

机器学习中五种常用的聚类算法
电子说
描述
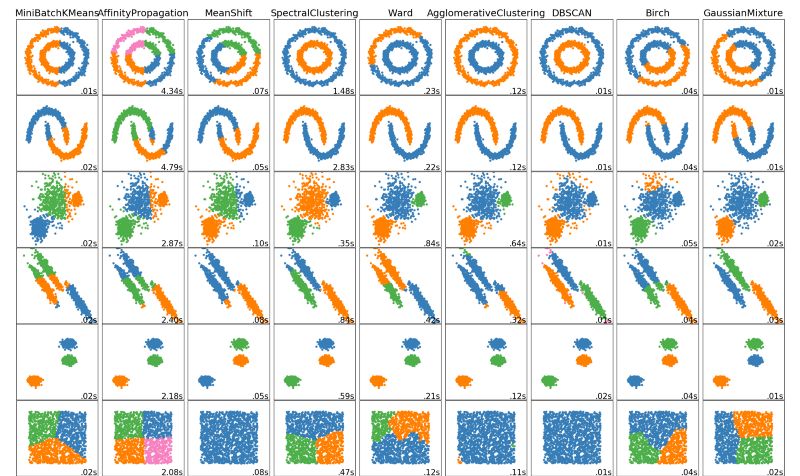
聚类是机器学习中一种重要的无监督算法,它可以将数据点归结为一系列特定的组合。理论上归为一类的数据点具有相同的特性,而不同类别的数据点则具有各不相同的属性。在数据科学中聚类会从数据中发掘出很多分析和理解的视角,让我们更深入的把握数据资源的价值、并据此指导生产生活。以下是五种常用的聚类算法。
K均值聚类
这一最著名的聚类算法主要基于数据点之间的均值和与聚类中心的聚类迭代而成。它主要的优点是十分的高效,由于只需要计算数据点与剧类中心的距离,其计算复杂度只有O(n)。其工作原理主要分为以下四步:
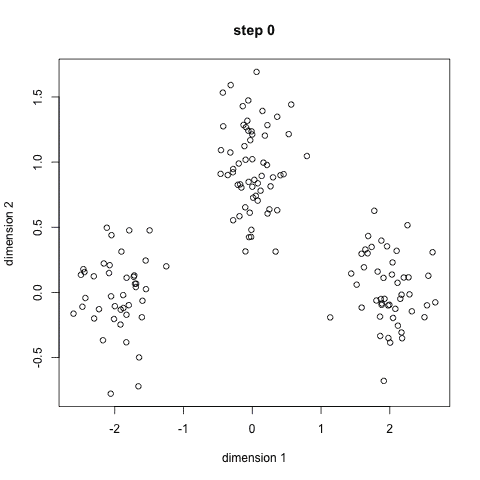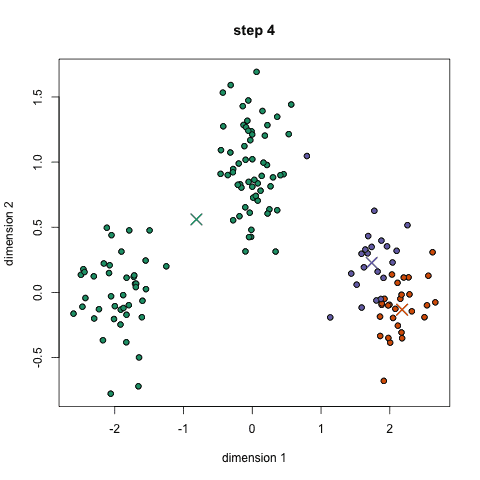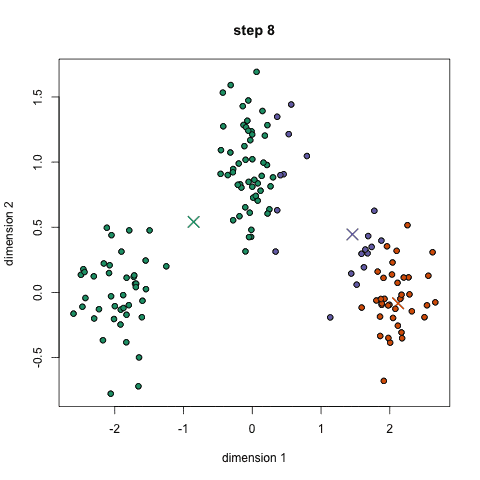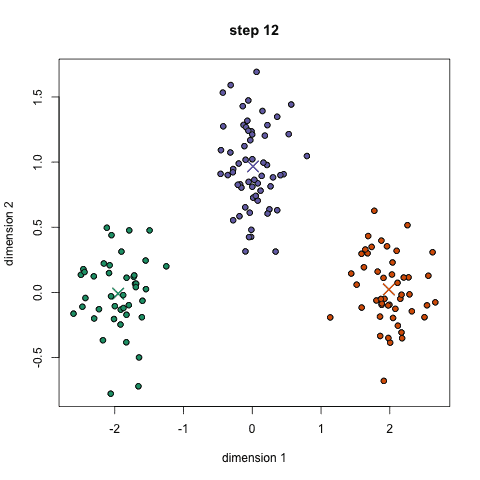
1.首先我们需要预先给定聚类的数目同时随机初始化聚类中心。我们可以初略的观察数据并给出较为准确的聚类数目;
2.每一个数据点通过计算与聚类中心的距离了来分类到最邻近的一类中;
3.根据分类结果,利用分类后的数据点重新计算聚类中心;
4.重复步骤二三直到聚类中心不再变化。(可以随机初始化不同的聚类中心以选取最好的结果)
