

基于姿态信息生成全身的高分辨率图像的新框架
电子说
描述
近日,和任天堂关系密切的日本网络服务公司DeNA发布了一篇颇为有趣的文章:Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks,即用PSGAN生成高分辨率的全身动画。据了解,DeNA的业务涵盖社交游戏、电子商务等领域,此前公司推出的手游《忍者天下》也在中国市场取得了骄人的成绩。昔日忍者化身换装暖暖,DeNA想用GAN做些什么呢?
以下是论智对文章的编译。
摘要
本文提出了一种渐进结构—条件生成对抗网络(PSGAN),它是一个能基于姿态信息生成全身的高分辨率图像的新框架。
近年来,许多人都研究过用深度生成模型自动生成图像和视频,这项技术对媒体创建工具来说很有帮助,它可以被用来进行图片编辑、动画制作甚至是电影制作。
就动漫产业角度看,一个能自动生成动画角色的神经网络不仅能为创作者带来诸多灵感,它还能为整个产业节省作画上巨额开支。现在我们已经有了能生成人物脸部图像的GAN,但还没有能生成角色全身图的工具。而且就这些生成脸部图像的神经网络来说,它们的图像质量还达不到工业级作画标准。
因此,开发一个既能生成全身图像,又能生成高质量姿态的GAN将对制作新角色、绘制新动漫大有裨益。但达成这个目标还有两大难点:(1)生成高分辨率图像;(2)用特定的姿态序列生成图像。
为了解决上述问题,我们引入PSGAN,它能根据结构信息,在训练过程中逐步提高生成图像的分辨率,以此细化图像在结构上的细节特征,如生成对象的全身图。同时,我们也在网络上添加了任意的潜在变量和结构条件,让它能基于目标姿势序列生成多样化和可控制的动作视频。
在这篇文章中,我们用实验证明了PSGAN的有效性,如下文这个512x512的视频所示,视频中的动画角色展示了PSGAN生成的人物服装细节、身体姿态的整体调整。
生成结果预览
视频展示了由PSGAN生成的各种动漫角色和动画。首先,我们用随机潜在变量生成大量动画角色;其次,我们再对具体的动漫角色进行潜在插值,以生成新的动画角色;最后,我们用连续的姿势序列制作出流畅的动画。
换装PLAY
PSGAN生成全新全身图的主要方式是插入不同的服饰,这是利用改变潜在变量实现的。需要注意的一点是,换装时人物的姿态是固定的。
舞动人“身”
下图展示了指定动画角色生成目标姿态的具体过程:
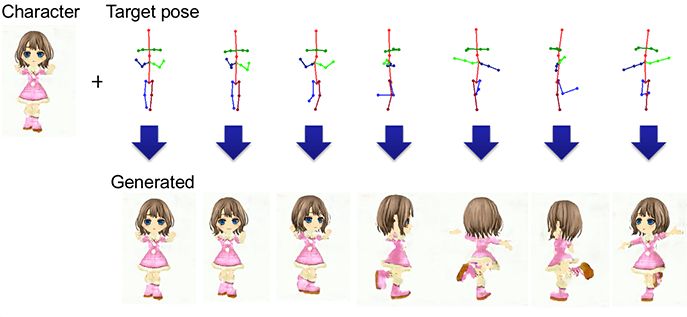
和生成服饰相反,这里我们固定潜在变量,并给PSGAN提供连续的姿势序列。更具体地说,就是将指定动画角色的表示映射到潜在变量内——它处于潜在空间诶,是PSGAN的输入向量——然后用这个新的潜在变量做PSGAN的输入,以此做到在不改变外观的前提下改变姿态。
渐进结构的条件GAN
我们的主要想法是逐步学习具有结构条件的图像表示。我们参考了Karras等人提出的GAN的结构,并在生成器和判别器上都添加上结构条件,这样做之后,无论图像分辨率是什么,它们都带有相应缩放比例的姿态信息。
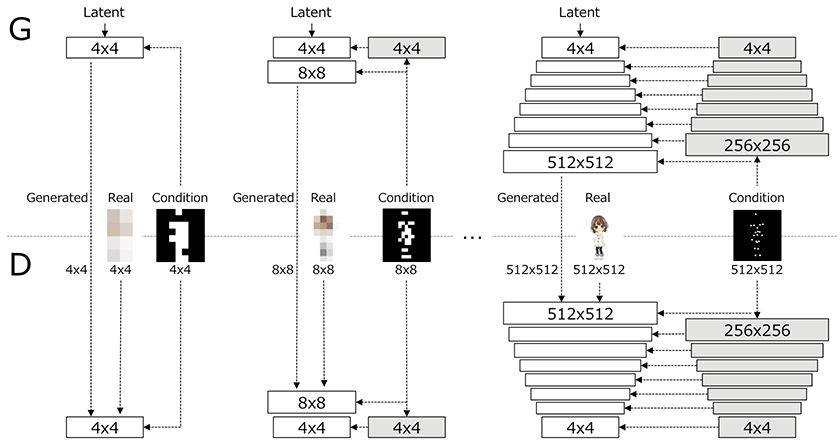
PSGAN的生成器和判别器
如上图所示,N×N的白色框表示的是NxN空间分辨率下正在工作的可学习卷积层,灰色框表示的则是结构条件的不可学习的下采样层。
训练数据
本文用到的数据集有Unity合成的原始头像动漫角色数据集,以及由Openpose检测到的关键点的DeepFashion数据集。PSGAN的训练要求是有成对的图像和成对的关键点坐标。
Avatar Anime-Character数据集
我们按照以下3个要求为PSGAN重新构建了新数据集:
姿态多样性。为了生成平滑、自然地图像,我们需要各式各样的姿态。
