

基于三层级低开销的系统性的缓解FPGA中MBU问题的技术框架
电子说
描述
商用现货型FPGA被认为是解决目前空间应用对处理能力需求不断增加的唯一途径,由于其对多比特翻转的敏感性,需要针对空间应用的单粒子效应采取专门的设计加固技术。提出了基于用户逻辑层、配置存储器层和控制层3个层级的容错技术框架。在用户逻辑层,提出了一种新型的低开销的FTR策略用于用户逻辑的错误检测;在配置存储器级,提出了基于模块和帧的动态部分可重构策略用于处理配置存储器的错误;在控制级,以Xilinx ZYNQ片上系统型FPGA为目标,利用其嵌入的硬核处理器进行基于检查点和卷回体制的电路状态保存和恢复。整个容错技术框架在7级流水的LEON3开源器处理器中进行了故障注入的试验验证,试验结果显示在增加85%的LUT资源和125%的触发器资源使用条件下,99.997%注入的故障得到了及时纠正。
0 引言
商用芯片拥有比宇航级芯片更强的处理能力,但是容易受到单粒子效应的影响。已经有不少学者开展了相关的研究工作,主要是通过持续的全局配置刷新来缓解配置存储器中的错误数据位。在此基础上,提出基于动态部分重构(Dynamic Partial Reconfiguration,DPR)技术对特定区域电路进行重配置,既减少了配置时间,又提高了效率。
另一种可行的处理方式就是在配置存储器内部进行错误检测和编码纠正,通常可以检测2位错误纠正1位错误(Single Error Correction and Double-Error Detection,SEC-DED),但是无法应对多比特翻转(Multiple bit Upset,MBU)的情况[5]。对于用户逻辑电路的容错设计主要有两种方式:一种是进行三模冗余(Triple Modular Redundancy,TMR)设计,主要缺点是代价大;另一种方法是在用户逻辑电路中只进行错误检测,采用复制比较(Duplication With Comparison,DWC)技术,对所有逻辑资源进行复制,增加比较器对结果进行比较。为了进一步减少资源利用,提出在用户逻辑电路中进行错误检测的同时,通过增加一个层级对电路状态进行保存和恢复。
根据上面的分析,目前针对FPGA的软错误技术主要涉及用户逻辑层、配置存储器层和控制层,不同的技术可针对不同的场景,在资源、功耗之间没有针对特殊应用实现针对性的优化。因此,本文在此基础上提出了基于三层级低开销的系统性的缓解FPGA中MBU问题的技术框架,并通过Xilinx ZYNQ平台针对开源的LEON3处理器软核进行了故障注入的仿真验证。
1 三层级软错误缓解技术框架
以最少的资源开销、最低功耗和最短的处理延迟时间为优化目标,通过在用户逻辑层、配置存储器层和控制层3个层级的有效协同,提出了系统性的缓解商用现货型FPGA空间应用面临的MBU能力问题的软错误缓解技术框架,其基于Xilinx ZYNQ SoC(System-on-Chip)的容错技术框架如图1所示。
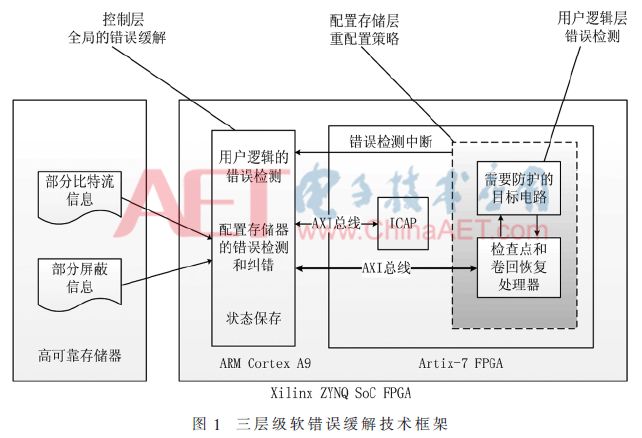
