

逆向基础之寄存器和内存详解
存储技术
描述
逆向,是安全领域必备的技能之一。但凡有编程经验的人都应该熟知高级语言源代码从编译链接到执行的过程,逆向就是把这个过程反了过来,反病毒人员捕获到样本,需要对其逆向才能分析出该样本的行为,才能开发出有效的专杀工具。
在开始真正接触逆向之前,首先要具备一些汇编的基础知识,之所以说汇编的基础知识,是说搞逆向没有必要精通汇编,因为并不是要求我们成为汇编程序员;学习汇编的道路晦涩难懂,最好的方式是在学习逆向破解的过程中去根据实际需要去学习,那么本文主要介绍的是逆向基础的寄存器和内存方面的信息,首先介绍的是逆向主要是做什么的,其次对编程和机器架构做了个简介,最后详细的阐述了逆向基础的寄存器和内存。
逆向主要是做什么的
1、逆向分析已经编译好的软件,然后使用高级语言重现,可以模仿已有的比较好的软件,供自己创业使用。
2、用于分析病毒,提取出特征码,便于开发杀毒程序。
3、高级代码审计,在汇编层面调试程序,写出来的代码更加安全。
4、外挂,游戏的外挂就是这样产生的,具体就不详细介绍的,毕竟不是光彩的事。
5、分析嵌入式设备中的漏洞。
6、开发嵌入式设备的软件。
汇编语言的位置
为什么要学习汇编语言呢?就像学习美国文化要先懂英语一样,如果不了解计算机的语言,又何谈懂计算机呢?我们知道,计算机执行的语言,或者称之为命令序列或数据,都是以“1和0”的二进制语言,物理上则表现为电信号的高低电平。虽然我们现在有C/C++、Java、Python等一系列强大的高级语言,但是其真正落实到计算机的执行时还是需要编译或解释成计算机懂的机器语言。最早的时候计算机编程就是在纸带上打孔表示1或0,以此作为编程指令,不仅难于操作,而且很难查错,记忆也很困难。于是人们发明了机器语言的“人性化”表示:汇编语言(Assembly language),每条汇编指令都对应着一条机器二进制串,但是却更加容易理解和记忆:

虽然我们现在有许多的高级语言可以用来编程,但是如果想真的理解代码执行的实际过程,还是需要我们去懂些汇编语言,从本质上理解机器的行为。因此当今IT的各位童鞋们学习汇编语言还是十分重要的,逆向就更不用说了。
机器架构
计算机的核心是CPU,负责各种运算,其中又包括运算器和寄存器,寄存器中也用来存储数据,但是一般较小,读写速度快,是运算器直接操作的对象;CPU之外有存储器,存储器一般指内存,分为可读写的RAM和只可读的ROM;其余各种外设比如显卡、网卡等都通过主板上的总线与CPU相连,CPU通过总线同存储器以及各种外设中的芯片(进而同外设中的存储器)进行数据通信。
存储器按字节大小分为存储单元,例如一个字节是一个存储单元。CPU访问存储器时必须完成三件任务:1. 存储单元的地址(地址信息);2. 器件的选择,读或写的命令(控制信息);3. 读或写的数据(数据信息);因此,CPU同各种存储器之间自然而然存在三种总线:地址总线、控制总线与数据总线。
控制总线决定了命令的种类,数据总线决定了一次处理的数据最大位数,8位数据总线处理16位数据时要分两次进行,而16位数据总线一次就能解决问题。地址总线则决定了CPU的寻址能力,即内存的大小,比如8位的地址总线最大只有256个单元,即256字节,而32位的地址总线最多有2的32次幂bit,即4GB,这也是x86最多支持4G内存的原因。