训练图像的数量。通过用Unity生成3D头像,我们无需任何手动注释就可以获得大量带注释的合成图像。
背景消除。我们把背景统一设置成白色,以避免不必要的信息对图像产生负面干扰。
我们把单个角色的几个连续动作分解成600个姿势,并不捉每个姿势的关键点。通过对79种服饰进行同样的处理,我们最终获得了47,400张图像。此外,我们还根据3D模型的骨骼结构获得了20个关键点。
下图是几个训练样本(上:动漫角色;下:姿态图):
对于这个数据集,我们用Adam收敛网络,其中β1= 0,β2= 0.99。当生成器中的图像分辨率为4x4—64x64时,学习率为0.001。随着尺寸逐渐变为128x128、256x256、512x512,学习率也逐渐降低为0.0008、0.0006和0.0002。
DeepFashion数据集
PSGAN利用姿态信息在图像生成网络上施加结构条件。我们使用Openpose从没有关键点注释的图像中提取关键点坐标。
同样的,这里我们还是使用Adam,β1= 0,β2= 0.99,学习率α始终是0.0008。
不同GAN的比较
我们先来看看PSGAN在多样性上的表现。如下图所示,PSGAN为每个姿势条件生成各种各样的图像。
接下来,我们再来看看PSGAN在生成姿态上的表现。在对照组中,PG2和DPG2需要同时输入源图像和相应的目标姿态才能生成目标图像,但PSGAN只需调整潜在变量就能使图像具备目标结构,它所受到限制更少。
下图对比了PG2、DPG2和PSGAN生成的姿态图,其中前两者所需的参考姿态图没有显示出来。通过对比我们可以发现,PSGAN生成的图像和PG2、DPG2一样自然合理,但又一定的瑕疵。由于这是通过调整潜在变量实现的,所以从理论上来说,如果变量调试得完美,PSGAN同样能生成具有相同的质量的姿态图。
最后,我们还评估了PSGAN与Progressive GAN在结构一致性上的表现。实验结果显示,无论是细节还是全局,PSGAN生成的图像都更自然,而且它在结构细节上的处理也更合理。
小结
本文展示了PSGAN在生成平滑、高分辨率动画上的水平,也通过实验证实它能基于512x512的目标姿势序列生成动画角色全身图和相应动画。由于实验条件有限,神经网络在一些方面还发挥欠佳,所以未来我们还会在更多条件下进行试验和评估。
此外,经处理的Avatar Anime-Character数据集即将开放。
-
投影机的最高分辨率的定义2009-11-17 0
-
高分辨率合成孔径雷达图像的直线特征多尺度提取方法2010-05-06 0
-
超高分辨率相机的设计,分辨率6千万,有没有做相机方面的大神们!2016-11-12 0
-
用高分辨率示波器测量微小信号2018-03-21 0
-
增强高分辨率图像捕获的选择2018-10-25 0
-
KAI-43140 CCD图像传感器提供高分辨率及图像均匀性2018-10-29 0
-
所谓“鹰眼”,即为高分辨率测量模式2019-01-25 0
-
高分辨率ADC解决实际难题2019-09-27 0
-
如何设计高速高分辨率ADC电路?2021-04-23 0
-
如何实现DCP的高分辨率控制?2021-04-27 0
-
如何实现连续脉冲信号的高分辨率延迟?2021-04-30 0
-
如何在基于机器视觉的应用中通过单线传输高分辨率视频数据2021-09-07 0
-
基于FPGA的高分辨率全景图像处理平台2015-11-04 577
-
基于多模型表示的高分辨率遥感图像配准方法_项盛文2017-03-19 938
-
一种基于参考高分辨率图像的视频序列超分辨率复原算法2017-10-26 906
全部0条评论

快来发表一下你的评论吧 !
