

智能机器也可以充当狗的角色?这个想法非常有挑战性
电子说
描述
通常,我们的人工智能系统都是以人的视角去构造的,这些系统已经用于自动驾驶、人脸识别、操作重型机器,甚至检测疾病。那么,我们可以从动物的角度构建一个智能系统吗?比如让 AI 去模拟狗的行为。
华盛顿大学与 Allen 人工智能研究所的研究人员最新的论文公开了他们开发的一种深度学习系统,该系统可以训练并模拟狗的行为特征。研究人员表示训练智能机器的目标是使其能够充当一个智能视觉体的角色。不过,让智能机器充当狗的角色这个想法是非常具有挑战性的任务。
简介
我们研究了如何直接构建一个视觉智能体(visually intelligent agent)。通常,计算机视觉技术专注于解决与视觉智能相关的各种子任务。但我们的研究不同于这种标准的计算机视觉方法。相反,我们尝试直接构建一个视觉智能体,我们的模型将视觉信息作为输入,并直接预测智能体在未来的行为。
此外,我们引入了 DECADE 数据集,这是一个以狗的视角所搜集的狗的行为数据集。利用这些数据,我们可以模拟狗的行为和动作规划方式。在多种度量方法下,对于给定的视觉输入,我们成功地构建了一个视觉智能体,它能够准确预测并模拟狗的行为。不仅如此,与图像分类任务学到的特征表征相比,我们的智能体学习到的特征能够编码不同的信息,也可以推广到其他领域。尤其需要指出的是,通过将这种狗的建模任务作为表示学习,我们在可行走区域预测和场景分类任务中取得非常卓越的结果。
方法与模型
为了训练,研究人员使用了一个叫做 Kelp 的阿拉斯加雪橇犬,并在其腿部配备了 GoPro 相机,尾部和后备箱上配备六个惯性测量传感器,一个麦克风以及一个把这些数据绑在一起的 Arduino 开发板。研究人员在超过 50 个不同的地点,在长达数小时的时间内,记录了 Kelp 的活动数据,如步行、追踪、抓取,与其他狗互动以及跟踪物体等。利用英伟达提供的 GeForce GTX 1080 GPU,TITAN X GPU 以及 cuDNN 加速的深度学习框架,研究人员用所获得的视觉和感官信息来训练神经网络。
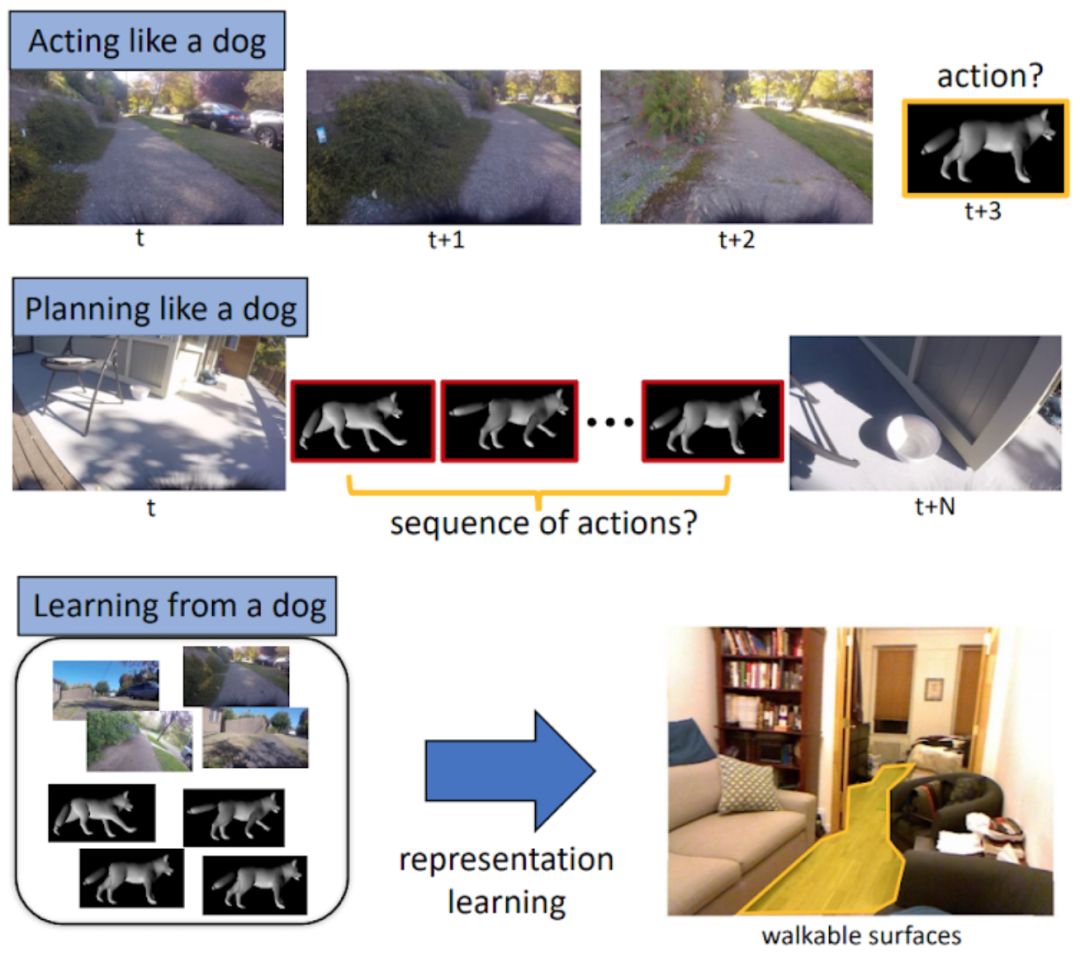
在这里,研究人员解决了三个问题:
像狗一样行动:根据一系列先前看到的图像,神经网络的目标是预测狗未来的运动轨迹;
像狗一样规划:目标是找到一系列动作,让狗在给定的一对图像的位置之间移动。