既然说到了4G内存的由来,那么就可以趁热打铁说说内存地址空间了,CPU认识的每个存储单元默认为1字节,因此可以定位的所有内存单元最大就是2的N次幂,N为地址总线长度,因此这个内存地址也就构成了计算机的内存地址空间,即所有可读写的存储器单元必须在这其中,否则就无法为CPU所定位检索。一般的架构是这样的:
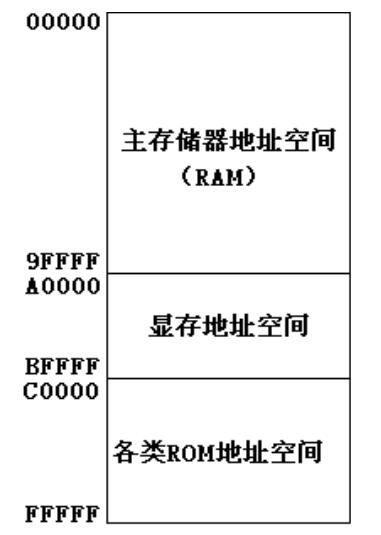
这里0x9ffff是655539,0xbffff是786431,0xfffff是1048575,这样认识的会更清楚些(感谢Python的计算机功能,果然方便)。主存储器地址空间即内存,如果直接操作这个地址空间内的数据,效果就是直接读写内存数据;显存地址空间指的的是显存中的RAM部分。
逆向基础之寄存器和内存
CPU中的主要结构是运算器、控制器与寄存器,这些器件通过CPU的内部总线相连,其中运算器负责信息处理,寄存器负责信息存储,控制器控制各种器件进行工作,内部总线连接各种器件,在它们之间进行数据的传送。对于汇编程序员来说,主要部件是寄存器,因为只有寄存器是我们可以编程直接操作的。不同的CPU架构不同,8086CPU共有14个寄存器,分别是AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW,今天我们先来学习基础的通用寄存器,其余的寄存器在用到时会给予说明。
一、通用寄存器
AX、BX、CX和DX是四个通用寄存器,通常用来存放一般性的数据,后面的分析都在8086CPU中进行。每个通用寄存器是16位,即一次可以处理一个字(2个字节)的数据,但是为了与8086CPU之前的CPU相容,也支持一个字节的寄存器,即AH与AL,类似的还有BH和BL等,CPU操作时会降AH和AL当作独立的寄存器,运算进位时会直接丢弃,因为CPU认为只有一个8位的寄存器而已:
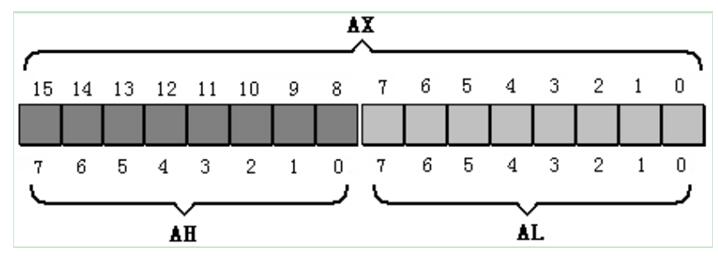
二、物理地址
CPU访问内存需要知晓存储单元的地址,由于8086CPU地址总线为20位,但是寄存器却只有16位,即一次处理的地址最多只有2的16次幂,远小于2的20次幂。为了弥补这个问题,8086CPU采用了一种特殊的方式通过16位的寄存器来构造20位的访问地址,简单来说,即:段地址*16+偏移地址。从计算的位数上来说,段地址和偏移地址存储在CPU寄存器中,都是16位的;段地址*16,即整体在右边添加4个二进制位,成为了20位;20位与16位相加,得到了20位的实际内存地址。这里虽然是8086CPU中的方法,但是其实确实现在所有CPU中的实际寻址算法,即一个基地址加上一个偏移量得到一个实际地址。由此我们可以得到段的概念,内存本身不分段,但是由于CPU的特殊寻址方式,我们可以将内存看作最大64KB的一个个段(16位的最大值正好是64KB),因此我们可以在汇编中人为的指定段的起始和结束。当然,这里的段地址和偏移量实际上存储在CPU的寄存器中,比如获取指令的CS:IP,其中CS为代码段寄存器,其中存储代码段的基地址,IP寄存器则存储着当前要执行的指令的指针,即一个偏移量,因此CS:IP指定了接下来CPU要执行的指令的位置。这里需要说明的是,内存中的数据对于CPU来说都是二进制位,能够区分数据和指令的唯一标准就是指令曾经或者正在被CS:IP指定;每执行完一条指令,IP会累加上条指令的长度,从而指向下调指令。
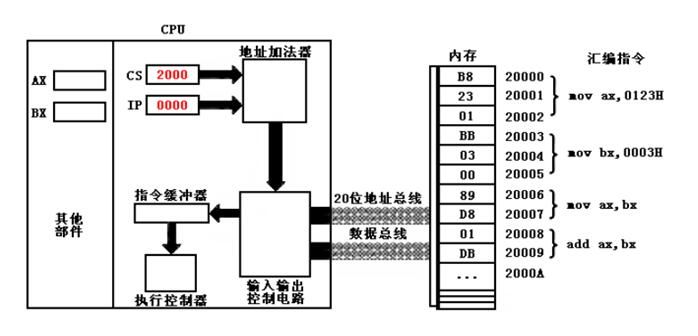
