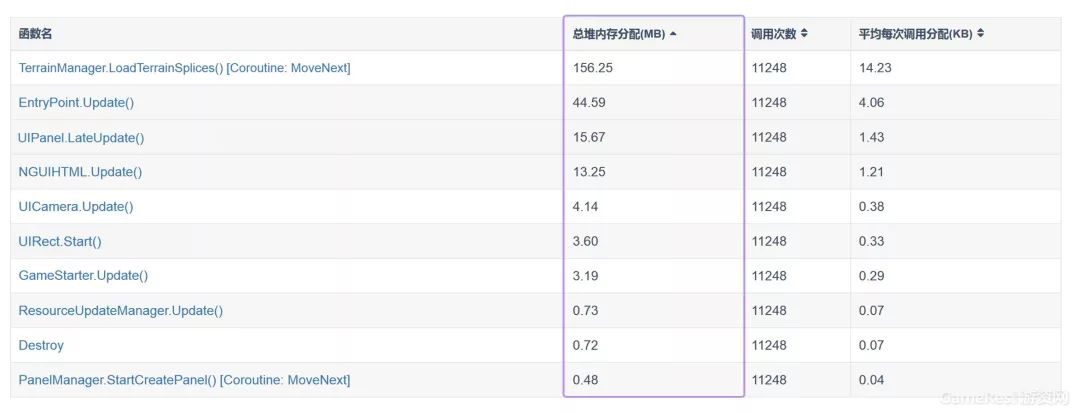
读到这里,你可能会产生这样的疑问:我知道了哪些函数的堆内存分配大了,但是我该如何去进一步定位不必要的堆内存呢?
这是我们经常遇到的问题,所以在我们的深度项目优化服务中,我们都会直接进驻到项目团队,现场查看项目代码并对问题代码进行定位。在经过了大量的深度检测后,我们发现用户不必要的堆内存分配主要来自于以下几个方面:
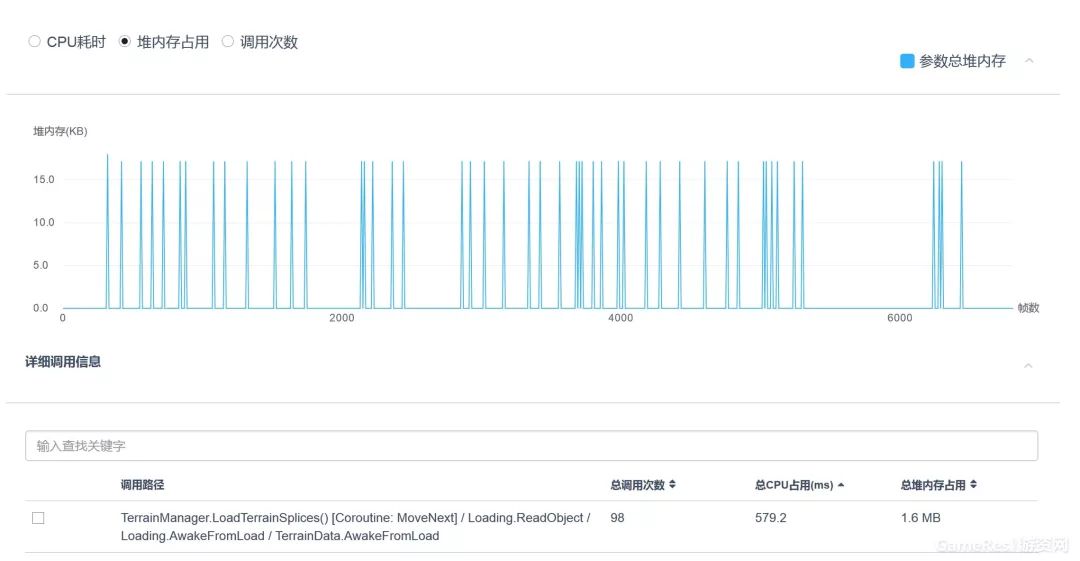
高频率地 New Class/Container/Array等。研发团队切记不要在Update、FixUpdate或较高调用频率的函数中开辟堆内存,这会对你的项目内存和性能均造成非常大的伤害。做个简单的计算,假设你的项目中某一函数每一帧只分配100B的堆内存,帧率是1秒30帧,那么1秒钟游戏的堆内存分配则是3KB,1分钟的堆内存分配就是180KB,10分钟后就已经分配了1.8MB。如果你有10个这样的函数,那么10分钟后,堆内存的分配就是18MB,这期间,它可能会造成Mono的堆内存峰值升高,同时又可能引起了多次GC的调用。在我们的测评项目中,一个函数在10分钟内分配上百MB的情况比比皆是,有时候甚至会分配上GB的堆内存。
Log输出。我们发现在大量的项目中,仍然存在大量Log输出的情况。建议研发团队对自身Log的输出进行严格的控制,仅保留关键Log,以避免不必要的堆内存分配。对此,我们在UWA测评报告中对Log的输出进行了详细的检测,不仅提供详细的性能开销,同时占用Log输出的调用路径。这样,研发团队可直接通过报告定位和控制Log的输出。