从狗身上学习:我们将学习的表现用于第三项任务(如可行走的表面评估(Walkable surface estimation),预测狗的可行走区域)。
这些任务需要一些相当复杂的数据:例如,就像真的狗一样,我们的 AI 系统必须知道,当它需要从一个地点移动到另一地点的时候,可行走区域的位置有哪些。它不能在树上或汽车上行走,也不能在沙发上行走(这也取决于房子)。因此,我们的模型也要学会这一点,它可以作为一个独立的计算机视觉模型,在一张给定图像中找出一个宠物(或一个有足机器人)所能够到达的位置。下面我们将逐一介绍这三个任务所用到的模型结构。
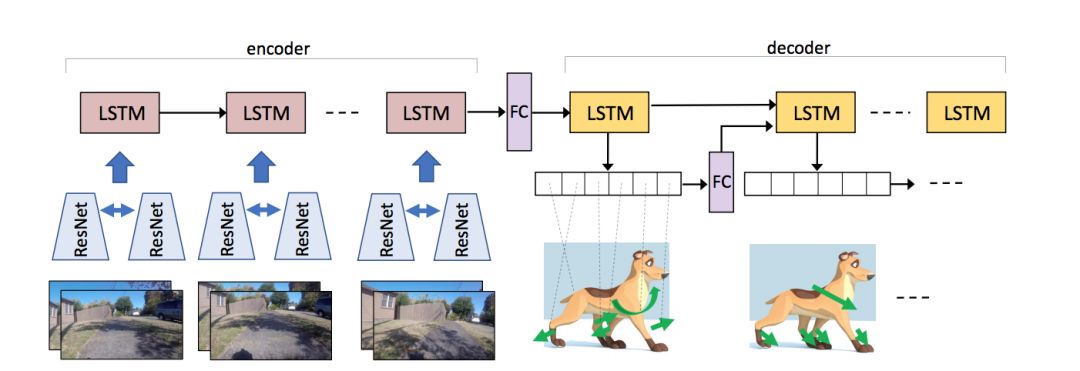
这是用于模拟狗的行为的模型结构。这个模型是一个编码-解码器结构的神经网络,编码器接收成对的图片流作为输入,而解码器输出每个节点未来的行动决策。在编码器和解码器之间有一个全连接层(FC),它能够更好地捕捉区域内的行为变化。在解码器中,每个时步输出的行动概率将被用于下一个时步(timestep)。我们在两个 ResNet 中共享模型的权重参数。
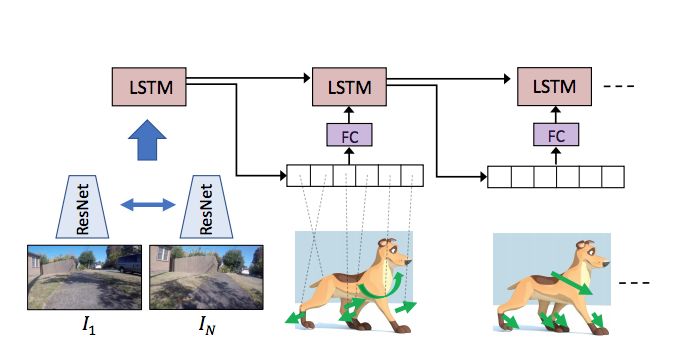
这是用于规划狗的行为的模型结构。这个模型是卷积神经网络 CNN 和长短期记忆模型 LSTM 的结合体。模型的输入是两张图片 I1 和 IN,这是在视频系列的第 N-1 时间步截取来的数据。长短期记忆模型 LSTM 接收 CNN 的特征作为输入,并输出狗从 I1 移动到 IN 过程的行动序列。
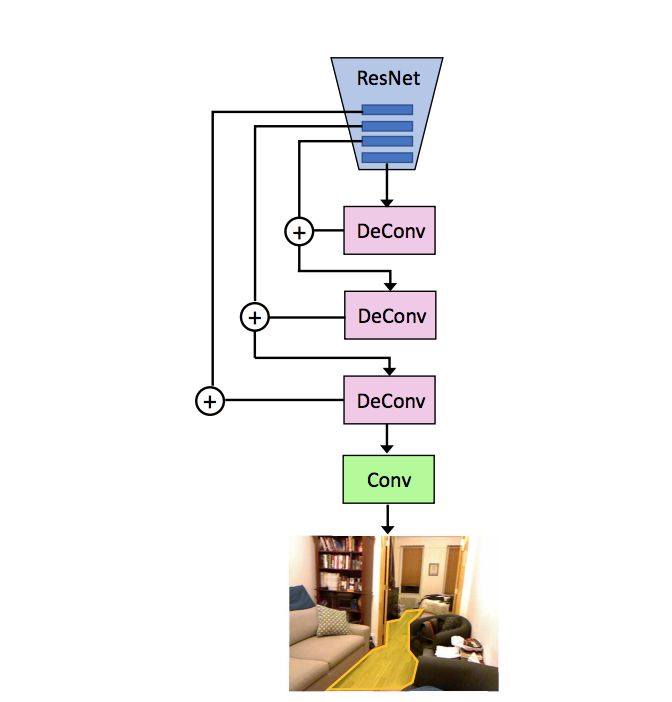
这是用于可行走区域预测的模型结构。我们用 ResNet 模型的后四层,对其进行卷积、反卷积来推断可行走区域。
评估指标
在实验评估阶段,我们使用多种不同的评价指标来综合地评判我们的方法,包括分类精度、混淆度(perplexity)等。
定量分析结果:我们展示了模型识别视频中 5 帧数据的结果,视频中一个男人开始向一只狗投掷一个球。在视频中,当球飞向那只狗时,狗会向右方移动以躲避球飞过来的方向。仅仅使用这 5 帧数据,模型就能够在球飞来时准确地预测出狗的移动方向。
实验结果

“像狗一样行动”的结果: 我们观察了 5 帧的视频序列并预测了接下来的 5 个动作。
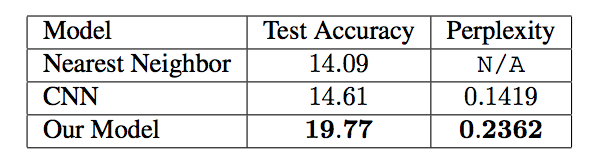
“像狗一样规划”的结果:在开始和结束帧之间进行规划, 我们考虑了相隔 5 步的起始图像。
