

融合强化注意力机制和序列优化的图像题注方法
电子说
描述
图像题注旨在为输入图像自动生成自然语言的描述语句,可用于辅助视觉障碍者感知周围环境和帮助人们更便捷地处理大量非结构化视觉信息等场景。当前的主流方法主要是基于深度编码器-解码器框架作端到端的训练优化,但由于视觉概念和语义实体之间对应的偏差,导致在题注中对于图像细粒度语义的识别和理解不足。本文针对此问题,提出了基于检测特征和蒙特卡罗采样的注意力机制和基于改进策略梯度的序列优化(Sequence Optimization)方法,并将二者融合成一个用于图像题注的整体框架。
在我们的方法中,为了更好地提取图像的强语义特征,首先用Faster R-CNN取代一般的卷积网络作为编码器;在此基础上,基于蒙特卡罗采样设计一个强化注意力机制(Reinforce Attention),以筛选出当前时刻值得关注的视觉概念,实现更精准的语义引导。在序列优化阶段,我们利用折扣因子和词频-逆文档频率(TF-IDF)因子改进了策略梯度的评估函数,使得生成题注时具有更强语义性的单词有更大的奖赏值,从而贡献更多的梯度信息,更好地引导序列优化。我们主要在MS COCO数据集上进行训练和评测,模型在当前所有权威的度量指标得分上都取得了显著的提升。以CIDEr指标为例,和当前比较代表性的方法[5]和[7]相比,我们的模型在最终得分上分别提升了8.0%和4.1%。
图像题注旨在为一幅输入图像生成相匹配的自然语言描述,其工作流程如下图1(a)所示。
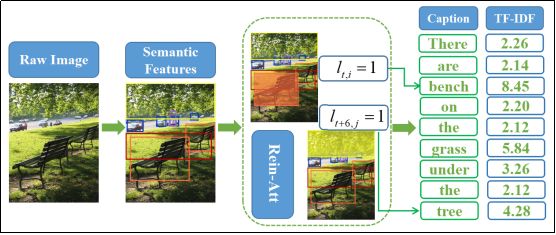
图1(a) 模型前向计算流程
开放域的图像题注是一项颇具挑战的任务,因为它不但需要对图像中的所有局部和全局实体作实现细粒度语义理解,而且还需要生成这些实体间的属性和联系。从学术价值上来看,图像题注领域的研究极大地激发着关于计算机视觉(CV)和自然语言处理(NLP)两大领域如何更好地交叉融合;而在现实应用的维度上,图像题注的进展对于构建一个更好的AI交互系统来说至关重要,尤其是在辅助视觉障碍者更好地感知世界,以及更全面地协助人们更加便捷地组织和理解海量的非结构化视觉信息等方面,有很大的价值。
图像题注领域的研究进展非常快,近期产生了很多标志性的工作。目前基于深度编码器-解码器框架(Encoder-Decoder)的视觉注意力模型(Attention Models),在图像题注的各个标准数据集上都取得了较好的成绩。视觉注意力模型主要用于提取空间显著区域,以更好地映射到待生成词汇。基于此衍生了大量的改进工作,最近有部分研究工作致力于将自底向上(Bottom-up)的物体检测和属性预测方法(Object Detection&Attribute Prediction)和注意力机制融合到一起,在评价指标得分上取得了不错的提升。但所有的这些工作,都采用的是Word-Level的训练和优化方法,这导致了如下两个问题:第一个是“Exposure Bias”,是指模型在训练中根据给定的真实(Ground-Truth)单词去计算下一个单词的最大似然,而在测试中却需要根据实际的生成(Generation)来预测下一个单词;第二个问题是模型在训练和评估中目标的不一致(Inconsistency),因为在训练时采用交叉熵损失函数,而在评估模型生成的题注(Generated Captions)时,却采用的是针对NLP领域专用的一些不可微的度量方法,比如BLEU[11],ROUGE,METEOR和CIDEr等。
为了解决上述问题,最近的一些工作创新性地引入了基于强化学习的优化方法。借助策略梯度和基准函数(Baseline Function)将原先的单词级别(Word-Level)的训练改进成序列化(Sequence-Level)的模式,极大地弥补了原先方案的不足,提升了图像题注的性能。然而,这些方法也存在一些局限,比如在[5]和[10]中,通过一次序列采样生成一句完整题注,得到一个奖赏值(Reward),而后默认所有的单词在梯度优化时共享这一个值。显然,在多数情况下这样是不合理的,因为不同的单词词性不同、语义有侧重、隐含的信息量显著差异,应该被区分为不同的语言实体(Linguistic Entity),在训练中对应不同的视觉概念(Visual Concepts)。为了解决这些问题,我们提出了如下的融合强化注意力机制和序列优化的图像题注方法。
在我们的方法中,首先用Faster R-CNN取代一般的卷积网络作为编码器,对输入图像抽取基于物体检测和属性预测的强语义特征向量(Semantic Features)。之后,我们基于蒙特卡罗采样设计一个强化注意力机制(Reinforce Attention),以筛选出当前时刻值得关注的视觉概念,实现更精准的语义实体引导。在序列优化(Sequence Optimization)阶段,我们采用策略梯度方法计算序列的近似梯度。而在计算每个采样单词的奖赏值时,我们利用折扣因子和词频-逆文档频率(TF-IDF)因子改进了原始的策略梯度函数,使得生成题注时具有更强语义性的单词有更大的奖赏值,从而为训练贡献更多的梯度信息,以更好地引导序列优化。在实验中,我们在MS COCO数据集上的各项性能指标得分均超过了当前的基线方法,证明了方法设计的有效性。
图像题注方法
总体上,图像题注的方法可以被分为两大类:一类是基于模板的(template-based),另一类是基于神经网络的(neural network-based)。前者主要通过一个模板来完成题注生成,而这个模板的填充需要基于对象检测、属性预测和场景理解的输出。而本文中提出的方法采用的是跟后者一致的框架,所以下面我们主要介绍基于神经网络做图像题注的相关工作。
