

未来的图像识别:更大规模、自我标注
电子说
描述
2017 年 7 月,最后一届 ImageNet 挑战赛落幕。
为何对计算机视觉领域有着重要贡献的 ImageNet 挑战赛,会在 8 年后宣告终结?
毕竟计算机系统在图像识别等任务上的准确率已经超过人类水平,每年一次突破性进展的时代也已经过去。
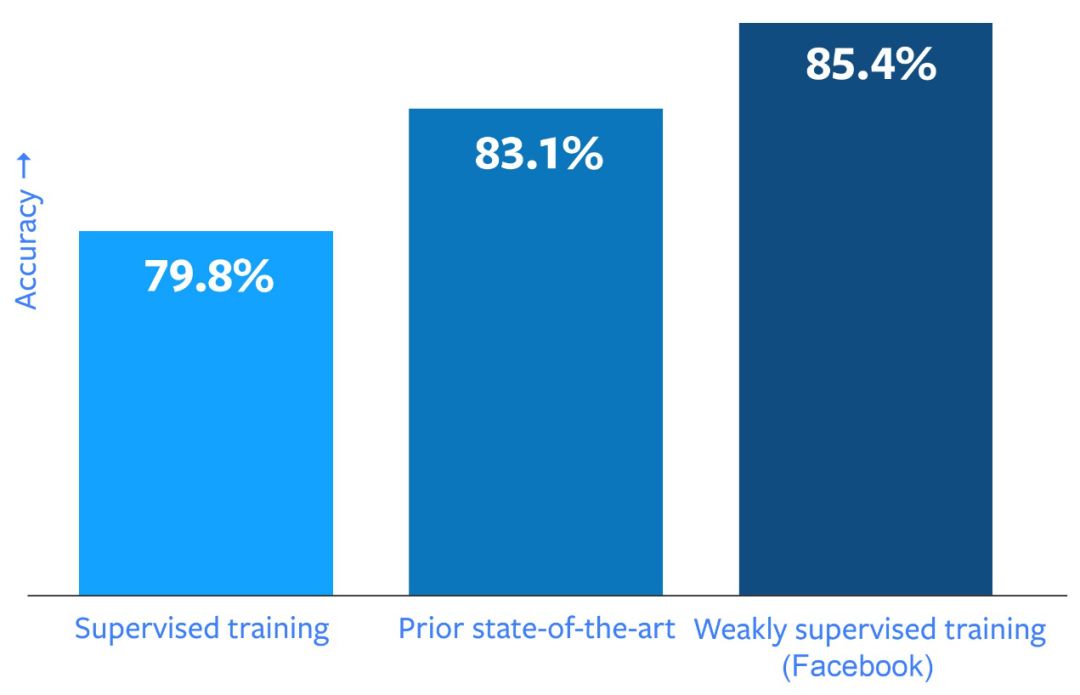
近日,FAIR(Facebook AI Research) 的 Ross Girshick 、何恺明等大神联手,在 ImageNet-1k 图像分类数据集上取得了 85.4% 的准确率,超越了目前的最好成绩,而且没有使用专门为训练深度学习标记的图像作为训练数据。

然而,这不能怪大家不努力,只怪 Facebook 实在太土豪。10 亿张带有 hashtag(类似于微博里面的话题标签)的图片,以及 336 块 GPU,敢问谁能有这种壕气?