用户逻辑层选择的冗余策略直接影响上层的架构。例如,使用TMR技术进行软错误缓解,需要200%以上的资源开销,不太适用于对资源和功耗都严格受限的空间应用环境,需要以面积和功耗的降低为优化目标,同时尽可能地减少延迟。
配置存储器层选择的策略的延迟和功耗主要依赖于重配置的粒度和检纠错能力,后者主要取决于是对整个配置数据还是只是对内置的纠错编码的冗余信息进行读取和写回。
在控制层,主要考虑的因素也是延迟和功耗,可采用检查点(check pointing)和卷回(rollback)体制,主要的设计参数就是检查点设置的周期。
2 用户逻辑层
在用户逻辑层,有两种较为通用的错误检测方法是:一种是DWC技术,这是一种全硬件备份策略;另一种就是时间冗余(Temporal Redundancy,TR)技术。图2中的组合逻辑和时序逻辑都有两个独立的路径,可以在每个触发器的输出进行比较,这样检测延迟时间最短。图3中采用的是TR技术体制,只对时序逻辑进行冗余,通常是基本电路采用一个时钟,一个延迟时间d的时钟提供给冗余的触发器,这样整个电路的保持时间约束最坏情况是d,建立时间约束不变。该策略可用于在组合逻辑资源开销很低的情况下同时检测时序逻辑中的单粒子翻转和组合逻辑中的单粒子瞬态现象(Single-Event Transients,SET)造成的错误。
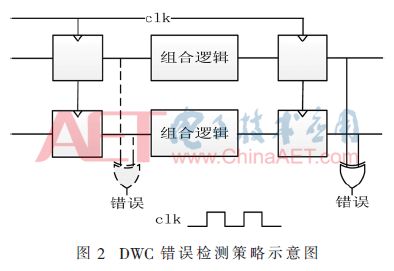
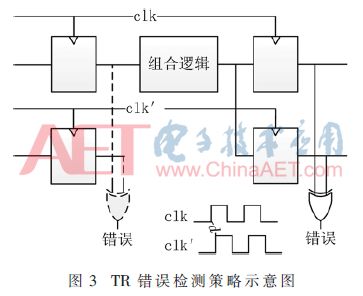
延迟时间d首先要保证能够检测到组合逻辑中全部的SET,因此必须大于SET的最大持续时间。随着工艺尺寸的减少,SET持续时间在增加,对于30 MeV·cm2/mg的LET和130 nm工艺,SET的持续时间为0.2~0.8 ns,Xilinx ZYNQ采用了28 nm工艺技术,延迟在2 ns左右。同时,随着延迟d的增加,需要增加更多延迟布线资源,容易造成竞争冒险现象,极大地降低了最高时钟工作频率。因此,对于高达2 ns的延迟,TR策略的使用十分受限。
为了改进TR策略的适用范围,提出了图4所示的前向时间冗余(Forward Temporal Redundancy,FTR)策略,其与TR的主要区别是延迟是反向的,用于触发器比较的时钟相位提前,电路的保持时间没有变化,但是建立时间约束更加严酷。因此,从clk到clk′时钟域的最大传播延迟减少了d。FTR是一种低功耗和低面积的解决方案,不存在冒险竞争条件。
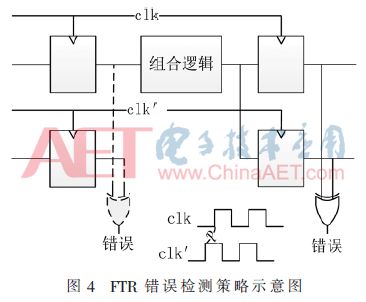
3 配置存储器层
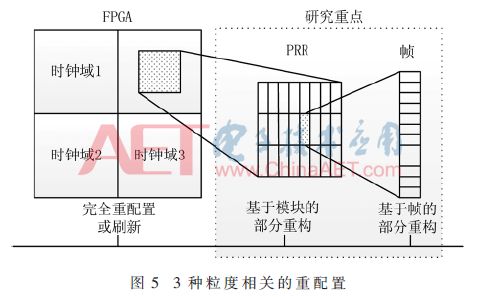
对于配置存储器的重构或者刷新主要有3种不同粒度的操作,如图5所示,第一种就是完全重配置或者刷新,效率比较低;第二种是基于模块的部分重构,适用电路局限在部分重构区域(Partially Reconfigurable Region,PRR);第三种是最好的操作粒度,即基于帧的部分重构,帧是基于地址表的最小单位,对于Xilinx ZYNQ平台,包括101个32 bit字,每一个帧通过对应的帧地址(Frame Address Register,FAR)进行访问,可提供最快的错误检测能力。