近些年,加载了视觉注意力机制的深度编码器-解码器的一系列工作,在图像题注任务的各个标准数据集上都取得了非常不错的结果。此类方法的核心机制在于:融合了视觉注意力机制的卷积网络和循环网络,能够更好地挖掘隐含的上下文视觉信息,并在端到端地训练充分融合局部和全局的实体信息,从而为题注生成提供更强的泛化能力。之后的很多工作从此出发:一方面是继续强化和改善注意力机制的功效,提出了一些新的计算模块或网络架构;另一方面,部分工作致力于将基于检测框架的特征提取和表征方法与注意力机制融合到一起,以获得更好地实体捕捉能力。
但是目前基于视觉注意力的方法使用交叉熵的纯单词级别(Word-Level)训练模式存在两个显著的缺陷:Exposure Bias和Inconsistency。为了更好地解决这两个问题,基于强化学习的优化方法被引入图像题注任务中。其中尤为代表性的工作是[10],他们将问题重新建模为一个策略梯度优化问题,并采用REINFORCE算法进行优化;为了减小方差、提升训练稳定性,[10]提出了一个混合增量式的训练方法。随后[5][15]等工作基于此做了不同的改进,他们主要是提出了更好的基准函数(Baseline Function),以更大限度地、更高效地提升序列优化的效果。但是当前的这些方法存在的一个显著的局限性是:在对序列梯度进行采样逼近时,默认一句话中的所有单词享有共同的奖赏值。而这显然是不合理的。为了弥补这个缺陷,我们引入了两种优化策略:第一,从强化学习中评估函数的计算出发,引入折扣因子,更精准地计算每一个单词采样回传的梯度值;第二,是从直接度量驱动(Metric-Driven)的初衷出发,将TF-IDF因子引入了奖赏计算中,以更好地发挥强语言实体对于序列整体优化的驱动作用。
方法
我们的模型整体工作框架如图1所示,其中(a)是一个从输入到输出的前向计算流程,(b)为基于强化学习的序列优化过程。下面我们将从语义特征提取,题注生成器和序列优化三个方面,依次递进地介绍我们的方法细节。
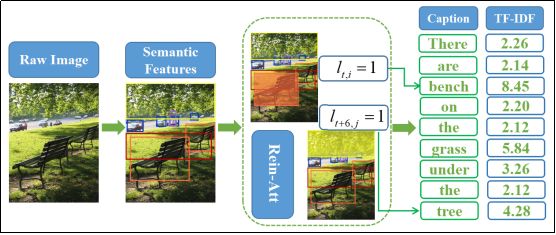
图1(a) 模型前向计算流程
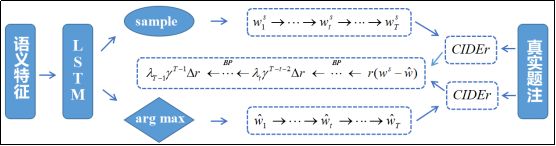
图1(b) 基于强化学习的序列优化过程
1、语义特征(Semantic Features)
对于输入图像,与常用做法不同的是,我们并非提取卷积特征向量,而是基于物体检测和属性预测提取图像的语义特征向量,使得在训练过程中可以更好地与真实题注语句中的语言实体相匹配。在本文中,我们用Faster R-CNN[33]作为图像题注模型中的视觉编码器。给定输入图片Ⅰ,需要输出的语义特征记为:
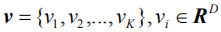
我们对Faster R-CNN最后的输出做一个非极大值抑制(Non-maximum Suppression),对于每一个选中的候选区域 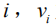
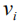
2、题注生成器(Caption Generator)
(1)模型结构和目标函数
给定一幅图像Ⅰ以及相应的语义特征向量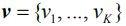
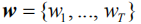
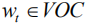
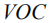
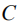
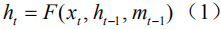
其中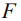
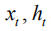
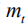
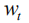
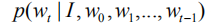
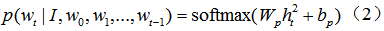
其中,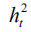
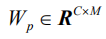
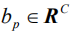
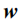
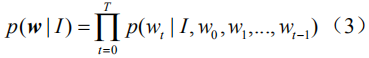
和之前所有Encoder-Decoder框架一样,这里采用交叉熵(XENT)损失函数来训练和优化整个网络,也就是求如下目标函数的极小值:
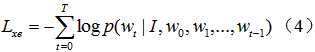
(2)强化注意力机制(Reinforce Attention)
下面我们介绍两层LSTM输入向量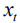
在每一步计算中,第一层的输入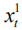
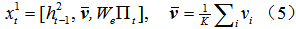
