

如何写一个简短(200行)的Python脚本
描述
简介
在这篇文章中我将介绍如何写一个简短(200行)的 Python 脚本,来自动地将一幅图片的脸替换为另一幅图片的脸。
这个过程分四步:
检测脸部标记。
旋转、缩放、平移和第二张图片,以配合第一步。
调整第二张图片的色彩平衡,以适配第一张图片。
把第二张图像的特性混合在第一张图像中。
公众号后台回复:“换脸”,获取程序完整代码。
1.使用 dlib 提取面部标记
该脚本使用 dlib 的 Python 绑定来提取面部标记:
Dlib 实现了 Vahid Kazemi 和 Josephine Sullivan 的《使用回归树一毫秒脸部对准》论文中的算法。算法本身非常复杂,但dlib接口使用起来非常简单:
PREDICTOR_PATH ="/home/matt/dlib-18.16/shape_predictor_68_face_landmarks.
dat"detector = dlib.get_frontal_face_detector()predictor = dlib.
shape_predictor(PREDICTOR_PATH)defget_landmarks(im):
rects = detector(im,1) iflen(rects) >1:
raiseTooManyFaces iflen(rects) ==0:
raiseNoFaces returnnumpy.matrix([[p.x, p.
y]forpinpredictor(im, rects[0]).parts()])
get_landmarks()函数将一个图像转化成numpy数组,并返回一个68×2元素矩阵,输入图像的每个特征点对应每行的一个x,y坐标。
特征提取器(predictor)需要一个粗糙的边界框作为算法输入,由一个传统的能返回一个矩形列表的人脸检测器(detector)提供,其每个矩形列表在图像中对应一个脸。
2.用 Procrustes 分析调整脸部
现在我们已经有了两个标记矩阵,每行有一组坐标对应一个特定的面部特征(如第30行的坐标对应于鼻头)。我们现在要解决如何旋转、翻译和缩放第一个向量,使它们尽可能适配第二个向量的点。一个想法是可以用相同的变换在第一个图像上覆盖第二个图像。
将这个问题数学化,寻找T,s 和 R,使得下面这个表达式:
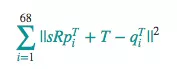
结果最小,其中R是个2×2正交矩阵,s是标量,T是二维向量,pi和qi是上面标记矩阵的行。
事实证明,这类问题可以用“常规 Procrustes 分析法”解决:
deftransformation_from_points(points1, points2):
points1 = points1.astype(numpy.float64)
points2 = points2.astype(numpy.float64)
c1 = numpy.mean(points1, axis=0)
c2 = numpy.mean(points2, axis=0)
points1 -= c1
points2 -= c2
s1 = numpy.std(points1)
s2 = numpy.std(points2)
points1 /= s1
points2 /= s2
U, S, Vt = numpy.linalg.svd(points1.T *
points2)
R = (U * Vt).T
returnnumpy.vstack([numpy.hstack(((s2 / s1) * R,
c2.T - (s2 / s1) * R * c1.T)),
numpy.matrix([0.,0.,1.])])
代码实现了这几步:
1.将输入矩阵转换为浮点数。这是后续操作的基础。
2.每一个点集减去它的矩心。一旦为点集找到了一个最佳的缩放和旋转方法,这两个矩心 c1 和 c2 就可以用来找到完整的解决方案。
3.同样,每一个点集除以它的标准偏差。这会消除组件缩放偏差的问题。
4.使用奇异值分解计算旋转部分。可以在维基百科上看到关于解决正交 Procrustes 问题的细节。
5.利用仿射变换矩阵返回完整的转化。
其结果可以插入 OpenCV 的 cv2.warpAffine 函数,将图像二映射到图像一:
def warp_im(im, M, dshape):
output_im = numpy.zeros(dshape, dtype=im.dtype) cv2.warpAffine(im,
M[:2],
(dshape[1], dshape[0]),
dst=output_im,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP) returnoutput_im
对齐结果如下:
3.校正第二张图像的颜色
如果我们试图直接覆盖面部特征,很快会看到这个问题:
这个问题是两幅图像之间不同的肤色和光线造成了覆盖区域的边缘不连续。我们试着修正:
COLOUR_CORRECT_BLUR_FRAC =0.6LEFT_EYE_POINTS = list(range(42,48))RIGHT_EYE_POINTS = list(range(36,42))def correct_colours(im1, im2, landmarks1):
blur_amount = COLOUR_CORRECT_BLUR_FRAC * numpy.linalg.norm(
numpy.mean(landmarks1[LEFT_EYE_POINTS], axis=0) -
numpy.mean(landmarks1[RIGHT_EYE_POINTS], axis=0))
blur_amount =int(blur_amount) ifblur_amount %2==0:
blur_amount +=1 im1_blur = cv2.GaussianBlur(im1, (blur_amount, blur_amount),0)
im2_blur = cv2.GaussianBlur(im2, (blur_amount, blur_amount),0)
# Avoid divide-by-zero errors. im2_blur +=128* (im2_blur <=1.0)
return(im2.astype(numpy.float64) * im1_blur.astype(numpy.float64)
/
im2_blur.astype(numpy.float64))
结果如下:
此函数试图改变 im2 的颜色来适配 im1。它通过用 im2 除以 im2 的高斯模糊值,然后乘以im1的高斯模糊值。这里的想法是用RGB缩放校色,但并不是用所有图像的整体常数比例因子,每个像素都有自己的局部比例因子。
