

是什么让变分自编码器成为如此成功的多媒体生成工具呢?
电子说
描述
与经常作为分类器的神经网络相比,变分自编码器是一种十分著名的生成模型,目前被广泛用于生成伪造的人脸照片,甚至可以用于生成美妙的音乐。然而是什么让变分自编码器成为如此成功的多媒体生成工具呢?让我们来一探其背后的究竟。
当我们使用生成模型时也许只想生成随机的和训练数据类似的输出,但如果想生成特殊的数据或者在已有数据上进行一定的探索那么普通的自动编码器就不一定能满足了。而这正是变分自编码器的独特之处。
标准自编码器
一个标准的自编码器网络实际上是一对儿相互连接的神经网络,包括编码器和解码器。编码器神经网络将输入数据转化为更小更紧凑的编码表达,而解码器则将这一编码重新恢复为原始输入数据。下面我们用卷积神经网络来对自编码器进行具体的说明。
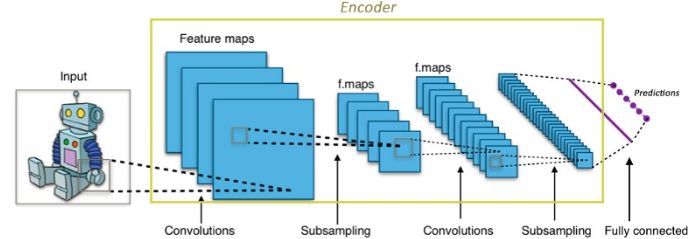
自编码器中的CNNs
对于卷积神经网络CNNs来说,将输入的图像转换为更为紧密的表达(ImageNet中通常为1000维的一阶张量)。这一紧密的表达用于对输入图像进行分类。编码器的工作原理也与此类似,它将输入数据转换为十分小而紧凑的表达(编码),其中包含了可供解码器生成期望输出的足够信息。编码器一般与网络的其他部分一同训练并通过反向传播的误差进行优化从而生成有用的特殊编码。对于CNNs来说,可以将其看做是特殊的编码器。其输出的1000维编码便是用于分类的分类器。
自编码器便是基于这样的思想将编码器输出的编码用作重建其输入的特殊用途。
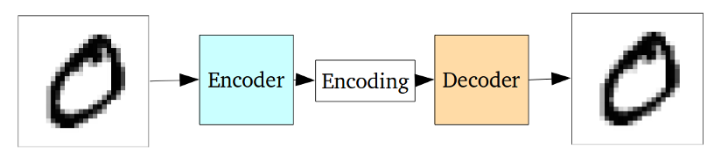
标准的自编码器
整个自编码器神经网络常常作为整体进行训练,其损失函数则定义为重建输出与原始输入之间的均方差/交叉熵,作为重建损失函数来惩罚网络生成与原始输入不同的输出。
中间的编码作为隐藏层间链接的输出,其维度远远小于输出数据。编码器必须选择性的抛弃数据,将尽可能多的相关信息包含到有限的编码中,同时智能的去除不相关的信息。解码器则需要从编码中尽可能的学习如何重建输入图像。他们一起构成了自编码器的左膀右臂。
标准自编码器面临的问题
