

Flow Control机制可以显著地提高总线的传输效率
电子说
描述
Flow ControlFlow Control即流量控制,这一概念起源于网络通信中。PCIe总线采用Flow Control的目的是,保证发送端的PCIe设备永远不会发送接收端的PCIe设备不能接收的TLP(事务层包)。也就是说,发送端在发送前可以通过Flow Control机制知道接收端能否接收即将发送的TLP。
在PCI总线中,并没有Flow Control这样的机制,因此发送端并不知道当前时刻,接收端能够接收对应的TLP。因此,发送端只能先尝试发送,期间可能会被插入多个等待周期(接收设备尚未就绪等原因),甚至是重发(Retries)等。
PCIe Spec规定,PCIe设备的每一个端口(Ports)都必须支持Flow Control机制,在发送TLP之前,Flow Control必须先检查接收端口是否有足够的Buffer空间来接收这个TLP。当PCIe设备支持多个VC(Virtual Channel)时,Flow Control机制可以显著地提高总线的传输效率。
PCIe Spec规定,每个PCIe设备最多支持8个VC,并且每个VC的Flow Control Buffer是完全独立的。也就是说,某一个VC的Flow Control Buffer满了,并不会影响其他的VC的通信。
前面的文章中介绍过,Flow Control机制是通过相邻两个端口(Ports)的数据链路层之间发送DLLP(Flow Control DLLPs)来实现的。在进行初始化的时候,接收端需要向发送端报告(reports)其Buffer的大小,在正常运行状态(Run-time)时,会周期性地通过Flow Control DLLPs来告知发送端,接收端的各个Buffer的大小。
需要注意的是,虽然Flow Control DLLP只在相邻的数据链路层之间传输,但是相关的Buffer和计数器(FC Counter)确实存在于事务层(Transaction Layer)的。如下图所示:
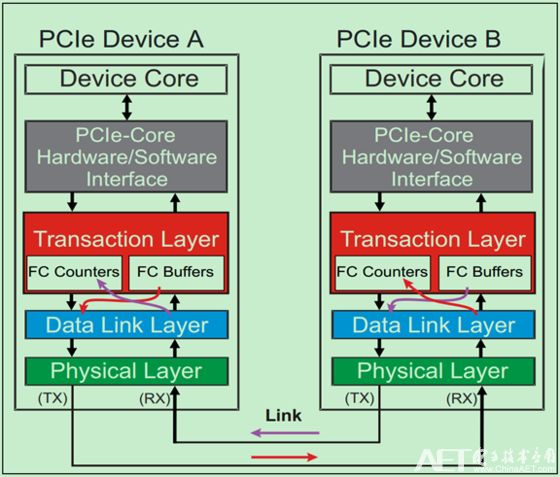
前面的文章中多次介绍过,TLP一共有三大类:
Posted Transactions(包括Memory Writes和Messages)、Non-Posted Transactions(包括Memory Reads、Configuration Reads and Writes、IO Reads and Writes)以及Completions(包括Read and Write Completion)。并且知道,TLP可以分为两个部分,Header和Data部分。Flow Control为了获得更高的数据传输效率,将这三类TLP分开存放,同时将Header与Data部分也分开存放。因此,一共存在六种不同的Flow Control Buffer类型,如下图所示:
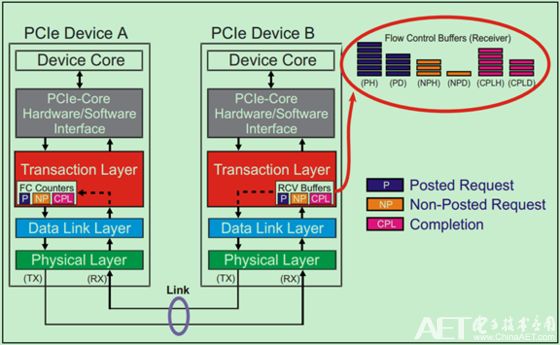
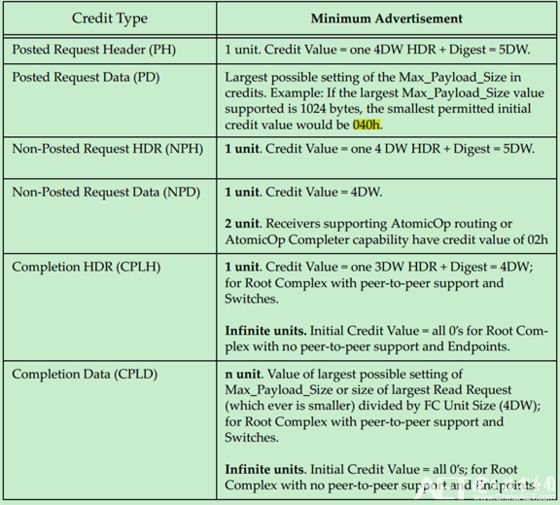
Flow Control Buffer的存储单元(Unit)被称作Flow Control Credits。对于Header来说,Requests TLP每个unit等于5DW,而Completions TLP每个unit等于4DW。对于Data来说,每个unit等于4DW,即Data Buffer是按照16个字节对齐的。对于各种类型的Buffer的最小值如下表所示:
最大值如下表所示:
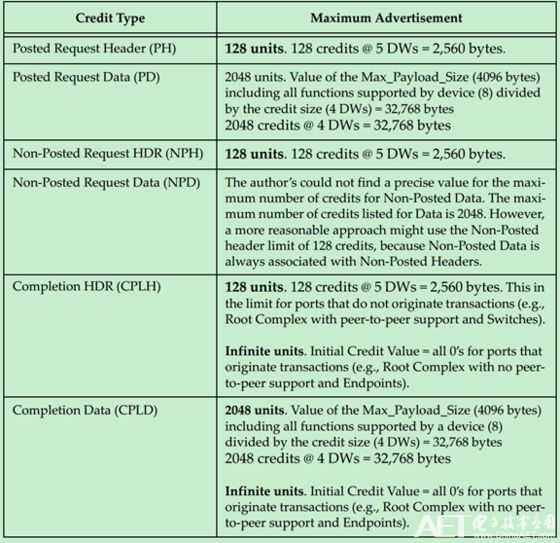
注:0 unit表示无限(Infinite)。
-
提高系统效率的几个误解解析2024-01-15 0
-
软件仿真为什么可以提高PCB的设计效率?2021-04-23 0
-
1553b总线的特点和消息传输机制,有什么应用?2021-06-03 0
-
关于AHB总线 Master的回复机制解析2022-06-08 0
-
STM32总线CPU和DMA可以同时工作吗?有仲裁机制吗?2022-12-27 0
-
采用Flow Control机制的PCIe总线2018-04-26 5428
-
PCIe总线必须要先完成Flow Control初始化2018-05-24 7561
-
区块链机制设计,可以解决可信性以及效率问题2018-09-12 1643
-
一种高效率PLB2AXI总线桥设计方案2021-03-30 500
-
CET为何而生?CET安全防御机制解析2022-11-25 939
-
W-CDMA电源显著提高传输效率2023-03-09 565
-
扒一扒PCIe中的Flow Control2023-07-03 1283
-
高性能整流器显著提高服务器供电效率2023-07-26 127
-
雷达传感器如何显著提高智能家居的能源效率2023-12-06 228
-
can总线传输距离2023-12-07 1606
全部0条评论

快来发表一下你的评论吧 !
