

GitHub上最受欢迎的28款开源的机器学习项目,TensorFlow位列其中
人工智能
描述
现在机器学习逐渐成为行业热门,经过二十几年的发展,机器学习目前也有了十分广泛的应用,如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、DNA序列测序、语音和手写识别、战略游戏和机器人等方面。
云栖社区特意翻译整理了目前GitHub上最受欢迎的28款开源的机器学习项目,以供开发者参考使用。
1. TensorFlow
TensorFlow 是谷歌发布的第二代机器学习系统。据谷歌宣称,在部分基准测试中,TensorFlow的处理速度比第一代的DistBelief加快了2倍之多。
具体的讲,TensorFlow是一个利用数据流图(Data Flow Graphs)进行数值计算的开源软件库:图中的节点( Nodes)代表数学运算操作,同时图中的边(Edges)表示节点之间相互流通的多维数组,即张量(Tensors)。这种灵活的架构可以让使用者在多样化的将计算部署在台式机、服务器或者移动设备的一个或多个CPU上,而且无需重写代码;同时任一基于梯度的机器学习算法均可够借鉴TensorFlow的自动分化(Auto-differentiation);此外通过灵活的Python接口,要在TensorFlow中表达想法也变得更为简单。
TensorFlow最初由Google Brain小组(该小组隶属于Google's Machine Intelligence研究机构)的研究员和工程师开发出来的,开发目的是用于进行机器学习和深度神经网络的研究。但该系统的通用性足以使其广泛用于其他计算领域。
目前Google 内部已在大量使用 AI 技术,包括 Google App 的语音识别、Gmail 的自动回复功能、Google Photos 的图片搜索等都在使用 TensorFlow 。
开发语言:C++
许可协议:Apache License 2.0
GitHub项目地址:https://github.com/tensorflow/tensorflow
2. Scikit-Learn
Scikit-Learn是用于机器学习的Python 模块,它建立在SciPy之上。该项目由David Cournapeau 于2007年创立,当时项目名为Google Summer of Code,自此之后,众多志愿者都为此做出了贡献。
主要特点:
操作简单、高效的数据挖掘和数据分析
无访问限制,在任何情况下可重新使用
建立在NumPy、SciPy 和 matplotlib基础上
Scikit-Learn的基本功能主要被分为六个部分:分类、回归、聚类、数据降维、模型选择、数据预处理,具体可以参考官方网站上的文档。经过测试,Scikit-Learn可在 Python 2.6、Python 2.7 和 Python 3.5上运行。除此之外,它也应该可在Python 3.3和Python 3.4上运行。
注:Scikit-Learn以前被称为Scikits.Learn。
开发语言:Python
许可协议:3-Clause BSD license
GitHub项目地址:https://github.com/scikit-learn/scikit-learn
3.Caffe
Caffe 是由神经网络中的表达式、速度、及模块化产生的深度学习框架。后来它通过伯克利视觉与学习中心((BVLC)和社区参与者的贡献,得以发展形成了以一个伯克利主导,然后加之Github和Caffe-users邮件所组成的一个比较松散和自由的社区。
Caffe是一个基于C++/CUDA架构框架,开发者能够利用它自由的组织网络,目前支持卷积神经网络和全连接神经网络(人工神经网络)。在Linux上,C++可以通过命令行来操作接口,对于MATLAB、Python也有专门的接口,运算上支持CPU和GPU直接无缝切换。
Caffe的特点
易用性:Caffe的模型与相应优化都是以文本形式而非代码形式给出, Caffe给出了模型的定义、最优化设置以及预训练的权重,方便快速使用;
速度快:能够运行最棒的模型与海量的数据;
Caffe可与cuDNN结合使用,可用于测试AlexNet模型,在K40上处理一张图片只需要1.17ms;
模块化:便于扩展到新的任务和设置上;
使用者可通过Caffe提供的各层类型来定义自己的模型;
目前Caffe应用实践主要有数据整理、设计网络结构、训练结果、基于现有训练模型,使用Caffe直接识别。
开发语言:C++
许可协议: BSD 2-Clause license
GitHub项目地址:https://github.com/BVLC/caffe
