

谷歌如何利用深度学习来实现智能邮件助手
电子说
描述
谷歌在不久前的I/O大会上推出了辅助人们高效撰写邮件的智能写作助手。在深度神经网络的帮助下,它可以根据用户很少的输入信息就推断出接下来想要写入文本,就如知心好友一般默契无间了!我们先来感受一下在它的帮助下写邮件多么畅快:
智能写作是基于一年前谷歌发布的智能回复功能进一步研发而成的。先前的智能回复功能通过分析邮件内容来帮助用户快速撰写回复邮件使用户在移动端处理邮件的效率有了大幅的提升。
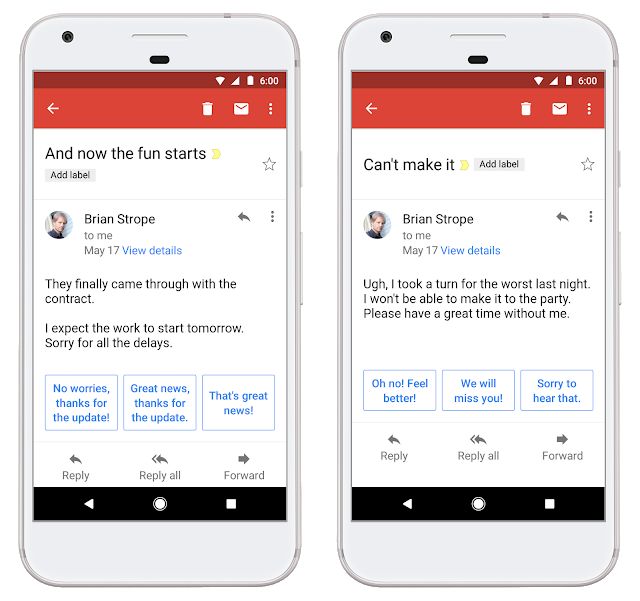
它基于人类语言中的层级结构,从字母到单词、从短语到句子、从段落到章节和整篇完整表达的内容。研究人员们训练出了了一系列层级模块用于学习、记忆和识别一种特定的模式。在足够多样本的训练下层级模型取得了比LSTM更好的效果,并具有了一定的语音表达能力。下图中蓝色字体就是模型分析邮件后为用户生成出备选的恢复内容。
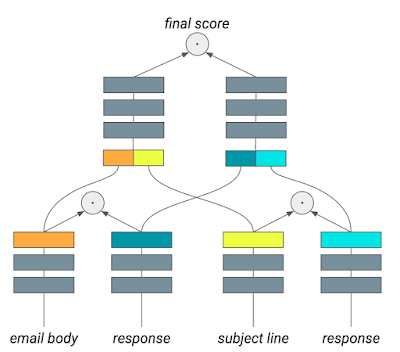
但从智能回复到智能写作助手的研发过程中,除了迅速响应大规模用户的需求、还需要兼顾公平和用户的隐私。
首先在用户撰写邮件时,为了不使用户感受到明显的延迟,其响应需要在100ms以内,这要求在模型的效率和复杂度上做有效的权衡;目前Gmail拥有14亿以上的用户,所以模型需要有足够的容量满足各种不同用户的个性化需求;除了速度和规模外,还需要防止这一功能由于训练数据产生偏见,并且也要符合严格的隐私规定,防止用户的隐私信息泄露。由于研究人员不可以进入email中,所以所有的机器学习系统都是运行在他们不可读的数据集上的。
寻找合适的模型
典型的语言生成模型包括N-Gram、神经词袋和循环神经网络语言模型,它们通过先前词汇预测后续词汇或者句子。然而在邮件中,模型只有当前邮件对话这一单一的信号来预测后续的词汇。为了更好的理解用户想要表达的内容,模型同时还会分析邮件标题和之前邮件的内容。
这种需要叠加上下文的文本分析会带来一个seq2seq机器翻译同样的问题,其中源序列是主题和先前邮件内容的组合、目标序列则是目前用户正在撰写的邮件。它虽然在但是却无法满足严格的时间要求。为了改进这一点,研究人员们将词袋模型和循环神经网络语言模型结合起来,实现了比seq2seq更快的的速度,但只在预测质量上做出了轻微的牺牲。
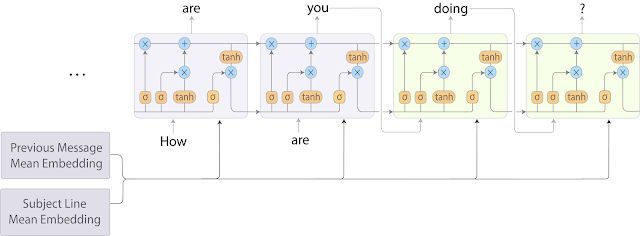
如上图所示,在这一混合模型中标题和先前的邮件先用词向量平均处理,而后将他们输入到接下来的循环神经网络中去解码。
加速模型训练和服务
为了加速模型的训练和调参,研究人员们使用了自家的大杀器TPU,只需要不到一年就能在几十亿的样本上实现收敛。
虽然训练速度提高了,但在实际使用时候的速度才是用户最为关心的指标。通过将CPU的计算请求分配到TPU上得到了迅速的推理结果,同时由于CPU的算力得到了释放,使得单机可以提供服务的用户数量大幅增加。
公平性和隐私
对于机器学习来说,公平性和隐私是至关重要的问题。语言模型可以折射出人类的认知偏见,这样会生成一系列不希望的句子补全。这些偏见和联系主要来自于语言数据,这对于构建一个无偏模式是巨大的挑战。于是研究人员们通过各种方式不断减弱训练过程中潜在的偏见。同时智能写作助手是构建于数十一个样本上的训练结果,只有同时被多个用户确认的通用结果才会被模型记住。
语言模型中一种常见的性别偏见
在未来这一模型会被持续改进,并尝试着加入一些先进的模型架构(例如transformer和RNMT+等)和先进的训练技术,同时在生产中部署更多的先进模型来满足实时性和要求。个人语言模型会在随后加入以更精确的满足个人的写作风格和表达习惯。
-
基于深度学习技术的智能机器人2018-05-31 0
-
谷歌智能音箱新增连续对话功能2018-06-23 0
-
谷歌深度学习插件tensorflow2018-07-04 0
-
深度学习在汽车中的应用2019-03-13 0
-
如何实现嵌入式平台与深度学习的智能气象监测仪器的设计2021-11-09 0
-
深度学习介绍2022-11-11 0
-
利用DAQ助手实现数据采集2016-01-14 911
-
谷歌加码人工智能 新设一家实验室意在深度学习_人工智能,生物识别,深度学习2016-11-23 411
-
谷歌利用深度学习将眼睛视为个人健康的“指示器”2018-01-09 3327
-
谷歌FHIR标准协议利用深度学习预测医疗事件发生2018-03-07 7852
-
谷歌疯狂速度推进AI革命,让人们在深度学习系统中实现民主化2018-05-11 666
-
当机器翻译遇见深度学习2018-05-18 2593
-
人工智能软件谷歌助手亮相,意味着人工智能进一步升级2018-08-10 416
-
使用谷歌助手实现家庭自动化2022-12-14 245
-
智能工厂如何实现深度学习自动化?2022-12-28 603
全部0条评论

快来发表一下你的评论吧 !
