

TFLite在有道云笔记中用于文档识别的实践过程
电子说
描述
这一两年来,在移动端实现实时的人工智能已经形成了一波潮流。去年,谷歌推出面向移动端和嵌入式的神经网络计算框架TensorFlow Lite,将这股潮流继续往前推。TensorFlow Lite如何进行操作?本文将介绍TFLite在有道云笔记中用于文档识别的实践过程,以及 TFLite 都有些哪些特性,供大家参考。
近年来,有道技术团队在移动端实时 AI 能力的研究上,做了很多探索及应用的工作。2017 年 11 月 Google 发布 TensorFlow Lite (TFLlite) 后,有道技术团队第一时间跟进 TFLite 框架,并很快将其用在了有道云笔记产品中。
以下是TFLite在有道云笔记中用于文档识别的实践过程。
文档识别工作的介绍
1. 文档识别的定义
文档识别最初是开发有道云笔记的文档扫描功能时面对的一个问题。文档扫描功能希望能在用户拍摄的照片中,识别出文档所在的区域,进行拉伸 (比例还原),识别出其中的文字,最终得到一张干净的图片或是一篇带有格式的文字版笔记。实现这个功能需要以下这些步骤:
识别文档区域: 将文档从背景中找出来,确定文档的四个角;
拉伸文档区域,还原宽高比: 根据文档四个角的坐标,根据透视原理,计算出文档原始宽高比,并将文档区域拉伸还原成矩形;
色彩增强: 根据文档的类型,选择不同的色彩增强方法,将文档图片的色彩变得干净清洁;
布局识别: 理解文档图片的布局,找出文档的文字部分;
OCR: 将图片形式的“文字”识别成可编码的文字;
生成笔记: 根据文档图片的布局,从 OCR 的结果中生成带有格式的笔记。

文档识别就是文档扫描功能的第一步,也是场景最复杂的一个部分
2. 文档识别在有道 AI 技术矩阵中的角色
有道近年来基于深度神经网络算法,在自然语言、图像、语音等媒体数据的处理和理解方面做了一系列工作,产出了基于神经网络的多语言翻译、OCR(光学字符识别)、语音识别等技术。在这些技术的合力之下,我们的产品有能力让用户以他们最自然最舒服的方式去记录内容,用技术去理解这些内容,并将其统一转化为文本以待下一步处理。从这个角度来看,我们的各种技术组成了以自然语言为中心,多种媒体形式相互转换的网络结构。
文档识别是从图像转化为文本的这条转换链上,不起眼却又不可缺少的一环。有了它的存在,我们可以在茫茫图海中,准确找到需要处理的文档,并将其抽取出来进行处理。
3. 文档识别的算法简介