4. PredictionIO
PredictionIO 是面向开发人员和数据科学家的开源机器学习服务器。它支持事件采集、算法调度、评估,以及经由REST APIs的预测结果查询。使用者可以通过PredictionIO做一些预测,比如个性化推荐、发现内容等。PredictionIO 提供20个预设算法,开发者可以直接将它们运行于自己的数据上。几乎任何应用与PredictionIO集成都可以变得更“聪明”。其主要特点如下所示:
基于已有数据可预测用户行为;
使用者可选择你自己的机器学习算法;
无需担心可扩展性,扩展性好。
PredictionIO 基于 REST API(应用程序接口)标准,不过它还包含 Ruby、Python、Scala、Java 等编程语言的 SDK(软件开发工具包)。其开发语言是Scala语言,数据库方面使用的是MongoDB数据库,计算系统采用Hadoop系统架构。
开发语言:Scala
许可协议:Apache License 2.0
GitHub项目地址:https://github.com/PredictionIO/PredictionIO
5. Brain
Brain是 JavaScript 中的 神经网络库。以下例子说明使用Brain来近似 XOR 功能:
var net = new brain.NeuralNetwork();net.train([{input: [0, 0], output: [0]},{input: [0, 1], output: [1]},{input: [1, 0], output: [1]},{input: [1, 1], output: [0]}]);var output = net.run([1, 0]);// [0.987]
当 brain 用于节点中,可使用npm安装:
npm install brain
当 brain 用于浏览器,下载最新的 brain.js 文件。训练计算代价比较昂贵,所以应该离线训练网络(或者在 Worker 上),并使用 toFunction()或者toJSON()选项,以便将预训练网络插入到网站中。
开发语言:JavaScript
GitHub项目地址:https://github.com/harthur/brain
6. Keras
Keras是极其精简并高度模块化的神经网络库,在TensorFlow 或 Theano 上都能够运行,是一个高度模块化的神经网络库,支持GPU和CPU运算。Keras可以说是Python版的Torch7,对于快速构建CNN模型非常方便,同时也包含了一些最新文献的算法,比如Batch Noramlize,文档教程也很全,在官网上作者都是直接给例子浅显易懂。Keras也支持保存训练好的参数,然后加载已经训练好的参数,进行继续训练。
Keras侧重于开发快速实验,用可能最少延迟实现从理念到结果的转变,即为做好一项研究的关键。
当需要如下要求的深度学习的库时,就可以考虑使用Keras:
考虑到简单快速的原型法(通过总体模块性、精简性以及可扩展性);
同时支持卷积网络和递归网络,以及两者之间的组合;
支持任意连接方案(包括多输入多输出训练);
可在CPU 和 GPU 上无缝运行。
Keras目前支持 Python 2.7-3.5。
开发语言:Python
GitHub项目地址:https://github.com/fchollet/keras
7. CNTK
CNTK(Computational Network Toolkit )是一个统一的深度学习工具包,该工具包通过一个有向图将神经网络描述为一系列计算步骤。在有向图中,叶节点表示输入值或网络参数,其他节点表示该节点输入之上的矩阵运算。
CNTK 使得实现和组合如前馈型神经网络DNN、卷积神经网络(CNN)和循环神经网络(RNNs/LSTMs)等流行模式变得非常容易。同时它实现了跨多GPU 和服务器自动分化和并行化的随机梯度下降(SGD,误差反向传播)学习。
下图将CNTK的处理速度(每秒处理的帧数)和其他四个知名的工具包做了比较了。配置采用的是四层全连接的神经网络(参见基准测试脚本)和一个大小是8192 的高效mini batch。在相同的硬件和相应的最新公共软件版本(2015.12.3前的版本)的基础上得到如下结果:
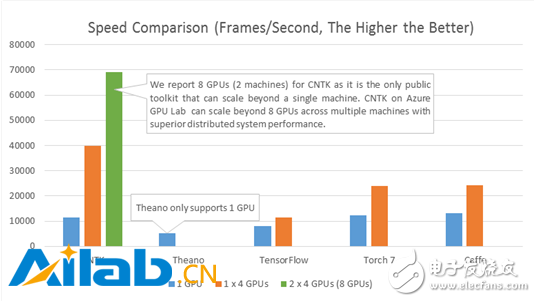
CNTK自2015年四月就已开源。
开发语言:C++
GitHub项目地址:https://github.com/Microsoft/CNTK
8. Convnetjs
ConvNetJS是利用Javascript实现的神经网络,同时还具有非常不错的基于浏览器的Demo。它最重要的用途是帮助深度学习初学者更快、更直观的理解算法。
