

大型人脸伪造视频数据集:用深度学习算法XceptionNet实现了“假脸”检测
电子说
描述
几个月前,深度学习算法deepfakes风靡社交网络,引发无数网友将无辜女明星的脸用于合成AV。事件曝光后后,Reddit立即封禁了所有帖子,但它产生的恶劣影响却令人担忧——如今随便一个普通人凭着一张GPU、一堆足够多的训练数据就能实现人脸替换,而且它的效果好到能超出人眼识别的范围,那么我们该如何防止它被滥用于损害他人名誉?又或者说,我们对以后在视频中看到的内容又该保有几分信任?
为了解决这个问题,近日慕尼黑工业大学(TUM)等高校的研究人员制作了一个名为FaceForensics的大型人脸伪造视频数据集,并成功用深度学习算法XceptionNet实现了“假脸”检测。以下是对论文部分内容的编译:
哪张脸是真实的脸?
摘要
随着计算机视觉和图像处理技术取得最新进展,现在我们已经能做到在视频中实时合成极其逼真的人脸。这项技术的背后是无限的应用空间,但其中的某些滥用行为却为我们拉响了安全警报,因此开发一个可靠的虚假视频检测器迫在眉睫。
事实上,区分原始视频和造假视频对人和计算机来说都是一个挑战,特别是在视频被压缩或分辨率较低的情况下,而这种视频一般多见于社交媒体网站。由于缺乏足够大的数据集,以往对人脸伪造视频检测的研究一直因受阻而停滞不前。为此,我们引入了一个全新的人脸伪造数据集,它包含约50万张人脸图像(来自1004个视频),图像所涉及的作伪技术都是当前最先进的,且在质量上超过现有同类视频处理数据集至少一个数量级。
通过使用这个新数据集,我们提出了一种能在各种分类、剪辑、压缩情况下对图像进行经典图像取证的基准,此外,我们还提引入了基准评估,它能在现实基础上创建已知的、难以区分的伪造模型,例如生成细化模型。
数据集FaceForensics
FaceForensics中包含的数据来自1004个视频,它由两个子集组成。其中第一个数据集(source-to-target)包含的是存在差异的源视频和目标视频,而第二个数据集(self-reenactment)则是输入视频后由face2face还原的视频,即源视频与目标视频相同。这两个数据集允许我们访问合成图像和真实图像的真值对(ground truth pairs)。
源-目标数据集:源演员的原始输入图像—目标演员的原始输入图像—重演结果—合成期间使用的3D模型
数据搜集:所有数据都来自YouTube。我们选择的是分辨率大于480p的视频,它们在YouTube8m上已用“face”“newscaster”或“newsprogram”进行了标记。通过使用Viola-Jones人脸检测器,我们从图片中提取了包含超过300个连续帧的人脸视频序列,之后再剪辑成果并手动放映,从中筛选出优质的、无遮挡的视频。
数据处理:为了处理视频,我们使用的方法是最先进的face2face,它能完全自动重演操作,并能在不同表情条件下重新渲染视频中的人脸。在预处理阶段,我们用第一帧获取人脸的3D模型,并在剩下的帧中跟踪表情。为了改善个体拟合和静态纹理估计,面部左右角度的检测框是自动选择的,而这在face2face里原本是手动完成的。简而言之,通过追踪表情,我们能实现个体拟合和静态纹理估计;而通过个体重建,我们就能追踪整个视频来计算每一帧的表达式、rigid pose和照明参数。