其中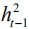
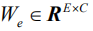
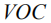
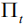
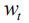
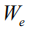
得到第一层的输出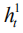
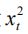
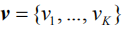
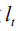
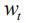
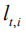

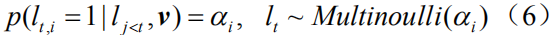
在实际计算中,我们对该分布进行蒙特卡罗采样(MC Sampling)以得到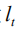
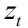
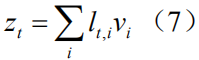
最后我们再次采用串联运算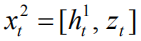
由于上述公式(6)中我们运用了不可微的蒙特卡罗采样,因此我们需要重新定义一个和公式(4)稍有区别的新目标函数。借鉴[19][29]中的工作,我们引入原目标函数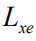
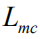
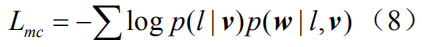
这里我们采用REINFORCE算法[30]来近似计算的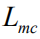
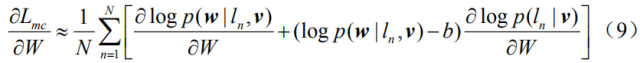
其中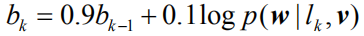
3、序列优化(Sequence-Level Optimization)
为了更直接地优化NLP度量指标,并很好地解决Exposure Bias的问题,我们将图像题注重新建模成一个基于强化学习的序列决策问题。我们可以将上文所述的生成模型视为一个智能体(Agent),与由图像和词汇构成的外部环境(Environment)实时交互。我们定义状态(state)为: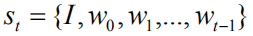
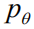
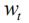
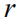
对于图像题注任务,该目标可以公式化为求负的期望累积奖赏的最小值:
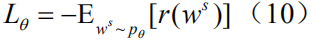
这里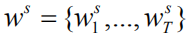
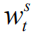
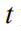
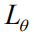
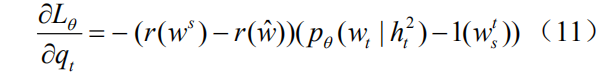
其中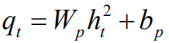
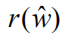
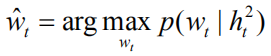
但正如我们在导言中提及的那样,这种计算方式忽视了不同语言实体对于整个序列奖赏值的贡献差异,因此我们提出如下两个改进:(1)我们引入一个折扣因子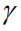
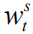
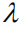
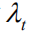
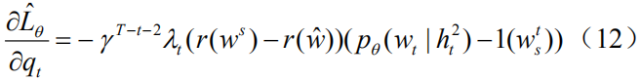
实验
1、数据集(Datasets)
我们在当前图像题注领域最通用的数据集MS COCO[31]上来评测我们提出的方法。该数据集总计有123287张图片,每张图片有5句人工标注的题注作为真实值(Ground Truth),其中划分出训练集82783张和验证集40504张。而测试集是另外的40775张图片,专门用作在线系统测评(Online),官方不公开与之对应的题注真实值。因此,当模型需要在本地(Offline)验证和调试时,我们采用另外的数据集划分标准,从123297张图片集中划分出分别包含5000张图片的验证集和测试集。对于所有题注语句数据的预处理,包括分词和词典生成等,我们采用目前公用的开源代码[https://github.com/karpathy/neuraltalk],去掉不常用的词汇,生成一个包含9487个不同单词的词典(即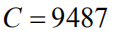