它目前支持:
常见的神经网络模块(全连接层,非线性);
分类(SVM/ SOFTMAX)和回归(L2)的成本函数;
指定和训练图像处理的卷积网络;
基于Deep Q Learning的实验强化学习模型。
一些在线示例:
Convolutional Neural Network on MNIST digits
Convolutional Neural Network on CIFAR-10
Toy 2D data
Toy 1D regression
Training an Autoencoder on MNIST digits
Deep Q Learning Reinforcement Learning demo+Image Regression ("Painting")+Comparison of SGD/Adagrad/Adadelta on MNIST开发语言:Javascript 许可协议:MIT License GitHub项目地址:https://github.com/karpathy/convnetjs
9. Pattern

Pattern是Python的一个Web挖掘模块。拥有以下工具:
数据挖掘:网络服务(Google、Twitter、Wikipedia)、网络爬虫、HTML DOM解析;
自然语言处理:词性标注工具(Part-Of-Speech Tagger)、N元搜索(n-gram search)、情感分析(sentiment analysis)、WordNet;
机器学习:向量空间模型、聚类、分类(KNN、SVM、 Perceptron);
网络分析:图形中心性和可视化。
其文档完善,目前拥有50多个案例和350多个单元测试。 Pattern目前只支持Python 2.5+(尚不支持Python 3),该模块除了在Pattern.vector模块中使用LSA外没有其他任何外部要求,因此只需安装 NumPy (仅在Mac OS X上默认安装)。
开发语言:Python
许可协议:BSD license
GitHub项目地址:https://github.com/clips/pattern
10. NuPIC
NuPIC是一个实现了HTM学习算法的机器智能平台。HTM是一个关于新(大脑)皮质(Neocortex)的详细人工智能算法。HTM的核心是基于时间的连续学习算法,该算法可以存储和调用时间和空间两种模式。NuPIC可以适用于解决各类问题,尤其是异常检测和流数据源预测方面。
NuPIC Binaries文件目前可用于:
Linux x86 64bit
OS X 10.9
OS X 10.10
Windows 64bit
NuPIC 有自己的独特之处。许多机器学习算法无法适应新模式,而NuPIC的运作接近于人脑,当模式变化的时候,它会忘掉旧模式,记忆新模式。
开发语言:Python
GitHub项目地址:https://github.com/numenta/nupic
11. Theano
Theano是一个Python库,它允许使用者有效地定义、优化和评估涉及多维数组的数学表达式,同时支持GPUs和高效符号分化操作。Theano具有以下特点:
与NumPy紧密相关--在Theano的编译功能中使用了Numpy.ndarray ;
透明地使用GPU--执行数据密集型计算比CPU快了140多倍(针对Float32);
高效符号分化--Theano将函数的导数分为一个或多个不同的输入;
速度和稳定性的优化--即使输入的x非常小也可以得到log(1+x)正确结果;
动态生成 C代码--表达式计算更快;
广泛的单元测试和自我验证--多种错误类型的检测和判定。
自2007年起,Theano一直致力于大型密集型科学计算研究,但它目前也很被广泛应用在课堂之上( 如Montreal大学的深度学习/机器学习课程)。
开发语言:Python
GitHub项目地址:https://github.com/Theano/Theano
12. MXNet
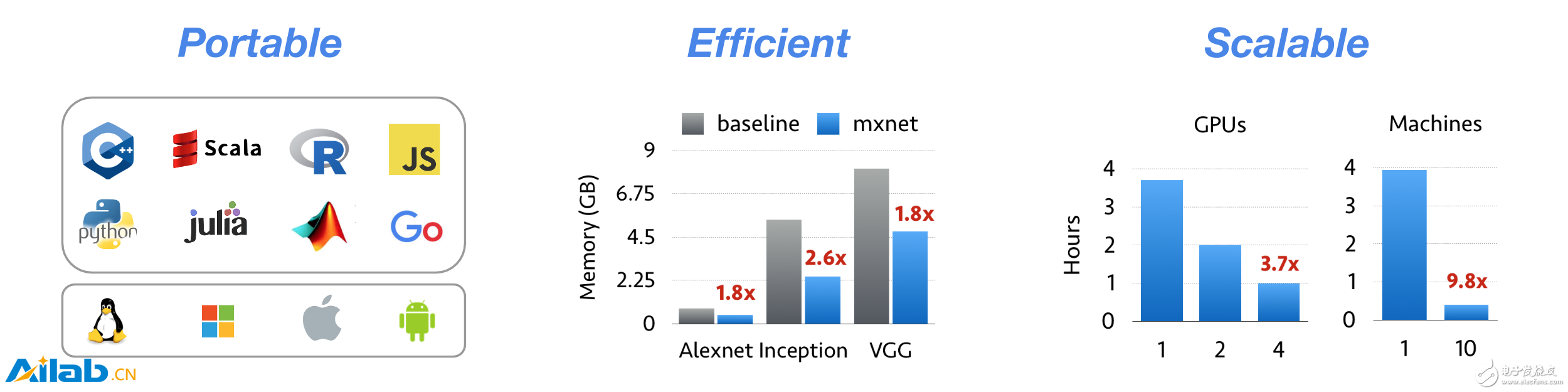
MXNet是一个兼具效率和灵活性的深度学习框架。它允许使用者将符号编程和命令式编程相结合,以追求效率和生产力的最大化。其核心是动态依赖调度程序,该程序可以动态自动进行并行化符号和命令的操作。其中部署的图形优化层使得符号操作更快和内存利用率更高。该库轻量且便携带,并且可扩展到多个GPU和多台主机上。
主要特点:
其设计说明提供了有用的见解,可以被重新应用到其他DL项目中;
任意计算图的灵活配置;
整合了各种编程方法的优势最大限度地提高灵活性和效率;
轻量、高效的内存以及支持便携式的智能设备;