这两个数据集的目标主要有以下两点:
验证用当前最先进技术生成的伪造视频在分类和分割时会有什么样的表现。
能否使用生成网络提高伪造质量。
伪造分类任务
伪造分类任务的目的是识别伪造图像,它可以被看作是一个二元分类问题,逐帧处理视频。在数据集的支持下,我们理想中的检测算法不仅能分类高清视频,它应该也能分类视频被压缩或分辨率较低的视频。为了测试算法的性能,我们用H.264压缩算法设置了3个视频压缩基线:无压缩视频、参数为23的低压缩视频和参数为40的高压缩视频。
各基线的清晰度对比
我们在数据集上测试了一系列CNN模型,其中包括一个基于XceptionNet CNN架构的迁移模型。首先,我们在ImageNet上事先把XceptionNet CNN训练好,并对数据集进行微调。在微调期间,我们固定与整个神经网络前4个模块相对应的36个卷积层,然后把最后一层替换成两个带输出的全连接层,随机初始化后进行10个epoch的训练。
当网络连续5个epoch基本保持不变后,为了优化输出,我们又引入了一些超参数来进行评估:Adam、学习率=0.001、β1=0.9、β2=0.999、batch-size=64。下表是我们得出的各模型分类准确率:
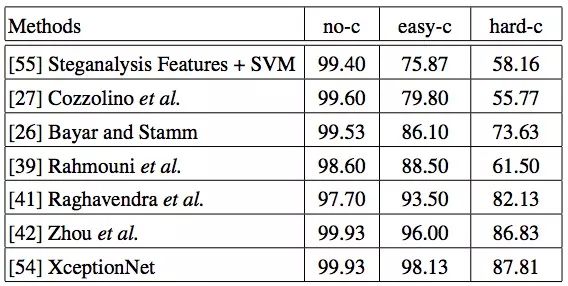
分类准确率:无压缩 (no-c);低压缩 (easy-c);高压缩(hard-c)
可以发现,在无压缩情况下,所有模型都表现良好,而随着视频清晰度的下降,它们的准确率也都出现了不同程度的下降,其中较浅的CNN表现尤为明显,而XceptionNet CNN总体表现优秀。事实上,这种下降是可以接受的,因为一旦视频变得很模糊,人眼也无法作出准确的区分。
伪造分割任务
处理图像的像素级分割是一项非常具有挑战性的任务,而对于图像取证,最有效的一种方法是根据基于相机的伪像(如传感器噪声,去马赛克)。但这种方法在我们的数据集上并没有很好的表现,即便是未压缩的视频,它的表现也很一般。所以我们还是得用深度学习方法,用数据集进行充分训练。
因为XceptionNet之前在分类任务中表现良好,所以这里我们还是把它作为对比模型之一。在测试时,神经网络的滑动窗口以128×128像素大小移动,步长16。每个图像块Wi计算出操作概率的估计值pˆi = CNN(Wi),然后把它分配给中央的16×16区域。(详细过程略)
同样的,当网络连续5个epoch基本保持不变后,我们再次引入学习率=0.001、β1=0.9、β2=0.999进行优化。因为要将和16个原图像、伪造图像相关的3个原图像块、伪图像块组合训练,这次的batch-size=96。
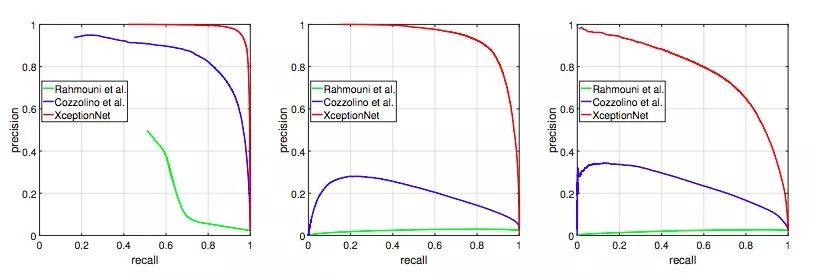
精度和召回率
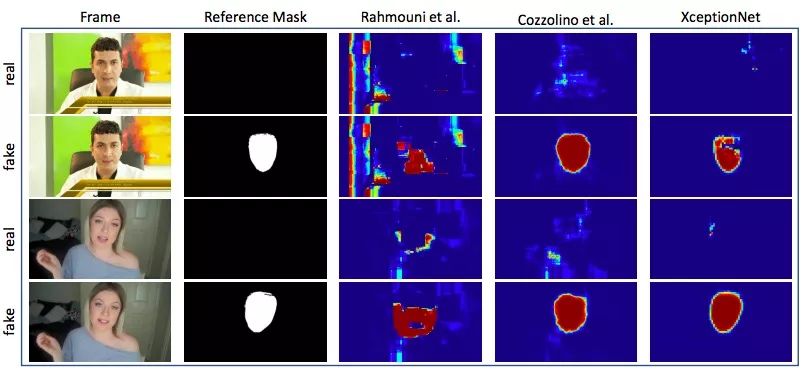
伪造人脸分割结果