2、实施细节(Implementation Details)
特征提取 在提取语义特征时,我们采用的是一个基于ResNet-101[32]的Faster R-CNN网络。我们设置IoU阈值为0.7用于区域候选框抑制(Suppression),0.3用于物体类别抑制。为了选取显著性图像区域,我们设置了一个0.2检测的检测置信度。在实验中,我们发现每幅图片最多选取到36个显著语义区域,即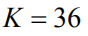
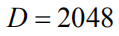
训练部署 每一层LSTM隐藏单元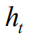
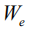
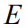
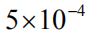
3、结果分析
在本地评测中,我们主要将模型在MS COCO数据集上的结果,和如下三个比较新的代表性模型进行比较:(1)Adaptive Attention[6],标记为AdaAtt;(2)Self-Critical Sequence Training[5],标记为SCST;(3)Bottom up and Top Down Attention[7],标记为BU-Att。比较的结果如表1所示:
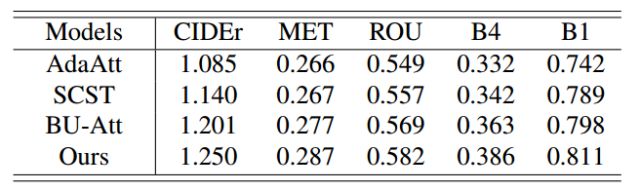
表1 和其他代表性方法的性能对比
这里我们主要记录了5项度量指标,包括CIDEr,METEOR(标记为MET),ROUGLE(标记为ROU),BLEU-4(标记为B-4)和BLEU-1(标记为B-1)。从中我们可以得到如下的结论:(1)我们提出的方法,在图像题注各项评测指标上的得分,都显著性地高于其他三种;(2)四种方法在各项指标上的得分增幅,都基本保持一致。以CIDEr得分为例,我们发现从AdaAtt到BU-Att,再到我们的方法,每一次改进都实现了约5个点的提升。这一定程度上可以说明,我们的这种改进思路,对于图像题注任务更进一步的进展,是具有借鉴意义的。
除此之外,我们分别分析了所提出方法的不同组件(Components)对图像题注性能提升的贡献:(1)首先我们考察只使用Reinforce Attention组件(标记为Reinforce)的性能增益;(2)之后单独考察我们提出的序列优化改进因子,即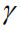
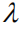
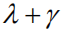
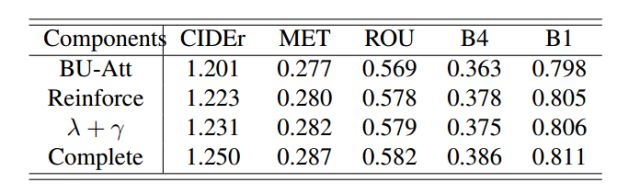
表2 针对模型不同组件的性能分析表
从中我们可以看出:我们改进的两个组件,都分别在BU-Att的基础上实现了各项评测指标得分的显著提升,其中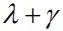

图2 图像题注结果可视化
(其中,图片中的绿框表示Reinforce Attention的结果,语句中的绿框是生成的对应的单词)
结论
本文中,我们提出了一个融合强化注意力机制和序列优化的图像题注方法。首先,我们基于Faster R-CNN检测特征和蒙特卡罗采样设计出强化注意力机制;之后在序列优化阶段,引入折扣因子和TF-IDF因子改进策略梯度的评估函数,使得生成题注时具有更强语义性的单词有更大的奖赏值,从而贡献出更多的梯度信息,更好地引导序列优化。总体上,我们的方法实现了图像和语句之间更好的细粒度语义匹配。通过在MS COCO上的实验,我们验证了方法设计的有效性。
-
基于注意力机制的用户行为建模框架及其在推荐领域的应用2018-01-25 4493
-
深度分析NLP中的注意力机制2019-02-17 3611
-
注意力机制的诞生、方法及几种常见模型2019-03-12 40537
-
注意力机制或将是未来机器学习的核心要素2020-05-07 1149
-
基于注意力机制和多尺度特征融合的网络结构2021-03-22 1052
-
基于特征图注意力机制的图像超分辨重建网络模型2021-03-22 608
-
基于空间/通道注意力机制的化学结构图像识别方法2021-03-22 769
-
融合双层多头自注意力与CNN的回归模型2021-03-25 747
-
基于层次注意力机制的多模态围堵情感识别模型2021-04-01 649
-
结合注意力机制的跨域服装检索方法2021-05-12 549
-
基于多通道自注意力机制的电子病历架构2021-06-24 532
-
基于注意力机制的跨域服装检索方法综述2021-06-27 518
-
基于注意力机制的新闻文本分类模型2021-06-27 695
-
基于非对称注意力机制残差网络的图像检测2021-07-05 680
-
计算机视觉中的注意力机制2023-05-22 196
全部0条评论

快来发表一下你的评论吧 !