多GPU扩展和分布式的自动并行化设置;
支持Python、R、C++和 Julia;
对“云计算”友好,直接兼容S3、HDFS和Azure。
MXNet不仅仅是一个深度学习项目,它更是一个建立深度学习系统的蓝图、指导方针以及黑客们对深度学习系统独特见解的结合体。
开发语言:Jupyter Notebook
开源许可:Apache-2.0license
GitHub项目地址:https://github.com/dmlc/mxnet
13. Vowpal Wabbit
Vowpal Wabbit是一个机器学习系统,该系统推动了如在线、散列、Allreduce、Learning2search、等方面机器学习前沿技术的发展。 其训练速度很快,在20亿条训练样本,每个训练样本大概100个非零特征的情况下:如果特征的总位数为一万时,训练时间为20分钟;特征总位数为1000万时,训练时间为2个小时。Vowpal Wabbit支持分类、 回归、矩阵分解和LDA。
当在Hadoop上运行Vowpal Wabbit时,有以下优化机制:
懒惰初始化:在进行All Reduce之前,可将全部数据加载到内存中并进行缓存。即使某一节点出现了错误,也可以通过在另外一个节点上使用错误节点的数据(通过缓存来获取)来继续训练。
Speculative Execution:在大规模集群当中,一两个很慢的Mapper会影响整个Job的性能。Speculative Execution的思想是当大部分节点的任务完成时,Hadoop可以将剩余节点上的任务拷贝到其他节点完成。
开发语言:C++
GitHub项目地址:https://github.com/JohnLangford/vowpal_wabbit
14. Ruby Warrior
通过设计了一个游戏使得Ruby语言和人工智能学习更加有乐趣和互动起来。
使用者扮演了一个勇士通过爬上一座高塔,到达顶层获取珍贵的红宝石(Ruby)。在每一层,需要写一个Ruby脚本指导战士打败敌人、营救俘虏、到达楼梯。使用者对每一层都有一些认识,但是你永远都不知道每层具体会发生什么情况。你必须给战士足够的人工智能,以便让其自行寻找应对的方式。
勇士的动作相关API:
Warrior.walk: 用来控制勇士的移动,默认方向是往前;
warrior.feel:使用勇士来感知前方的情况,比如是空格,还是有怪物;
Warrior.attack:让勇士对怪物进行攻击;
Warrior.health:获取勇士当前的生命值;
Warrior.rest:让勇士休息一回合,恢复最大生命值的10%。
勇士的感知API:
Space.empty:感知前方是否是空格;
Space.stairs:感知前方是否是楼梯;
Space.enemy: 感知前方是否有怪物;
Space.captive:感知前方是否有俘虏;
Space.wall:感知前方是否是墙壁。
开发语言:Ruby
GitHub项目地址:https://github.com/ryanb/ruby-warrior
以上为GitHub上最流行的开源机器学习项目TOP14,“28款GitHub最流行的开源机器学习项目(二)”。
- 相关推荐
- 机器学习
- GitHub
- tensorflow
-
5月份Github上最热门的数据科学和机器学习项目榜单概述2019-07-29 0
-
TensorFlow是什么2020-07-22 0
-
TensorFlow的特点和基本的操作方式2020-11-23 0
-
2021年最受工程师欢迎的技能:Python第一2021-06-30 0
-
Python机器学习库和深度学习库总结2017-11-10 748
-
最受欢迎的七种商用开源编程语言的全面报告2018-01-15 6187
-
16个GitHub值得收藏的深度学习框架2018-05-10 1476
-
GitHub上25个最受欢迎的开源机器学习库2018-11-14 5715
-
机器学习框架Tensorflow 2.0的这些新设计你了解多少2018-11-17 3003
-
GitHub年度报告:Python首次击败Java2019-11-22 2381
-
deepin被评2019年度最受欢迎中国开源软件2019-12-31 2246
-
十大最受欢迎的Linux发行版2020-09-07 4916
-
多款Intel 9代酷睿斩获最受欢迎CPU大奖2021-01-19 2252
-
PyTorch1.8和Tensorflow2.5该如何选择?2021-07-09 1306
-
最受欢迎的过载踏板伊巴内兹TS808开源分享2022-07-21 631
全部0条评论

快来发表一下你的评论吧 !
