

捷豹路虎第一个使用820A做座舱域控制器
描述
2013年初,高通开始进军车载处理器市场,首款产品是2013年底的602A,在2014年初正式推出,不过推出后反应平平。车载系统开发周期远比手机开发周期长,芯片至少要考虑5年后的市场,高通在2016年初推出820A(两款芯片,一款为820A,不带Modem,另一款为820Am,带Modem),超前性能立刻获得好评。
捷豹路虎第一个使用820A做座舱域控制器,在2017年下半年就有路虎星脉和捷豹I-PACE两款量产车使用820A,随后大众、本田、吉利、PSA、比亚迪、玛莎拉蒂也纷纷采用820A做座舱域控制器。本田的10代雅阁美版也采用820A,已正式上市,国内则因为1.5T发动机机油增多问题,10代雅阁推迟上市。
上图为路虎揽胜星脉的座舱,采用4块屏幕,其中全液晶仪表为12.3英寸,Infotainment为10英寸,车载信息显示也为10英寸,屏上有两个硕大的铝合金旋钮,还有一块HUD使用的3.1英寸显示屏。可能由日本松下或哈曼打造。Infotainment屏幕在启动后会自动前倾,方便驾驶者观看。Infotainment屏下方的车载信息显示屏可以对车辆的空调、座椅和车辆设定进行控制,除了空调温度旋钮和音量旋钮,其余都用触控操作。仪表系统采用QNX,Infotainment用Linux+安卓界面。未来可能用Android Auto。
捷豹的第一款纯电动车I-Pace采用了类似星脉的设计,只是把车载信息显示屏换成了5.5英寸。这套系统中规中矩,唯一的出彩之处是激光HUD。捷豹路虎是第一个使用激光HUD的车厂,激光HUD显示对比度极高,色彩艳丽。
虽然不能算严格意义上的AR HUD,但是已经很不错了,能与ADAS和导航地图系统通信。
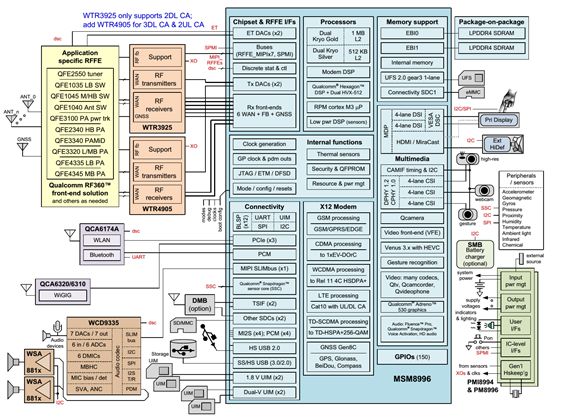
820A相比NXP的i.mx8或者瑞萨的R-CAR H3,亦或者德州仪器的Jacinto EX,优势有几点:
820A的绝大部分开发成本已经由手机厂家分摊完毕,有充足的降价空间
820本来就是针对移动设备的,低功耗不言而喻
CPU和GPU性能强大,同时也是特别为安卓系统设计的
820A最大优势,内含了4G Modem,无需再添加通讯模块
820A的劣势在于它最初不是针对车载市场的,不是按照ISO26262标准的开发流程得来的,安全等级连ASIL A级都达不到,只有AEC-Q100 3级。R-CAR H3是达到了ASIL B级,i.mx8暂时还未申请ASIL级别,但以NXP的能力,也能达到ASIL B级。当然可以通过添加其他元件让整体系统达到ISO 26262标准,但毕竟是个麻烦。
和奔驰MBUX相比,820Am做域控制器的座舱并未给人带来多少惊喜,820Am又多了一个强劲的对手,那就是英伟达的Parker。Parker一开始就是瞄准车载市场的,采用ASIL B级安全架构,内含锁步的R5内核,有内存纠正功能。Parker的另一优势是深度学习能力。820A的硬件也具备深度学习能力,但是高通的起步稍微晚了点,高通在2017年7月才发布了NPE的SDK。所以这方面应用还未看到,估计要等到下一代820座舱系统了。未来820域控制器可能接管部分ADAS功能,如360环视,车道线与行人识别,前撞报警,车道线偏离报警,不过应该只用于报警系统,不会用于主动执行系统,毕竟它没有考虑功能安全,用起来还是让人略微不放心。