标准自编码器能学习生成紧凑的数据表达并重建输入数据,然而除了像去噪自编码器等为数不多的应用外,它的应用却极其有限。其根本原因在于自编码器将输入转换为隐含空间中的表达并不是连续的,使得其中的插值和扰动难以完成。
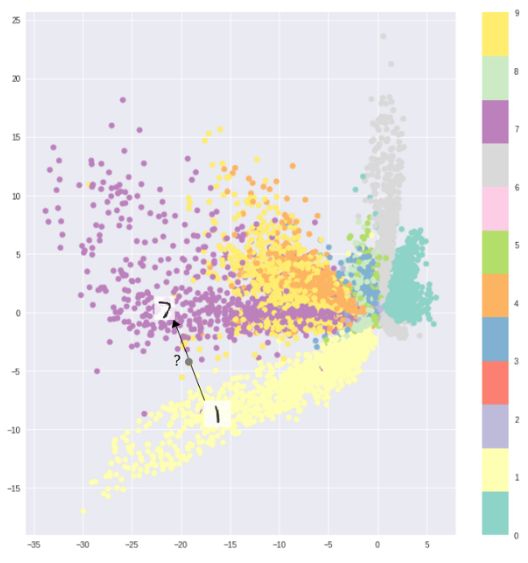
MNIST数据不同分类间的间隔造成了编码器无法连续采样
例如利用MNIST数据集训练的自编码器将数据映射到2D隐含空间中,图中显示不同的分类之间存在着明显的距离。这使得解码器对于存在于类别之间的区域无法便捷的进行解码。如果你不想仅仅只是复现输入图像,而是想从隐含空间中随机的采样或是在输入图像上生成一定的变化,那此时一个连续的隐含空间就变得必不可少了。
如果隐含空间不连续,那么在不同类别中间空白的地方采样后解码器就会生成非真实的输出。因为解码器不知道如何除了一片空白的隐含区域,它在训练过程中从未见到过处于这一区域的样本。
变分自编码器
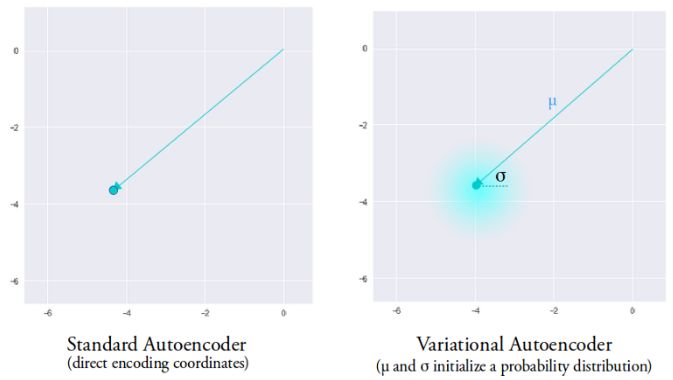
变分自编码器具有与标准自编码器完全不同的特性,它的隐含空间被设计为连续的分布以便进行随机采样和插值,这使得它成为了有效的生成模型。它通过很独特的方式来实现这一特性,编码器不是输出先前的n维度向量而是输出两个n维矢量:分别是均值向量μ和标准差向量σ。
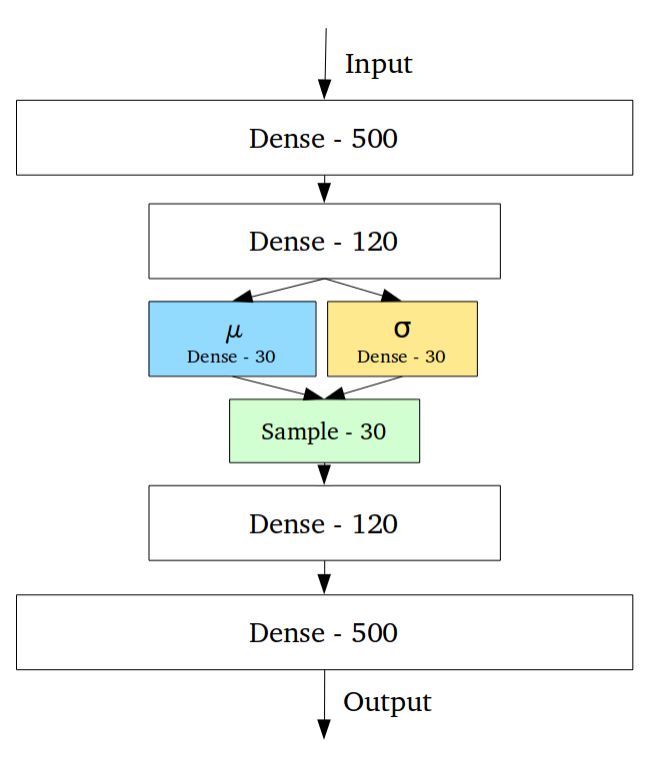
随后通过对μ和σ作为均值和方差采样得到了随机变量Xi,n次采样后形成了n维的采样后结果作为编码输出,并送入后续的解码器。

随机生成编码矢量
这一随机生成意味着即使对于均值和方差相同的输入,实际的编码也会由于每一次采样的不同而产生不同的编码结果。其中均值矢量控制着编码输入的中心,而标准差则控制着这一区域的大小(编码可以从均值发生变化的范围)。
通过采样得到的编码可以是这一区域里的任意位置,解码器学习到的不仅是单个点在隐含空间中的表示,而是整个邻域内点的编码表示。这使得解码器不仅仅能解码隐含空间中单一特定的编码,而且可以解码在一定程度上变化的编码,而这是由于解码器通过了一定程度上变化的编码训练而成。