我们的文档识别算法基于 FCNN (Fully Convolutional Neural Network) ,这是一种特别的 CNN(卷积神经网络),其特点是对于输入图片的每一个像素点,都对应着一个输出(相对的,普通的 CNN 网络则是每一张输入图片对应着一个输出)。因此,我们可以标记一批包含文档的图片,将图片中文档边缘附近的像素标注为正样本,其他部分标注为副样本。训练时,以图片作为 FCNN 的输入,将输出值与标注值作对比得到训练惩罚,从而进行训练。关于文档识别算法的更多细节,可以参见有道技术团队的《文档扫描:深度神经网络在移动端的实践》这篇文章。
由于算法的主体是 CNN,因此文档扫描算法中主要用到的算子(Operator)包括卷积层、Depthwise 卷积层、全连接层、池化层、Relu 层这些 CNN 中常用的算子。
4. 文档识别与 TensorFlow
能够训练和部署 CNN 模型的框架非常多。我们选择使用 TensorFlow 框架,是基于以下几方面的考虑的:
TensorFlow 提供的算子全面且数量众多,自己创建新的算子也并不麻烦。在算法研发的初期会需要尝试各种不同的模型网络结构,用到各种奇奇怪怪的算子。此时一个提供全面算子的框架能够节省大量的精力;
TensorFlow 能够较好的覆盖服务器端、Android 端、iOS 端等多个平台,并在各个平台上都有完整的算子支持;
TensorFlow 是一个比较主流的选择,这意味着当遇到困难时,更容易在互联网上找到现成的解决办法。
5. 为什么想在文档识别中用 TFLite
在 TFLite 发布之前,有道云笔记中的文档识别功能是基于移动端 TensorFlow 库 (TensorFlow Mobile) 的。当 TFLite 发布后,我们希望迁移到 TFLite 上。促使我们迁移的主要动力是链接库的体积。
经过压缩后,Android 上的 TensorFlow 动态库的体积大约是 4.5M 左右。如果希望满足 Android 平台下的多种处理器架构,可能需要打包 4 个左右的动态库,加起来体积达到 18M 左右;而 tflite 库的体积在 600K 左右,即便是打包 4 个平台下的链接库,也只需要占用 2.5M 左右的体积。这在寸土寸金的移动 App 上,价值是很大的。
TFLite的介绍
1. TFLite 是什么
TFLite 是 Google I/O 2017 推出的面向移动端和嵌入式的神经网络计算框架,于2017年11月5日发布开发者预览版本 (developer preview)。相比与 TensorFlow,它有着这样一些优势:
轻量级。如上所述,通过 TFLite 生成的链接库体积很小;