我们是否可以修改控制CS:IP的值呢?答案是肯定的,只不过我们不能使用mov等传送指令,而应当使用jmp这类转移指令,基本的用法是:
-1. 修改CS:IP: jmp 2AE3:3 执行后:CS=2AE3H, IP=0003H;
-2. 仅修改IP:jmp ax(ie. move ip, ax)即用寄存器中的值修改IP;
三、内存访问
CPU访问内存除了获取指令,还要获取数据,那么数据部分如何定位的呢?同指令的CS:IP一样,8086CPU使用DS:[。。。]来获取内存数据地址,其中段寄存器存储内存数据段的基地址,而[。。。]表示一个内存偏移量指向的内存单元,如[0]表示偏移量为0的内存单元,这里使用时要注意,8086CPU不支持直接对DS传送值,因此mov ds, 1000H是非法的,正确地是通过寄存器来实现,即:mov ax, 1000H; mov ds, ax;
这部分我们要学习基本的汇编指令,如mov、sub、add等,都可以操作寄存器,操作完之后将数据放入第一个参数表示的寄存器中。CPU中的内存数据一种特殊的结果就是栈,即只能从一端读写数据的结构,其基本指令是push ax;将寄存器ax的值入栈;和pop ax;从栈中取出栈顶元素放入寄存器ax中;下面是mov\add\sub命令的一个简单示例:
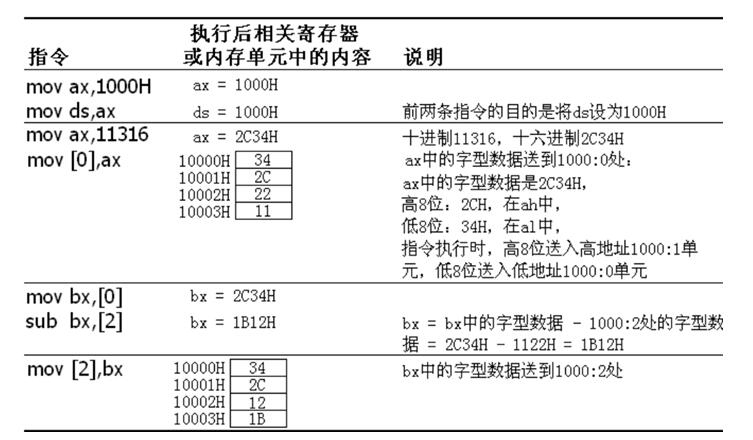
然后我们来看看PUSH命令的执行过程:
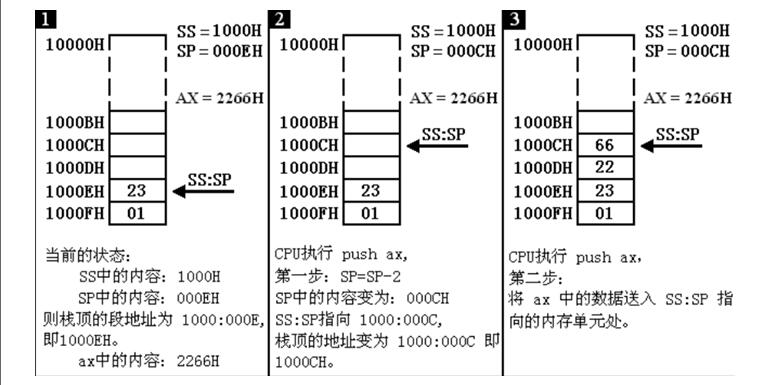
然后是POP命令:
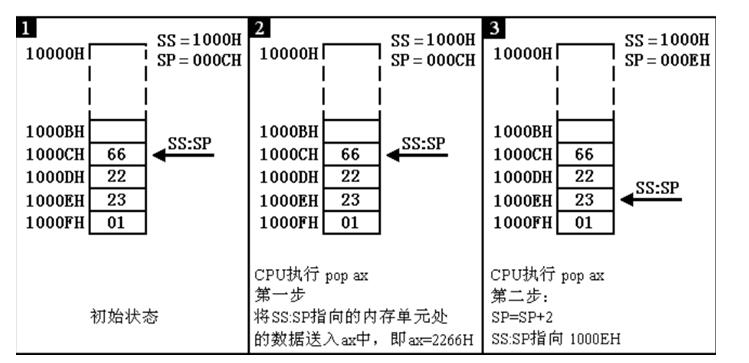
可以看出,栈的操作关键是栈顶位置的确定,因此CPU专门使用SS:SP来获取当前内存中栈顶的位置。值得一提的是,CPU本身并没有对栈的大小进行检查,因此实际中会出现栈顶越界的问题(上限超出-PUSH;下限超出-POP),这也就要求我们必须人为进行检查,否则就会出现程序的漏洞。
-
编程寄存器相关位详解2021-08-12 0
-
ARM寄存器详解2010-07-10 2644
-
DSP2812寄存器详解2016-01-08 907
-
51寄存器的所有寄存器名称,(包括寄存器每一位的作用及用法)资源详解2017-10-16 1067
-
多寄存器Load/Store内存访问指令2017-10-18 1172
-
移位寄存器怎么用_如何使用移位寄存器_移位寄存器的用途2017-12-22 19256
-
为什么寄存器比内存快_原因是这个2018-04-11 6545
-
寄存器比内存快的原理是什么?2018-08-02 5107
-
RFM反射内存5565控制和状态寄存器2018-08-13 667
-
计算机中内存、cache和寄存器之间的关系2019-07-22 4281
-
反射内存卡编程的三个寄存器组2022-04-02 470
-
安卓如何逆向_Dalvik 寄存器,字节码,指令格式 12023-01-30 327
-
安卓如何逆向_Dalvik 寄存器,字节码,指令格式 22023-01-30 343
-
工程监测无线中继采集仪的寄存器(参数)汇总详解2023-05-19 371
-
访问CXL 2.0设备中的内存映射寄存器2023-05-25 1242
全部0条评论

快来发表一下你的评论吧 !