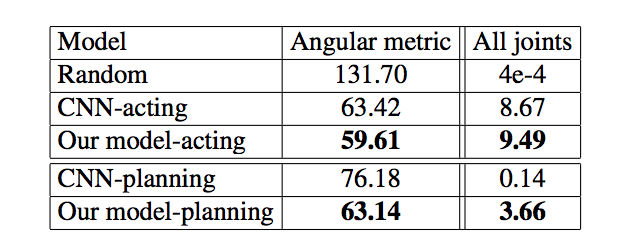
持续评估和全节点评估。在第一栏中数值越低越好,在第二栏中数值越高越好。

“步行式表面评估”结果。我们将在 ImageNet 上训练的网络结果与为我们做任务训练的网络进行了比较。 评估指标是 IOU。
实验结果表明,我们的模型能够在不同的情况下学习并模拟狗的行为,并像狗一样的规划并采取行动。
在研究报告中,研究人员指出,“狗的行动空间比人类要简单得多,这使得我们的任务更加易于处理。然而,它们能够清楚地表现出智能视觉的能力,如识别食物、障碍物、其他人类和动物,并对这些输入做出相应地反应,但我们对于这些行为的目标和动机常常知之甚少。”
未来展望
研究人员提到,他们的评估实验显示出有趣而富有希望的结果。他们的模型可以在各种情况下预测狗的行为,并能像狗一样采取行动,还能像狗一样计划如何从一种状态转移到另一种状态。
在未来的应用中,研究团队表示这只是一个初步的实验。他们打算从多只狗身上收集更多数据(建立多样的数据库),并考虑引入更多的感官信息,如找到一些捕捉声音、触觉和嗅觉的方法。他们希望这项工作能够为人类更好理解视觉智能和生物智能奠定基础。
-
颠覆性科技之智能机器人2015-12-22 0
-
人工智能--失业将是人类面临的最大挑战2016-06-27 0
-
【Rico Board申请】双模式智能机器人2016-10-20 0
-
请问ZigBee Home Automation中 ZAP 充当的角色是什么?2018-08-08 0
-
模拟设计的新角色2019-07-19 0
-
如何应对机器人设计开发中的挑战?2019-07-31 0
-
机器学习可以有效的控制物联网应用的安全性2020-11-03 0
-
中国人工智能的现状与未来2021-07-27 0
-
基于 Arduino nano 的智能机器狗(原理图+PCB)2021-12-01 0
-
一只完全由PCB制造的智能机器狗2022-07-05 0
-
扫地机器人面临的设计挑战有哪些2022-11-09 0
-
余承东:操作系统是软件行业皇冠上的明珠 当前的创新研究还非常有挑战2023-02-25 0
-
音频设计:比你所想象的更富挑战性2008-09-16 758
-
当前智能机器人发展若干挑战性问题2018-07-09 5229
-
机器学习/人工智能领域一些非常有创意的突破2019-05-19 3149
全部0条评论

快来发表一下你的评论吧 !