所得到的模型目前就暴露在了一定程度局域变化的编码中,使得隐含空间中的相似样本在局域尺度上变得平滑。理想情况下不相似的样本在隐含空间中存在一定重叠,使得在不同类别间的插值成为可能。但这样的方法还存在一个问题,我们无法对μ和σ的取值给出限制,这会造成编码器在不同类别上学习出的均值相去甚远,使它们间的聚类分开。最小化σ使得相同的样本不会产生太大差异。这使得解码器可以从训练数据进行高效重建。
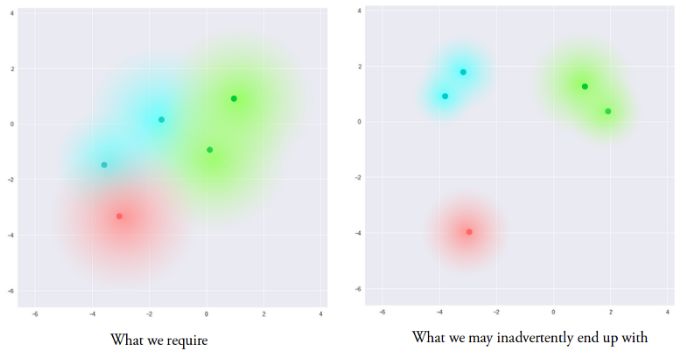
我们希望得到尽量互相靠近但依然有一定距离的编码,以便在隐含空间中进行插值并重建出新的样本。为了实现满足要求的编码需要在损失函数中引入Kullback-Leibler散度(KL散度)。KL散度描述两个概率分布之间的发散程度。最小化KL散度在这里意味着优化概率分布的参数(μ,σ)尽可能的接近目标分布。
对于VAE来说KL损失函数是X中所有元素Xi~N(μi, σi²)与标准正态分布的散度和。
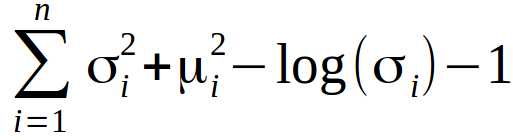
这一损失函数将鼓励所有编码在围绕隐藏层中心分布,同时惩罚不同分类被聚类到分离区域的行为。利用纯粹KL散度损失得到的编码是以隐藏空间中心随机分布的。但从这些无意义的表达中解码器却无从解码出有意义的信息。
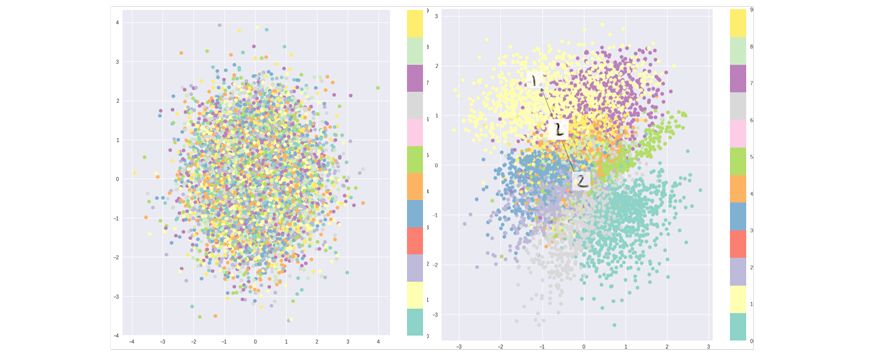
纯粹的KL散度优化的隐含空间(左),结合了重建损失优化的隐含空间
这是就需要将KL损失和重建损失结合起来。这使得在局域范围内的隐藏空间点维持了相同的类别,同时在全局范围内所有的点也被紧凑的压缩到了连续的隐含空间中。这一结果是通过重建损失的聚类行为和KL损失的紧密分布行为平衡得到的,从而形成了可供解码器解码的隐含空间分布。这意味着可以随机的采样并在隐含空间中平滑的插值,得到的结果可控解码器生成有意义的有效结果。

最终的损失函数
矢量运算
那么现在我们如何在隐含空间中得到平滑的插值呢?这主要通过隐含空间中的矢量运算来实现。
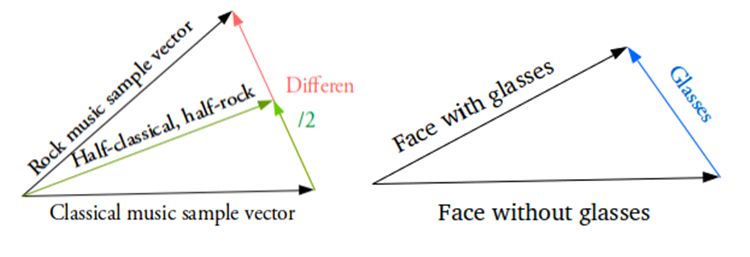