没有太多依赖。TensorFlow Mobile 的编译依赖于 protobuf 等库,而 tflite 则不需要大的依赖库;
可以用上移动端硬件加速。TFLite 可以通过 Android Neural Networks API (NNAPI) 进行硬件加速,只要加速芯片支持 NNAPI,就能够为 TFLite 加速。不过目前在大多数 Android 手机上,Tflite 还是运行在 CPU 上的。
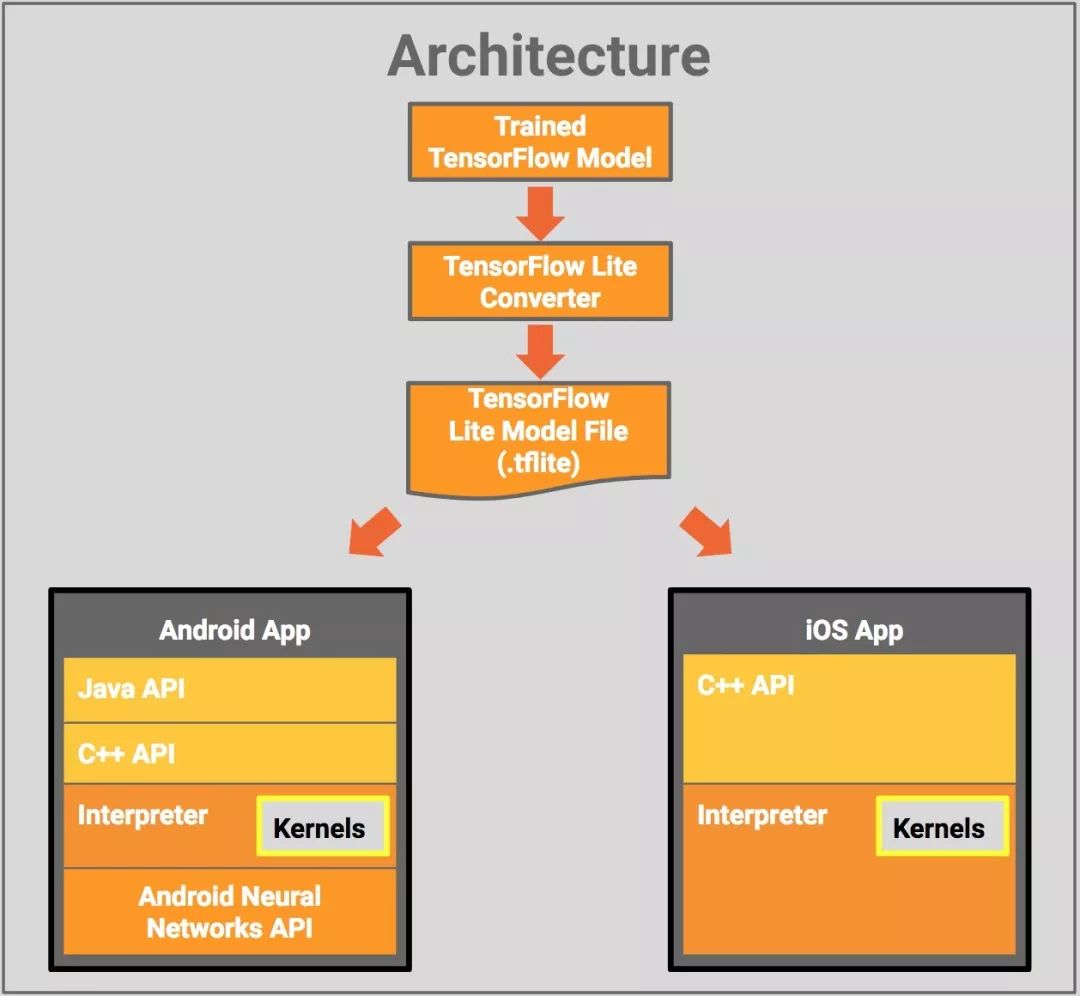
TensorFlow Lite的架构设计
2. TFLite 的代码结构
作为 TFLite 的使用者,我们也探索了一下 TFLite 的代码结构,这里分享一下。
目前,TFLite 的代码位于 TensorFlow 工程中 "tensorflow/contrib/lite" 文件夹下。文件夹下有若干头/源文件和一些子文件夹。
其中,一些比较重要的头文件有:
model.h: 和模型文件相关的一些类和方法。其中 FlatBufferModel 这个类是用来读取并存储模型内容的,InterpreterBuilder 则可以解析模型内容;
Interpreter.h: 提供了用以推断的类 Interpreter,这是我们最常打交道的类;
context.h: 提供了存储 Tensors 和一些状态的 struct TfLiteContext。实际使用时一般会被包装在 Interpreter 中;
此外,有一些比较重要的子文件夹:
kernels: 算子就是在这里被定义和实现的。其中 regester.cc 文件定义了哪些算子被支持,这个是可以自定义的。
downloads: 一些第三方的库,主要包括:
abseil: Google 对 c++ 标准库的扩展;
eigen: 一个矩阵运算库;
farmhash: 做 hash 的库;
flatbuffers: TFLite 所使用的 FlatBuffers 模型格式的库;
gemmlowp: Google 开源的一个低精度矩阵运算库;
neon_2_sse: 把 arm 上的 neon 指令映射到相对应的 sse 指令。
java: 主要是 Android 平台相关的一些代码;
nnapi: 提供了 nnapi 的调用接口。如果想自己实现 nnapi 可以看一看;
schema: TFLite 所使用的 FlatBuffers 模型格式的具体定义;
toco: protobuf 模型转换到 FlatBuffers 模型格式的相关代码。
我们是怎么用TFLite的?