这种方法在理解和实现上都十分简单,但缺点却也十分明显,十分依赖于初始给定的聚类数目;同时随机初始化可能会生成不同的聚类效果,所以它缺乏重复性和连续性。
和K均值类似的K中值算法,在计算过程中利用中值来计算聚类中心,使得局外点对它的影响大大减弱;但每一次循环计算中值矢量带来了计算速度的大大下降。
均值漂移算法
这是一种基于滑动窗口的均值算法,用于寻找数据点中密度最大的区域。其目标是找出每一个类的中心点,并通过计算滑窗内点的均值更新滑窗的中心点。最终消除临近重复值的影响并形成中心点,找到其对应的类别。
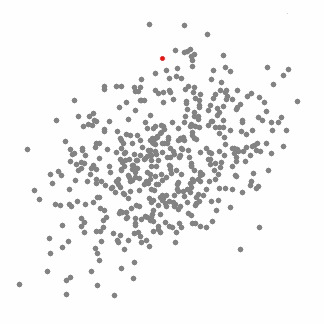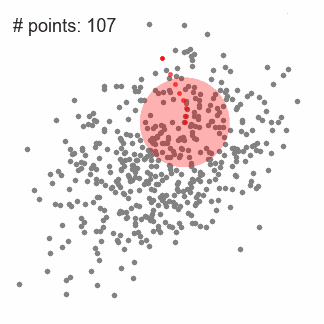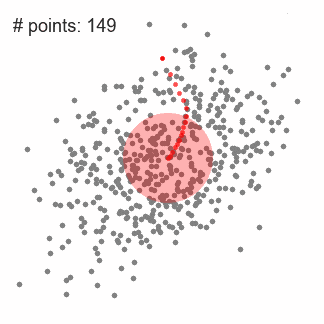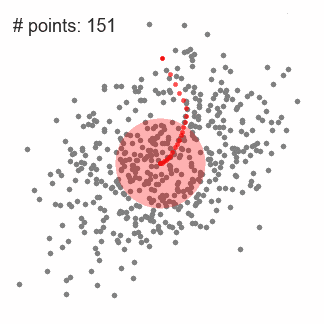
1.首先以随机选取的点为圆心r为半径做一个圆形的滑窗。其目标是找出数据点中密度最高点并作为中心;
2.在每个迭代后滑动窗口的中心将为想着较高密度的方向移动;
3.连续移动,直到任何方向的移动都不能增加滑窗中点的数量,此时滑窗收敛;
4.将上述步骤在多个滑窗上进行以覆盖所有的点。当过个滑窗收敛重叠时,其经过的点将会通过其滑窗聚类为一个类;
下图中每一个黑点都代表一个滑窗的中心,他们最终重叠在每一类的中心;

与K均值相比最大的优点是我们无需指定指定聚类数目,聚类中心处于最高密度处也是符合直觉认知的结果。但其最大的缺点在于滑窗大小r的选取,对于结果有着很大的影响。