UIPanel.LateUpdate。这是NGUI中CPU和堆内存开销最大的函数。它本身只是一个函数,但NGUI的大量使用使它逐渐成为了一个不可忽视规则。该函数的堆内存分配和自身CPU开销,其根源上是一致的,即是由UI网格的重建造成。
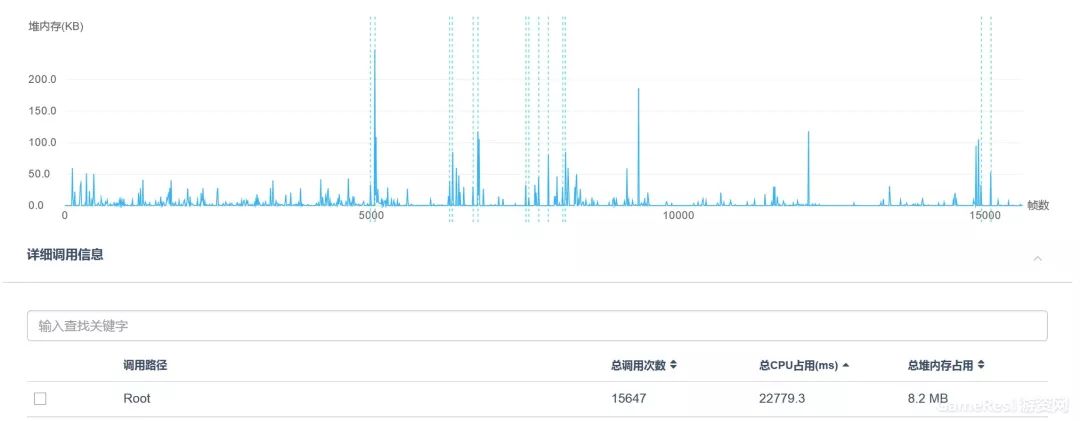
关于代码堆内存分配的注意点还有很多,比如String连接、部分引擎API(GetComponent)的使用等等,这些已经是老生常谈了,鉴于篇幅限制不在此处多作介绍,大家感兴趣可以Google自行搜索。
-
CPU内存或GPU内存进行分组方式实战2018-05-03 6503
-
GPU2016-01-16 0
-
谈GPU的作用、原理及与CPU、DSP的区别2015-11-04 0
-
CPU和GPU擅长和不擅长的地方2017-12-03 0
-
如何在vGPU环境中优化GPU性能2018-09-29 0
-
CPU,GPU,TPU,NPU都是什么2021-12-15 0
-
充分利用Arm NN进行GPU推理2022-04-11 0
-
一文带你详解芯片--SL8541e-系统性能优化2023-08-22 0
-
什么是GPU?GPU的主要作用和工作原理以及GPU和CPU的区别2017-09-13 2708
-
FPGA比CPU和GPU快的原因2018-04-02 95629
-
Linux CPU的性能应该如何优化2020-01-18 3119
-
Unity 3D优化三个的注意方面2020-03-13 3172
-
GPU竟比CPU有更大的内存带宽2021-08-04 2140
-
CPU、GPU和内存知识科普2023-11-13 851
-
为什么GPU比CPU更快?2024-01-26 609
全部0条评论

快来发表一下你的评论吧 !