1. TFLite 的编译
TFLite 可以运行在 Android 和 iOS 上,官方给出了不同的编译流程。
在 Android 上,我们可以使用 bazel 构建工具进行编译。bazel 工具的安装和配置就不再赘述了,有过 TensorFlow 编译经验的同学应该都熟悉。依照官方文档,bazel 编译的 target 是 "//tensorflow/contrib/lite/java/demo/app/src/main:TfLiteCameraDemo",这样得到的是一个 demo app。如果只想编译库文件,可以编译 "//tensorflow/contrib/lite/java:tensorflowlite" 这个 target,得到的是 libtensorflowlite_jni.so 库和相应的 java 层接口。
更多细节见官方文档:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/mobile/tflite/demo_android.md
在 iOS 上,则需要使用 Makefile 编译。在 mac 平台上运行 build_ios_universal_lib.sh,会编译生成 tensorflow/contrib/lite/gen/lib/libtensorflow-lite.a 这个库文件。这是个 fat library,打包了 x86_64, i386, armv7, armv7s, arm64 这些平台上的库。
更多细节见官方文档:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/mobile/tflite/demo_ios.md
两个平台上 TFLite 库的调用接口也有所不同:Android 上提供了 Java 层的调用接口,而 iOS 上则是 c++ 层的调用接口。
当然,TFLite 的工程结构是比较简单的,如果你熟悉了 TFLite 的结构,也可以用自己熟悉的编译工具来编译 TFLite。
2. 模型转换
TFLite 不再使用旧的 protobuf 格式(可能是为了减少依赖库),而是改用 FlatBuffers 。因此需要把训练好的 protobuf 模型文件转换成 FlatBuffers 格式。
TensorFlow 官方给出了模型转化的指导。首先,由于 TFLite 支持的算子比较少,更不支持训练相关的算子,因此需要提前把不需要的算子从模型中移除,即 Freeze Graph ;接着就可以做模型格式转换了,使用的工具是 tensorflow toco。这两个工具也是通过 bazel 编译得到。
更多细节见官方文档:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/docs_src/mobile/tflite/devguide.md
3. 缺失的算子
TFLite 目前仅提供有限的算子,主要以 CNN 中使用到的算子为主,如卷积、池化等。我们的模型是全卷积神经网络,大部分算子 TFLite 都有提供,但 conv2d_transpose(反向卷积)算子并没有被提供。幸运的该算子出现在网络模型的末端,因此我们可以将反向卷积之前的计算结果取出,自己用 c++ 实现一个反向卷积,从而计算出最终的结果。由于反向卷积的运算量并不大,所以基本没有影响到运行速度。
如果不巧,你的模型需要但 TFLite 缺少的算子并非出现在网络的末端,该怎么办呢?你可以自定义一个 TFLite 算子,将其注册在 TFLite 的 kernels 列表中,这样编译得到的 TFLite 库就可以处理该算子了。同时,在模型转换时,还需要加上 --allow_custom_ops 选项,将 TFLite 默认不支持的算子也保留在模型中。
更多细节见官方文档:
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/custom_operators.md
TFLite 优缺点
优点:在库的大小、开发方便程度、跨平台性、性能之间达成一个平衡
作为对比,有道技术团队选取了一些其他的移动端深度学习框架,分别分析其在“开发方便程度、跨平台性、库的大小、性能”四个方面的表现:
TensorFlow Mobile,由于和 server 上的 TensorFlow 是同一套代码,所以可以直接使用 server 上训练得到的模型,开发非常方便;能支持 Android, iOS, 跨平台性没问题;如前所述,库的大小比较大;性能主流。
caffe2,可以比较方便的从 caffe 训练出的模型转换到 caffe2 ,但缺少一些算子, 开发方便程度一般;能支持 Android, iOS,跨平台性没问题;库编译出来比较大,但是是静态库可以压缩;性能主流。