如上图所示,这次我们沿用了之前的定量评估,发现随着压缩率的上升,各模型分割性能都出现了明显下降。最终,在高压缩视频中,只有基于XceptionNet的模型给出了较好的输出。
反向用于生成伪像
在我们的“伪造分类任务”中,实验证明Face2Face可以从未压缩的视频中检测到相当多的数据信息,这就产生了一个问题,即这个数据集是否也能用于相反的目标——进一步提升合成人训练的逼真程度。为了证实这一点,我们用包含521,406个目标真值的第二个数据集做了一次监督学习。

带有skip connection的自动编码器(AE)
作为基准,我们设计了一个带有skip connection的自动编码器CNN架构,它将128×128像素的图像作为输入,并预测具有相同分辨率的图像(见上图)。为了从人脸图像中获得有意义的特征,我们先使用VGGFace2数据集以无监督学习的方式对自动编码器网络进行预训练。该数据集包含9131个类别的313万幅图像,比我们的数据集多,但没有经过标记。我们禁用了skip connection,强迫神经网络完全依靠瓶颈层进行训练。
之后,我们又对FaceForensics中的368,135个训练图像进行微调,并把经过预训练的自动编码器网络放在上面训练。我们输入一张假脸,把监督学习的loss设置成1,启用skip connection,以便网络能输出更清晰的结果。
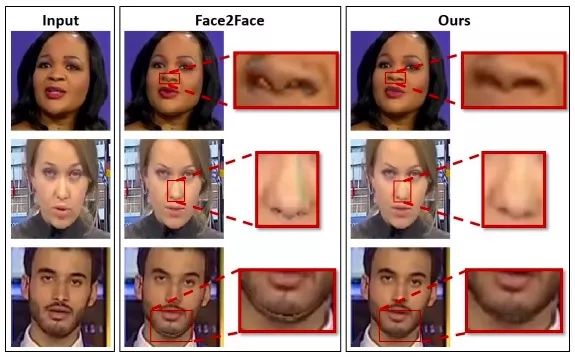
上图展示了我们的成果。通过拉近特写镜头,可以发现比起Face2Face,我们改进自动编码器后生成的图片能显示更多细节。Face2Face在鼻孔、鼻子、下巴和脸颊周围会生成大量伪影,我们的方法不仅让这些区域的线条更清晰,还修改了人脸3D模型与背景之间的过渡错误。同时,它还改进了Face2Face由于照明参数估计错误导致的伪影问题。
-
人脸检测算法及新的快速算法2013-09-26 0
-
基于openCV的人脸检测系统的设计2014-12-23 0
-
人脸识别经典算法实现python2018-05-04 0
-
人脸识别技术的60年发展史2018-06-20 0
-
Firefly 百度人脸识别开发套件2018-07-25 0
-
计算机视觉/深度学习领域常用数据集汇总2018-08-29 0
-
深度学习中开发集和测试集的定义2018-11-30 0
-
ARM嵌入式环境中FDDB第一的人脸检测算法的运行2019-07-29 0
-
基于层次型AdaBoost检测算法的快速人脸检测该怎么实现?2019-09-02 0
-
全网唯一一套labview深度学习教程:tensorflow+目标检测:龙哥教你学视觉—LabVIEW深度学习教程2020-08-10 0
-
2021人脸识别六大趋势应用2021-08-12 0
-
分享一款高速人脸检测算法2021-12-15 0
-
基于深度学习的人脸识别算法与其网络结构2021-03-12 3000
-
基于深度学习的跨域小样本人脸欺诈检测算法2021-04-15 730
-
基于生成对抗网络的深度伪造视频综述2021-05-10 797
全部0条评论

快来发表一下你的评论吧 !