例如想得到两个样本之间的新样本,那么只需要计算出他们均值矢量之差,并以其一半加上原来的矢量。最后将得到的结果送入到解码器即可。那对于特殊的特征也,比如生成眼镜该如何操作呢?那就找到分别戴眼镜和不戴眼镜的样本,并得到他们在编码器隐含空间中矢量之差,这就表示了眼镜这一特征。将这新的“眼镜”矢量加到任意的人脸矢量后进行解码即可得到戴眼镜的人脸。
展望
对于变分自编码来说,目前已经出现了各种各样的改进算法。可以增加、替换标准的全连接编解码器,并用卷积网络来代替。有人利用它生成了各种各样的人脸和著名的MNIST变化数据。
甚至可以用LSTM训练编解码器训练时序离散数据,从而生成文本和音乐等序列样本。甚至可以模仿人类的简笔画。
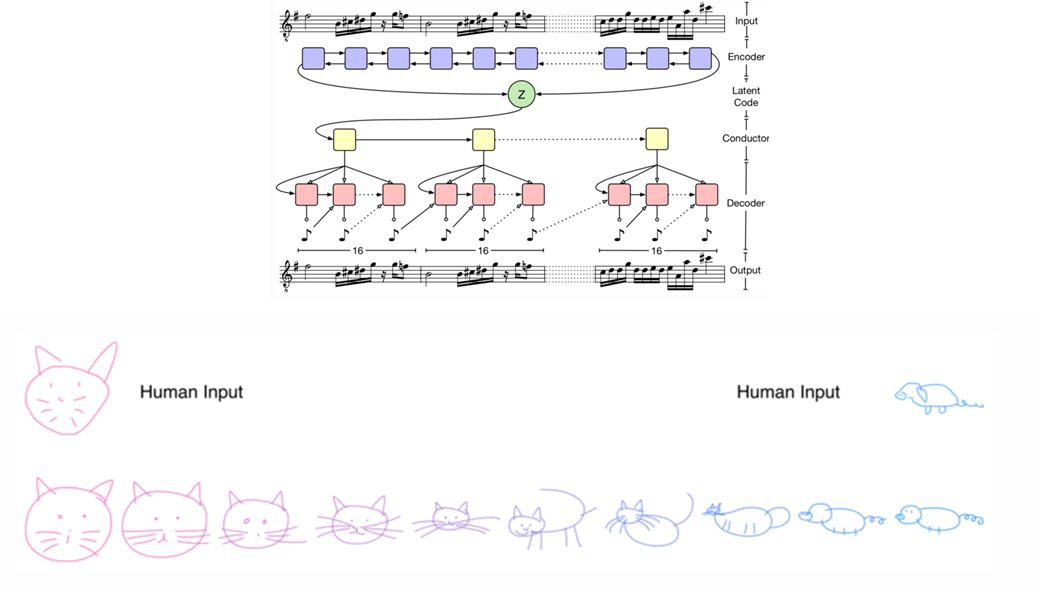
VAE对于各种各样的数据都有很好的适应性,无论序列或非序列、连续或离散、标记或非标记数据都是强大的生成工具。期待能在未来看到更多独特瞩目的应用。
-
REACH视音频编码器2011-03-03 0
-
什么是线性编码器2019-12-17 0
-
基于变分自编码器的异常小区检测2020-12-03 0
-
初识编码器2022-02-24 0
-
编码器,编码器是什么意思2010-03-08 2889
-
自编码器是什么?有什么用2018-08-02 17105
-
自编码器介绍2019-06-11 4668
-
稀疏自编码器及TensorFlow实现详解2019-06-11 3609
-
基于变分自编码器的海面舰船轨迹预测算法2021-03-30 724
-
自编码器基础理论与实现方法、应用综述2021-03-31 630
-
一种基于变分自编码器的人脸图像修复方法2021-04-21 618
-
MCU工具之LED编码器2021-05-06 567
-
自编码器神经网络应用及实验综述2021-06-07 608
-
堆叠降噪自动编码器(SDAE)2023-01-11 5064
-
自编码器 AE(AutoEncoder)程序2023-01-11 960
全部0条评论

快来发表一下你的评论吧 !