Mental/Accelerate,这两个都是 iOS 上的框架。比较底层,需要模型转换&自己写 inference 代码,开发比较痛苦;仅支持 iOS;库是系统自带,不涉及库大小问题;速度很快。
CoreML,这个是 WWDC17 发布的 iOS 11 上的框架。有一些模型转换工具,只涉及通用算子时开发不算痛苦,涉及自定义算子时就很难办了;仅支持 iOS 11 以上;库是系统自带,不涉及库大小问题;速度很快。
最后是 TFLite:
TFLite,其模型可以由 TensorFlow 训练得到的模型转换而来,但缺少一些算子, 开发方便程度一般;能支持 Android, iOS,跨平台性没问题;库编译出来很小;就我们的实验来看,速度比TensorFlow 快一点。
可以看到,TensorFlow Mobile 开发方便,通用性好,但链接库大,性能主流(其他 server 端神经网络框架的 mobile 版也都有类似的特点);Mental/Accelerate 这些比较底层的库速度很快,但不能跨平台,开发比较痛苦;caffe2、TFLite 这类有为移动端优化过的神经网络框架则比较平衡,虽然初时会有算子不全的问题,但只要背后的团队不断支持推进框架的开发,这个问题未来会得到解决。
优点:相对容易扩展
由于 TFLite 的代码(相对于 TensorFlow)比较简单,结构比较容易理清,所以可以相对容易的去扩展。如果你想增加一个 TFLite 上没有而 TensorFlow 上有的算子,你可以增加一个自定义的类;如果你想增加一个 TensorFlow 上也没有的算子,你也可以直接去修改 FlatBuffers 模型文件。
缺点:ops 不够全面
如前所述,TFLite 目前主要支持 CNN 相关的算子 ,对其他网络中的算子还没有很好的支持。因此,如果你想迁移 rnn 模型到移动端,TFLite 目前是不 OK 的。
不过根据最新的 Google TensorFlow 开发者峰会,Google 和 TensorFlow 社区正在努力增加 ops 的覆盖面,相信随着更多开发者的相似需求, 更多的模型会被很好的支持。这也是我们选择 TensorFlow 这样的主流社区的原因之一。
缺点:目前还不能支持各种运算芯片
虽然 TFLite 基于 NNAPI,理论上是可以利用上各种运算芯片的,但目前还没有很多运算芯片支持 NNAPI。期待未来 TFLite 能够支持更多的运算芯片,毕竟在 CPU 上优化神经网络运行速度是有上限的,用上定制芯片才是新世界的大门。
总结
这一两年来,在移动端实现实时的人工智能似乎已经形成了一波潮流。有道技术团队在移动端 AI 算法的研究上,也做了诸多尝试,推出了离线神经网络翻译 (离线 NMT) 、离线文字识别 (离线 OCR) 以及离线文档扫描等移动端实时 AI 能力,并在有道词典、有道翻译官、有道云笔记中进行产品化应用。由于目前移动端 AI 尚处在蓬勃发展阶段,各种框架、计算平台等都尚不完善。
在这里,我们以有道云笔记中的离线文档识别功能作为实践案例,看到了 TFLite 作为一个优秀的移动端AI框架,能够帮助开发者相对轻松地在移动端实现常见的神经网络。后续我们也会为大家带来更多有道技术团队结合 TFLite 在移动端实时 AI 方面的技术探索以及实际产品应用。
-
云脉文档识别在教育行业中的应用2014-03-13 0
-
云上拍客梨视频 基于阿里云的技术实践分享2018-06-28 0
-
ELMOS用于手势识别的光电传感器E527.162018-11-13 0
-
人脸识别的三大模式2019-08-06 0
-
【HarmonyOS HiSpark AI Camera】渔业卫士-基于图像识别的多自由度水下机器人2020-09-25 0
-
自动语音识别的原理是什么?2021-06-15 0
-
如何去实现基于HTTPClient云语音识别的POST请求功能呢2022-03-08 0
-
分享一种在ART-Pi Smart上进行车标识别的设计方案2022-06-02 0
-
如何将DS_CNN_S.pb转换为ds_cnn_s.tflite?2023-04-19 0
-
矩阵按键在识别的过程中是否要进行消抖处理?2023-10-11 0
-
射频识别的构成_射频识别的主要工作频率2020-03-28 5488
-
语音识别的两个方法_语音识别的应用有哪些2020-04-01 5662
-
虹膜识别技术的过程_虹膜识别的发展历程2020-04-02 5393
-
在Android中使用TFLite c++部署2022-02-07 549
-
情感语音识别的研究方法与实践2023-11-16 261
全部0条评论

快来发表一下你的评论吧 !