Facebook 表示,实验的成功证明了弱监督学习也能有良好表现,当然,只要数据足够多。
话不多说,我们一起来看看 Facebook 是怎样用数据和金钱砸出这个成果的。
以下内容来自 Facebook 官方博客,人工智能头条 编译:
图像识别是人工智能研究的重要领域之一,同时也是 Facebook 的一大重点关注领域。我们的研究人员和工程师希望尽最大的努力打破计算机视觉系统的边界,然后将我们的研究成功应用到现实世界的问题中。为了改进计算机视觉系统的性能,使其能够高效地识别和分类各种物体,我们需要拥有至少数十亿张图像的数据集来作为基础,而不仅仅是百万量级。
目前比较主流的模型通常是利用人工注释的单独标记的数据进行训练,然而在这种情况下,增强系统的识别能力并不是往里面“扔”更多的图片那样简单。监督学习是劳动密集型的,但是它通常能够达到最佳的效果,然而手动标记数据集的大小已经接近极限。尽管 Facebook 正在利用 5000 万幅图像对一些模型进行训练,然而在数据全部需要人工标记的前提下,将训练集扩大到数十亿张是不可能实现。
我们的研究人员和工程师想出了一个解决办法:利用大量带有“hashtag”的公共图像集来训练图像识别网络,其中最大的数据集包括 35 亿张图像以及 17000 种 hashtag。这种方法的关键是使用现有的、公开的、用户提供的 hashtag 作为标签,而不是手动对每张图片进行分类。
这种方法在我们的测试中运行十分良好。我们利用具有数十亿张图像的数据集来训练我们的计算机视觉系统,然后在 ImageNet 上获得了创纪录的高分(准确率达到了 85.4%)。除了在图像识别性能方面实现突破之外,本研究还为如何从监督学习转向弱监督学习转变提供了深刻的洞见:通过使用现有标签——在本文这种情况下指的是 hashtag——而不是专门的标签来训练 AI 模型。我们计划在不久的将来会进行开源,让整个 AI 社区受益。
▌大规模使用 hashtag
由于人们经常用 hashtag 来对照片进行标注,因此我们认为这些图片是模型训练数据的理想来源。人们在使用 hashtag 的主要目的是让其他人发现相关内容,让自己的图片更容易被找到,这种意图正好可以为我们所用。
但是 hashtag 经常涉及非可视化的概念,例如 “#tbt” 代表“throwback Thursday”;有些时候,它们的语义也含糊不清,比如 “#party”,它既可以描述一个活动,也可以描述一个背景,或者两者皆可。为了更好地识别图像,这些标签可以作为弱监督数据,而模糊的或者不相关的 hashtag 则是不相干的标签噪声,可能会混淆深度学习模型。
由于这些充满噪声的标签对我们的大规模训练工作至关重要,我们开发了新的方法:把 hashtag 当作标签来进行图像识别实验,其中包括处理每张图像的多个标签(因为用户往往不会只添加一个 hashtag),对 hashtag 同义词进行排序,以及平衡常见的 hashtag 和少见的 hashtag 的影响。
为了使标签对图像识别训练更加有用,我们团队训练了一个大型的 hashtag 预测模型。这种方法显示了出色的迁移学习结果,这意味着该模型在图像分类上的表现可以广泛适用于其他人工智能系统。
▌在规模和性能上实现突破
如果只是用一台机器的话,将需要一年多的时间才能完成模型训练,因此我们设计了一种可以将该任务分配给 336 个 GPU 的方法,从而将总训练时间缩短至数周。随着模型规模越来越大——这项研究中最大的是 ResNeXt 101-32x48d,其参数超过了 8.61 亿个——这种分布式训练变得越来越重要。此外,我们还设计了一种删除重复值(副本)的方法,以确保训练集和测试集之间没有重叠。
尽管我们希望看到图像识别的性能得到一定提升,但试验结果远超我们的预期。在 ImageNet 图像识别基准测试中(该领域最常见的基准测试),我们的最佳模型通过 10 亿张图像的训练之后(其中包含 1,500 个 hashtag)达到了 85.4% 的准确率,这是迄今为止 ImageNet 基准测试中的最好成绩,比之前最先进的模型的准确度高了 2%。再考虑到卷积网络架构的影响后,我们所观察到的性能提升效果更为显著:在深度学习粒使用数十亿张带有 hashtag 的图像之后,其准确度相对提高了 22.5%。