为提高检纠错效率,提出了在配置存储器层组合使用基于模块和基于帧的DPR方法:首先,准确定位用户逻辑电路的资源位置,同时提取相应部分的比特流信息,然后实现快速的检错。基于帧的回读可以用于检测PRR内部所有错误。比特流信号中不仅包括配置位,也包括用户存储器单元,这些都可能在电路运行过程中状态进行改变。这些对应比特位必须在回读时通过.mask文件进行屏蔽。
上述方法特别适用于用户电路可以分成多个独立的小PRR的情况,对区域位置定位越准确,PRR越小,延迟就越少,电路的性能也越稳定。
同时,对于硬件错误的处理可以通过比特流的重定位技术,只需要小容量的外部存储器对部分比特流进行存储。
另一种通用的配置存储器保护策略是Xilinx提供的IP核,对整个配置存储器进行监视和错误纠正,这个核在Xilinx ZYNQ中不进行容错设计就需要900个查找表和 700个触发器,资源开销较大。
Xilinx的FPGA支持多种刷新和配置途径,为了尽可能减少延迟,提高系统的可靠性,优选ICAP接口。
4 控制层
控制层主要完成两个任务:协调处理和状态保存。协调处理功能主要分为两部分,一部分与用户逻辑层有关,用于处理用户逻辑中检测到的错误;另一部分与配置存储层有关,用于配置存储器中错误的纠正。状态保存专门用于支持检查点和回滚操作,图6所示为基于Xilinx ZYNQ平台的完整算法描述。
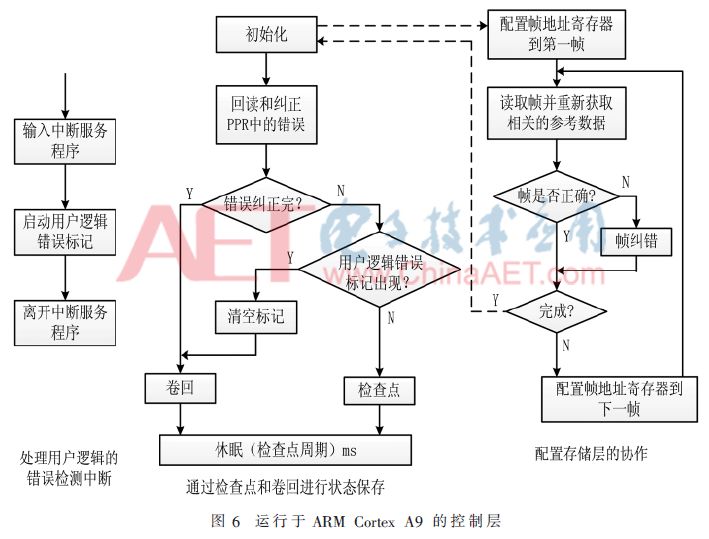
检查点和回滚操作可以通过3种方式实现。第一种是利用FPGA的BRAM存储状态信息,为保证这些信息不会被更改,必须采用合适的保护机制,通常采用内建的SEC-DED-EDAC,不能针对MBU情况。第二种方法是在更高层级进行处理,使用回读捕获特性,通过处理器直接从配置逻辑单元中重新获取状态信息。但是这种方法需要进行专门的布局设计,否则可能造成大的延迟开销。最后一种方法是通过内部数据总线进行传输,比如AXI,可以在多PRR的模块设计中进行共享,与第二种方法类似,重新获取的状态数据可以使用具备更高纠错能力的软件编码进行纠错,或者存储到对单粒子免疫的存储器中来保证数据的正确性,这些数据也可以传回来支持卷回操作。
根据延迟和功耗的折中,选择一个优化的检查点的周期参数,处理器按照时间周期执行任务,这个参数需要根据应用需求进行调整。对于硬实时系统,检查点周期可以减少为0,最小的延迟边界通过回读的时间确定。使用硬核处理器进行控制的方法由于减少了对单粒子敏感的FPGA资源的使用,可提高系统整体的可靠性。
5 利用开源的LEON3处理器核的测试结果
本文采用开源LEON3处理器软核作为基本程序进行测试,其状态单元主要包括程序计数器、寄存器文件和数据存储器,需要通过检查点和回滚操作进行保护。基于Xilinx ZYNQ XC7Z010-1CLG400C平台进行测试。
在用户逻辑层对不同的冗余策略进行量化比较,表1所示为比较的结果。从表中可以看出,FTR策略的结果最好,功耗低,面积开销低,适合空间应用,实现了性能和代价之间的最好平衡。由于更加严格地建立时间约束,与TR相比,FTR策略可以运行的最高工作频率更大。