用这种方法两图像之间光线的差异只能在某种程度上被修正。例如,如果图像1是从一侧照亮,但图像2是被均匀照亮的,色彩校正后图像2也会出现未照亮一侧暗一些的问题。
也就是说,这是一个相当简陋的办法,而且解决问题的关键是一个适当的高斯核函数大小。如果太小,第一个图像的面部特征将显示在第二个图像中。过大,内核之外区域像素被覆盖,并发生变色。这里的内核用了一个0.6 *的瞳孔距离。
4.把第二张图像的特征混合在第一张图像中
用一个遮罩来选择图像2和图像1的哪些部分应该是最终显示的图像:
值为1(显示为白色)的地方为图像2应该显示出的区域,值为0(显示为黑色)的地方为图像1应该显示出的区域。值在0和1之间为图像1和图像2的混合区域。
这是生成上图的代码:
LEFT_EYE_POINTS = list(range(42,48))RIGHT_EYE_POINTS = list(range(36,42))
LEFT_BROW_POINTS = list(range(22,27))RIGHT_BROW_POINTS = list(range(17,22))
NOSE_POINTS = list(range(27,35))MOUTH_POINTS = list(range(48,61))
OVERLAY_POINTS = [ LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS,
NOSE_POINTS + MOUTH_POINTS,]FEATHER_AMOUNT =11def draw_convex_hull(im, points, color):
points = cv2.convexHull(points)
cv2.fillConvexPoly(im, points, color=color)def get_face_mask(im, landmarks):
im = numpy.zeros(im.shape[:2], dtype=numpy.float64)
forgroup in OVERLAY_POINTS:
draw_convex_hull(im,
landmarks[group],
color=1) im = numpy.array([im, im, im]).transpose((1,2,0))
im = (cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT),0) >0) *1.0
im = cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT),0)
returnimmask = get_face_mask(im2, landmarks2)warped_mask = warp_im(mask, M,
im1.shape)combined_mask = numpy.max([get_face_mask(im1, landmarks1),
warped_mask],
axis=0)
我们把上述过程分解:
get_face_mask()的定义是为一张图像和一个标记矩阵生成一个遮罩,它画出了两个白色的凸多边形:一个是眼睛周围的区域,一个是鼻子和嘴部周围的区域。之后它由11个像素向遮罩的边缘外部羽化扩展,可以帮助隐藏任何不连续的区域。
这样一个遮罩同时为这两个图像生成,使用与步骤2中相同的转换,可以使图像2的遮罩转化为图像1的坐标空间。
之后,通过一个element-wise最大值,这两个遮罩结合成一个。结合这两个遮罩是为了确保图像1被掩盖,而显现出图像2的特性。
最后,使用遮罩得到最终的图像:
output_im= im1 * (1.0- combined_mask) + warped_corrected_im2 * combined_mask
完整代码(link):
import cv2import dlibimport numpyimport sysPREDICTOR_PATH ="/home/matt/dlib-18.16/shape_predictor_68_face_landmarks.
dat"SCALE_FACTOR =1FEATHER_AMOUNT =11FACE_POINTS =list(range(17,68))MOUTH_POINTS =list(range(48,61))
RIGHT_BROW_POINTS =list(range(17,22))LEFT_BROW_POINTS =list(range(22,27))
RIGHT_EYE_POINTS =list(range(36,42))LEFT_EYE_POINTS =list(range(42,48))NOSE_POINTS =list(range(27,35))JAW_POINTS =list(range(0,17))#
Points usedtolineupthe images.ALIGN_POINTS = (LEFT_BROW_POINTS + RIGHT_EYE_POINTS + LEFT_EYE_POINTS +
RIGHT_BROW_POINTS + NOSE_POINTS + MOUTH_POINTS)#
Points from the second imagetooverlayonthefirst.
The convex hull of each# element willbeoverlaid.
OVERLAY_POINTS = [ LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS, NOSE_POINTS + MOUTH_POINTS,]
# Amount of blurtouse during colour correction,asafraction of the#
pupillary distance.COLOUR_CORRECT_BLUR_FRAC =0.6detector = dlib.get_frontal_face_detector()predictor = dlib.
shape_predictor(PREDICTOR_PATH)class TooManyFaces(Exception):
passclass NoFaces(Exception):
passdef get_landmarks(im):
rects = detector(im,1) iflen(rects) >1:
raise TooManyFaces iflen(rects) ==0:
raise NoFaces returnnumpy.matrix([[p.x,p.y]forpin predictor(im, rects[0]).