在 COCO 目标检测挑战中,我们发现使用 hashtag 预训练可以将模型的平均精度(average precision)提高 2% 以上。
这些图像识别和物体检测领域的基础改进,代表了计算机视觉又向前迈出了一步。但是除此之外,该实验也揭示了与大规模训练和噪声标签相关的挑战和机遇。
例如,尽管增加训练数据集规模的大小是值得的,但选择与特定识别任务相匹配的一组 hashtag 也同样重要。我们选择了 10 亿张图像以及 1,500 个与 ImageNet 数据集中的类相匹配的 hashtag,相比同样的图像加上 17,000 个 hashtag,前者训练出来的模型取得了更好的成绩。另一方面,对于图像类别更多更广泛的任务,使用 17,000 个主 hashtag 训练出来模型性能改进的更加明显,这表明我们应该在未来的训练中增加 hashtag 的数量。
增加训练数据量通常对图像分类模型的表现是有益,但它同样也有可能会引发新的问题,如在图像内定位物体的能力明显下降。除此之外我们还观察到,实验中最大的模型仍然没有能够充分利用 35 亿张巨大图像集的优势,这表明我们应该构建更大的模型。
▌未来的图像识别:更大规模、自我标注
本次研究的一个重要结果,甚至比在图像识别方面的广泛收益还要重要,是确认了基于 hashtag 来训练计算机视觉模型是完全可行的。虽然我们使用了一些类似融合相似的 hashtag,降低其他 hashtag 权重的基本技术,但并不需要复杂的“清洗”程序来消除标签噪声。相反,我们能够使用 hashtag 来训练我们的模型,而且只需要对训练过程进行微小的调整。当训练集的规模达到十亿级时,我们的模型对标签噪音表现出了显著的抗干扰能力,因此数据集的规模在这里显然是一个优势。
在不久的将来,我们还会设想使用 hashtag 作为计算机视觉标签的其他方法。这些方法可能包括使用人工智能来更好地理解视频片段或更改图片在 Facebook 信息流中的排名方式。hashtag 还可以帮助系统更具体地识别图像是不是属于更细致的子类别,而不仅仅是宽泛的分类。一般情况下,图片的音频字幕都是仅宽泛地注释出物种名称,如“图片中有一些鸟类栖息”,但如果我们能够让注释更加精确(例如“一只红雀栖息在糖枫树上”),就可以为视障用户提供更加准确的描述。

此外,这项研究还可以改进新产品以及现有产品中的图像识别功能带来。例如,更准确的模型可能会促进我们改进在 Facebook 上呈现 Memories(与QQ的“日迹”相似)的方式。随着训练数据集越来越大,我们需要应用弱监督学习——而且从长远来看,无监督学习会变得越来越重要。
这项研究在论文“Exploring the Limits of Weakly Supervised Pretraining”中有更详细的描述。
-
基于DSP的快速纸币图像识别技术研究2014-11-05 0
-
怎么做图像识别?2015-07-22 0
-
【NUCLEO-F412ZG申请】图像识别2016-11-07 0
-
基于vuforia的图像识别Jar的使用2018-09-20 0
-
基于STM32F7高性能单片机的图像识别开发——OPENMV2019-12-04 0
-
图像识别模组(包括PCB图、图像识别模组源代码)2009-01-02 761
-
MATLAB图像识别物体计数2010-02-08 2215
-
利用Jetson TK1为低功耗图像识别挑战做好准备2018-05-08 8776
-
如何实现图像识别?为什么要入局图像识别?2018-08-29 7722
-
深度学习在图像识别领域的四大方向2018-12-01 31011
-
图像识别技术 推动智能科技时代发展2020-06-18 3277
-
Food2K:大规模食品图像识别2023-05-17 1651
-
图像识别技术原理 深度学习的图像识别应用研究2023-07-19 283
-
模拟矩阵在图像识别中的应用2023-09-04 321
-
图像识别技术原理 图像识别技术的应用领域2024-02-02 620
全部0条评论

快来发表一下你的评论吧 !