此外深度学习这东西,没有太多理论依据,更多的像蛮力的搜索——非常深的层数,几千万甚至上亿参数,然后调整参数拟合输入与输出。这是一个不可解释的黑盒子,用在汽车以外的手机上没什么问题,但汽车领域要有充足的可解释性,这样才能评估安全风险。不过要想实现语义级的识别,深度学习几乎是最好的方法,尽管汽车行业不喜欢这种黑盒子,但还是不得不高度重视深度学习。
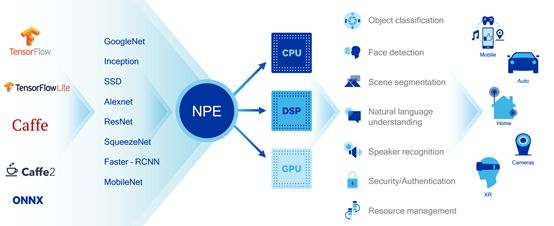
高通的NPE主要在Caffe2和Tensor Flow上运行,Caffe2主要是图形类,Tensor Flow还可以处理语音类。820内部采用异构架构,有三个运算单元,包括CPU、GPU、DSP分别针对不同类型的应用。

820内部的Hexagon 680 DSP内置了一个1024bit的SMID矢量数据寄存器,高通称之为Hexagon Vector Extensions—Hexagon矢量扩展,简写为HVX。HVX每次可以处理四条VLIW向量指令,每个循环可以处理多达4096bit数据,需要注意的是,一般实际应用中的指令比DSP支持的最大指令宽度要小很多,不过借助于SIMD和系统的特性,单个指令可以一次操作多个数据,因此在计算中很多数据可以被一次性填充进入处理过程,实现效能的最大化。
另外,HVX为了实现上下文切换功能,还设计了32个向量寄存器。规格方面,HVX支持32位的定点十进制数的操作,一般为INT8位,但不支持浮点计算,毕竟成本还是要考虑的。VX内部拥有L1数据和指令缓存,4个并行的VLIW标量处理单元,单元的运行频率为500MHz,还有共享的L2缓存。
此外,HVX中还有两组独立的矢量单元,这样设计实际上是为了执行多线程任务,比如同时处理音频和图像处理,矢量单元可以独立进行计算。ADAS中的视觉处理如360度环视,车道线识别,也就是量化的8比特数据交给DSP比较合适。DSP的能耗比差不多是最优秀的。非量化的32比特数据交给CPU或GPU处理。
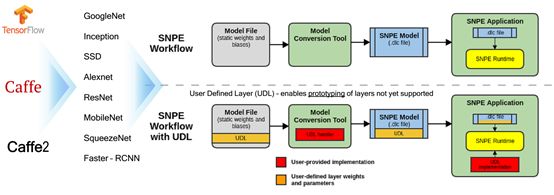
上图为NPE工作流程
座舱领域的深度学习可能会以语音识别或NLP自然语音处理为主要任务,并且是本地化离线与云端结合的NLP。离线NLP对目前高端CPU或者GPU来说处理能力问题不大,关键是存储语音库模型,消耗成本较高,存储器价格持续上涨令人头痛。再有可能就是知识产权的问题,离线的数据包有可能被人破解。
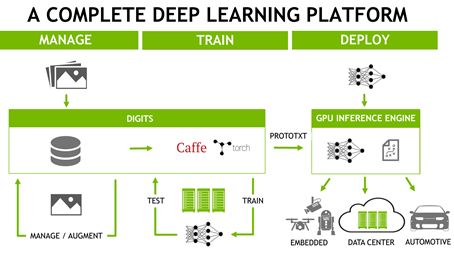
上图为完整的深度学习平台,可以说深度学习就是靠英伟达的GPU发展起来的,没有英伟达的GPU,深度学习不会走到今天这等地步,今天大部分深度学习的训练部分加速都是GPU完成的。而英伟达在一开始就布局长远,早在2007年推出CUDA的时候,就想到用CUDA建立了类似英特尔的生态圈。虽然官方发布的 CUDA Toolkit 并不总是最高效的实现,而是存在一定认知“黑洞”,一般用户无论如何优化CUDA C程序都无法逾越性能瓶颈。
而官方发布的库,从早期的CUBLAS,CUFFT到后来面向深度学习的CUDNN,都不是用CUDA C写的,而是NVIDIA内部的编译器完成的(这个是没有公开的版本),这样对NVIDIA好处显而易见,既能卖硬件,又能在软件上保持领先,增加用户粘度。从用户角度而言,使用高度封装的库可以降低开发、调试的门槛,直接调用C API就可以实现自己的算法,无需了解CUDA C的设计细节。即使是谷歌,也是选择CUDA而不是OpenCL作为TensorFlow的后端。