基于密度的聚类算法(DBSCAN)
DBSCAN同样是基于密度的聚类算法,但其原理却与均值漂移大不相同:
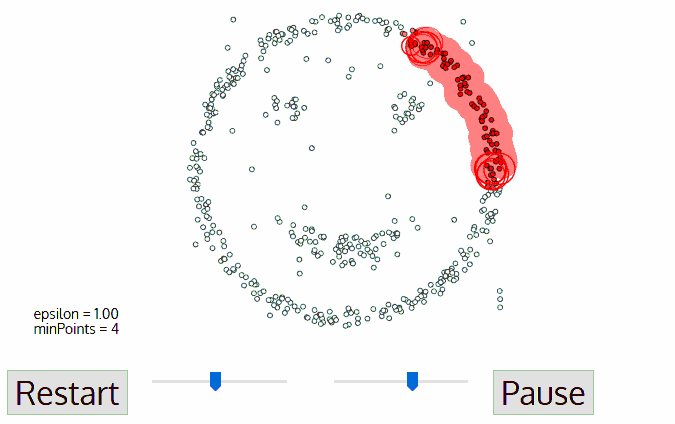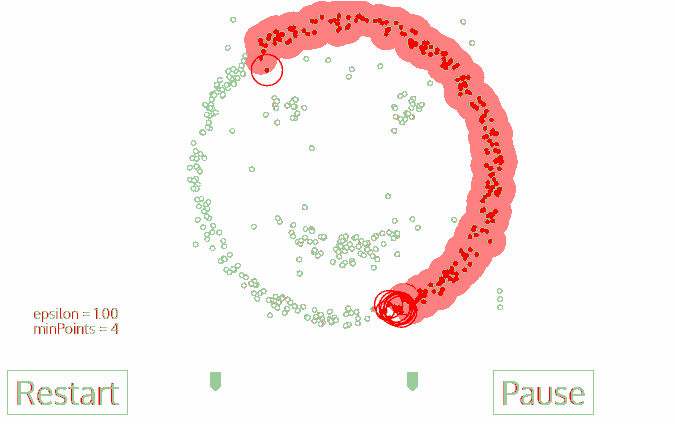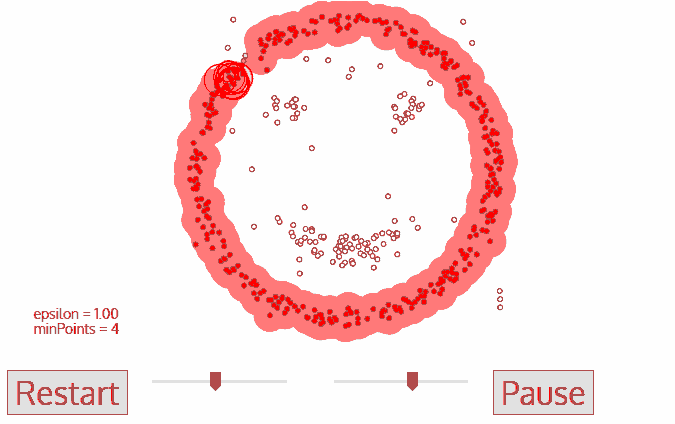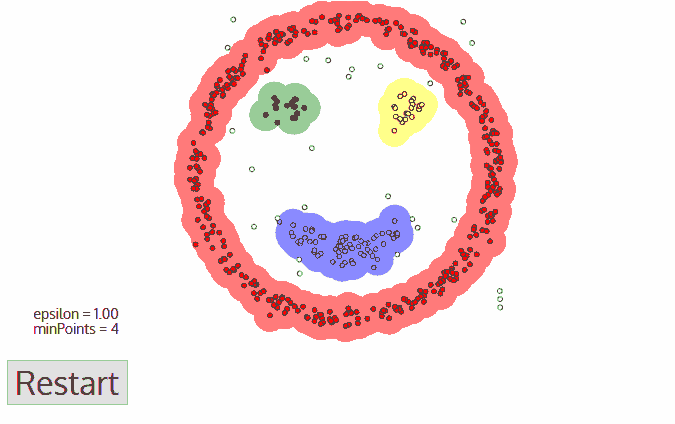
1.首先从没有被遍历的任一点开始,利用邻域距离epsilon来获取周围点;
2.如果邻域内点的数量满足阈值则此点成为核心点并以此开始新一类的聚类。(如果不是则标记为噪声);
3.其邻域内的所有点也属于同一类,将所有的邻域内点以epsilon为半径进行步骤二的计算;
4.重复步骤二、三直到变量完所有核心点的邻域点;
5.此类聚类完成,同时又以任意未遍历点开始步骤一到四直到所有数据点都被处理;最终每个数据点都有自己的归属类别或者属于噪声。
这种方法最大的优点在于无需定义类的数量,其次可以识别出局外点和噪声点、并且可以对任意形状的数据进行聚类。
但也存在不可回避的缺点,当数据密度变化剧烈时,不同类别的密度阈值点和领域半径会产生很大的变化。同时在高维空间中准确估计领域半径也是不小的挑战。
利用高斯混合模型进行最大期望估计
对于较为复杂的分布K均值将会产生如下图般较为离谱的聚类结果。