parts()])def annotate_landmarks(im, landmarks): im=im.copy() foridx, point in enumerate(landmarks):
pos = (point[0,0], point[0,1])
cv2.putText(im, str(idx), pos,
fontFace=cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,
fontScale=0.4,
color=(0,0,255))
cv2.circle(im, pos,3, color=(0,255,255)) returnimdef draw_convex_hull(im, points, color):
points = cv2.convexHull(points) cv2.fillConvexPoly(im, points, color=color)def get_face_mask(im, landmarks): im= numpy.zeros(im.shape[:2], dtype=numpy.float64) forgroup in OVERLAY_POINTS:
draw_convex_hull(im,
landmarks[group],
color=1) im= numpy.array([im,im,im]).transpose((1,2,0))
im= (cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT),0) >0) *1.0 im= cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT),0) returnimdef transformation_from_points(points1, points2):
""" Returnanaffine transformation [s * R | T] such that:
sum ||s*R*p1,i + T - p2,i||^2 isminimized. """
# Solve the procrustes problem by subtracting centroids, scaling by the
# standard deviation,andthen using the SVDtocalculate the rotation. See
# the followingformore details:
# https://en.wikipedia.org/wiki/Orthogonal_Procrustes_problem
points1 = points1.astype(numpy.float64)
points2 = points2.astype(numpy.float64)
c1 = numpy.mean(points1, axis=0)
c2 = numpy.mean(points2, axis=0)
points1 -= c1
points2 -= c2
s1 = numpy.std(points1)
s2 = numpy.std(points2)
points1 /= s1
points2 /= s2
U, S, Vt = numpy.linalg.svd(points1.T * points2)
# The R we seekisin fact the transpose of the one given by U * Vt.
This
#isbecause the above formulation assumes the matrix goesontheright
# (with row vectors) whereasour solution requires the matrixtobeonthe
#left(with column vectors).
R = (U * Vt).T returnnumpy.vstack([numpy.hstack(((s2 / s1) * R,
c2.T - (s2 / s1) * R * c1.T)),
numpy.matrix([0.,0.,1.])])def read_im_and_landmarks(fname):
im= cv2.imread(fname, cv2.IMREAD_COLOR) im= cv2.resize(im, (im.shape[1] * SCALE_FACTOR,
im.shape[0] * SCALE_FACTOR))
s = get_landmarks(im) returnim, sdef warp_im(im, M, dshape): output_im = numpy.zeros(dshape, dtype=im.dtype)
cv2.warpAffine(im,
M[:2],
(dshape[1], dshape[0]),
dst=output_im,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP) returnoutput_imdef correct_colours(im1, im2, landmarks1):
blur_amount = COLOUR_CORRECT_BLUR_FRAC * numpy.linalg.norm(
numpy.mean(landmarks1[LEFT_EYE_POINTS], axis=0) -
numpy.mean(landmarks1[RIGHT_EYE_POINTS], axis=0))
blur_amount =int(blur_amount) ifblur_amount %2==0:
blur_amount +=1 im1_blur = cv2.GaussianBlur(im1, (blur_amount, blur_amount),0) im2_blur = cv2.GaussianBlur(im2, (blur_amount, blur_amount),0)
# Avoid divide-by-zero errors.
im2_blur +=128* (im2_blur <=1.0) return(im2.astype(numpy.float64) * im1_blur.astype(numpy.float64) /
im2_blur.astype(numpy.float64))im1, landmarks1 = read_im_and_landmarks(sys.argv[1])
im2, landmarks2 = read_im_and_landmarks(sys.argv[2])M = transformation_from_points(landmarks1[ALIGN_POINTS],
landmarks2[ALIGN_POINTS])mask = get_face_mask(im2, landmarks2)warped_mask = warp_im(mask, M, im1.shape)combined_mask = numpy.max([get_face_mask(im1, landmarks1), warped_mask],
axis=0)warped_im2 = warp_im(im2, M, im1.shape)warped_corrected_im2 = correct_colours(im1, warped_im2, landmarks1)output_im = im1 *
(1.0- combined_mask) + warped_corrected_im2 *
combined_maskcv2.imwrite('output.jpg', output_im)
-
python写一个建模的脚本-微带天线的模型建立与仿真的过程搞定了2021-02-19 0
-
ubuntu linux操作系统上如何写一个让图随机移动的程序,打.....2014-04-18 0
-
如何写一个Qt版本的Helloworld程序?2014-05-05 0
-
树莓派 python SimpleCV crontab 拍照2016-10-07 0
-
请问Labview如何写一个心形动态曲线图?2020-05-18 0
-
如何在Python中使用Selenium2020-09-08 0
-
如何写一个简易的printf函数?2021-04-28 0
-
如何写一个中断函数2021-11-29 0
-
如何写一个简单的字符设备驱动程序?2021-12-23 0
-
【ELF 1开发板试用】+ python及脚本编程2023-11-28 0
-
如何在 IIS 中执行 Python 脚本2010-02-23 1131
-
如何写一个简短的Python脚本做一个换脸程序2018-03-29 5046
-
如何写一个简短的Python代码做一个换脸程序的详细概述2018-07-09 4234
-
如何使html网页与python脚本进行通信2019-11-04 7604
-
基于Python脚本的R语言的函数2020-10-12 1855
全部0条评论

快来发表一下你的评论吧 !