问题来了,高通的GPU自然不可能用CUDA,只能用OpenCL。CUDA则有强大的生态体系,尤其是深度学习训练领域,远比OpenCL易用。OpenCL虽然句法上与CUDA接近,但是它更加强调底层操作,因此难度较高,但正因为如此,OpenCL才能跨平台运行。基于C语言的CUDA被包装成一种容易编写的代码,因此即使是不熟悉芯片构造的科研人员,也可能利用CUDA工具编写出实用的程序,程序员更喜欢CUDA。
当然OpenCL与CUDA不是严格意义上的竞争关系,CUDA是一个并行计算的架构,包含有一个指令集架构和相应的硬件引擎。OpenCL是一个并行计算的应用程序编程接口(API)。CUDA C是一种高级语言,那些对硬件了解不多的非专业人士也能轻松上手;而OpenCL则是针对硬件的应用程序开发接口,它能给程序员更多对硬件的控制权,相应的上手及开发会比较难一些。所以用高通的GPU做深度学习,难度颇高,好在高通还有个DSP,虽然这个DSP只能做定点运算,但是还是有点用处的,比如语音处理时消除背景噪音。
英伟达的Parker在性能方面优势比较明显,在深度学习领域优势更明显,但是在功耗方面很可能不如高通820Am,虽然高通未给出准确的TDP数字,英伟达也未给出准确数值,有说7.5瓦,也有说最高21瓦。TDP这个指标已经有点过时了,很难准确评价芯片的功耗,但手机对功耗要求肯定比车载更加苛刻,尤其是高通810被人投诉发热严重,820肯定不会掉以轻心,车载的估计也适当降低CPU性能来降低功耗。
中美贸易争端的大背景下,高通收购NXP很有可能得不到批准。未来高通的820A,英伟达的Paker会对老牌厂家NXP的i.mx8 (i.mx8QM、 i.mx8QP要到2018年3季度才有量产样片,且还是28纳米的FD-SOI工艺),瑞萨的R-CAR H3、德州仪器的Jacinto 6 Plus构成强大的威胁。820A可能会挤占i.mx8的中端市场,Parker则可能会主打高端市场,挤压R-CAR H3的市场。
-
域控制器是下一代智能汽车架构的关键2019-06-27 0
-
域控制器的5个角色主机类型与作用2019-07-15 0
-
重置域控制器管理员密码的几个步骤分析2019-07-15 0
-
【HarmonyOS HiSpark AI Camera】域控制器预言开发2020-11-23 0
-
车身域控制器的原理是什么呢2022-02-14 0
-
介绍汽车区域控制器的一些关键技术和MCU解决方案2022-10-26 0
-
伟世通下一代SmartCore™座舱域控制器将采用高通汽车级计算解决方案2018-01-17 9830
-
伟世通为吉利提供SmartCore集成座舱域控制器用于吉利的新电动车平台2018-05-30 1864
-
华阳通用携手BlackBerry开发智能座舱域控制器2022-01-21 2000
-
航盛电子座舱域控制器获奖 国内首颗商业组网SAR遥感卫星发射成功2022-03-10 1964
-
智能座舱域控制器功能自动化测试方案2022-08-01 1480
-
航盛电子荣膺高工“2023年度智能汽车座舱域控制器TOP10供应商”2023-09-12 1326
-
智驾、座舱、泊车三合一域控制器解析2024-01-29 542
-
座舱域控制器硬件架构方案:SoC + MCU2024-02-01 3793
全部0条评论

快来发表一下你的评论吧 !