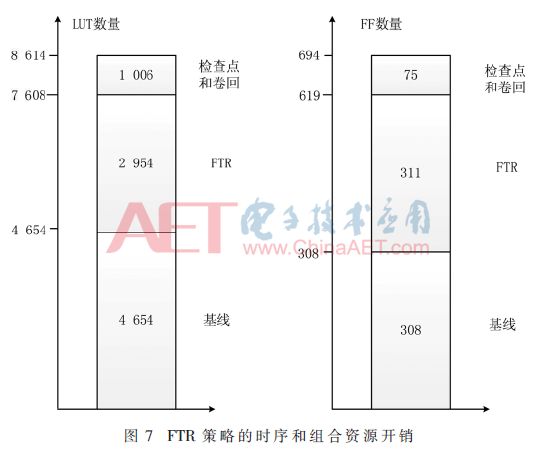
图7所示为全部缓解技术实现需要的资源开销比较,从图中可以看出采用FTR策略,只增加了63%的组合逻辑和101%的时序逻辑资源。
在配置存储器层,位置确定更准确,更能体现FTR的优势,只需要34 μs就可以纠正一个帧中的错误,LEON3处理器包括2 640帧,在90 ms内就可以实现整个PRR的回读,通过优化ICAP端口的速度可以进一步减少时间,最高可以运行到300 MHz。
在控制层,状态信息保存在程序计数器中,寄存器文件和数据存储器中,通过检查点和卷回操作进行保护,并通过AXI总线与硬核处理器连接。这种策略对需要传输的数据量比较敏感,通常片上数据存储器只有几KB,更大的容量需求通过片外存储器提供,片外存储器可以采用复杂检纠错编码。
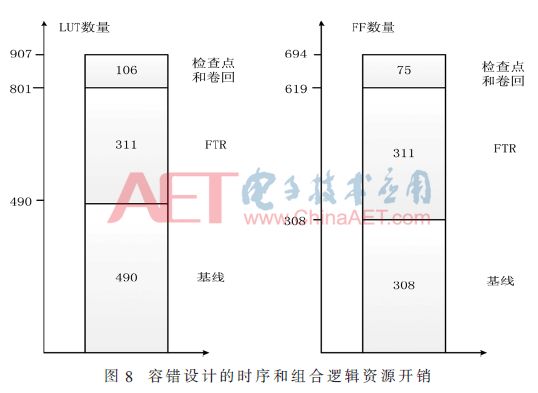
图8显示22%的组合逻辑和24%的时序逻辑开销用于检查点和卷回处理程序。
通过故障注入对整个软件缓解技术框架的有效性进行了验证。首先读取帧对应的地址信息,然后对其中的一个比特位进行翻转,最后把帧数据写回,从而产生一个错误。通过Xilinx产生的.ebd和.ll文件可以找出有效使用的比特信息,试验结果表明99.997%注入的软错误得到纠正。
6 结论
为了满足低成本高性能空间应用处理平台的面积和功耗要求,提出了基于三层级的以功耗、面积、可靠性和延迟特性为目标的优化模型。以LEON3开源处理器软核为基准程序,通过增加85%的组合逻辑和125%时序逻辑资源开销,实现了冗余和状态的保存,比单纯的DWC体制更优。通过故障注入的仿真实验,验证了该框架可有效纠正99.997%的软错误,具备MBU的缓解能力。
-
三层交换机工作原理2008-06-10 0
-
Struts框架技术在J2EE中的研究和应用2009-11-13 0
-
各型号漆包线三层绝缘线规格大全2013-08-27 0
-
EPON系统三层接口设计2019-06-06 0
-
系统层级静电放电与芯片层级静电放电有什么差异2019-07-25 0
-
高频变压器三层绝缘与套管区别2020-03-23 0
-
思创易控cetron-思创漫游3.0 Plus 之三层漫游2020-10-13 0
-
PCB打样过程中为何四层板比三层板更为常见?2020-11-03 0
-
PCB四层板与三层板的区别是什么2021-02-05 0
-
如何提高FPGA的系统性能2021-04-26 0
-
基于三层前馈BP神经网络的图像压缩算法解析2021-05-06 0
-
求一种三层全千兆路由交换机的设计方案2021-05-20 0
-
基于单片机的三层电梯设计实现哪些功能2021-11-19 0
-
浅谈三层架构原理2022-01-16 0
-
锐成芯微推出基于BCD工艺的三层光罩eFlash IP2023-03-03 0
全部0条评论

快来发表一下你的评论吧 !