而高斯混合模型却具有更高的灵活性。通过假设数据点符合均值和标准差描述的高斯混合模型来实现的。下图以二维情况下为例描述了如何利用最大期望优化算法来获取分布参数的过程:
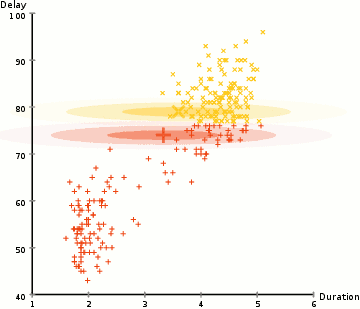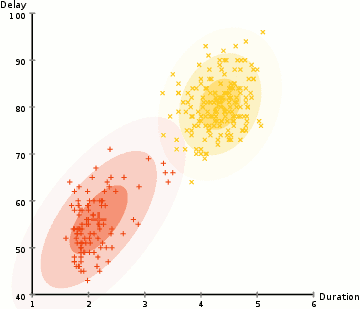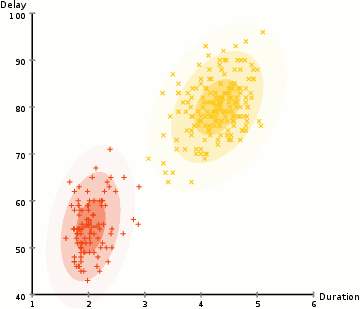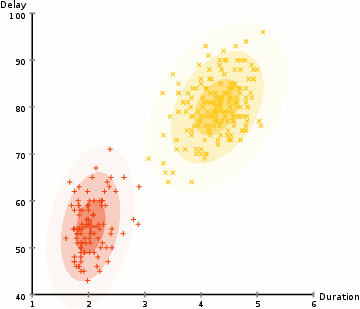
1.首先确定聚类的数量,并随机初始化每一个聚类的高斯分布参数;
2.通过计算每一个点属于高斯分布的概率来进行聚类。与高斯中心越近的点越有可能属于这个类;
3.基于上一步数据点的概率权重,通过最大似然估计的方法计算出每一类数据点最有可能属于这一聚类的高斯参数;
4.基于新的高斯参数,重新估计每一点归属各类的概率,重复并充分2,3步骤直到参数不再变化收敛为止。
在使用高斯混合模型时有两个关键的地方,首先高斯混合模型十分灵活,可以拟合任意形状的椭圆;其次这是一种基于概率的算法,每个点可以拥有属于多类的概率,支持混合属性。
凝聚层次聚类
层次聚类法主要有自顶向下和自底向上两种方式。其中自底向上的方式,最初将每个点看做是独立的类别,随后通过一步步的凝聚最后形成独立的一大类,并包含所有的数据点。这会形成一个树形结构,并在这一过程中形成聚类。
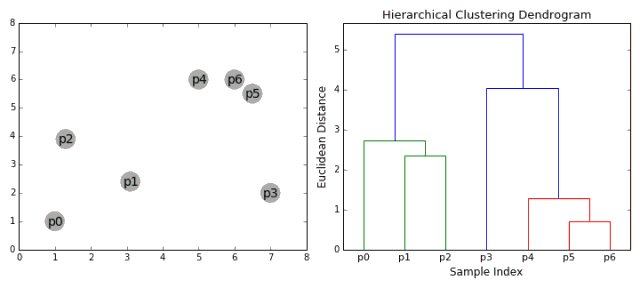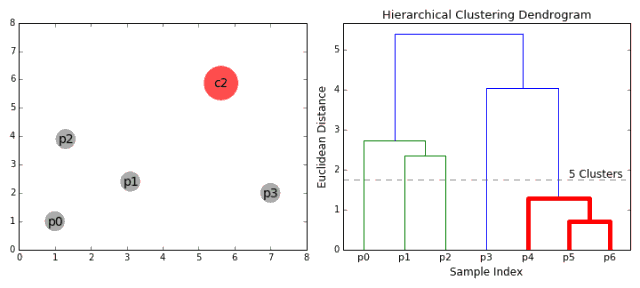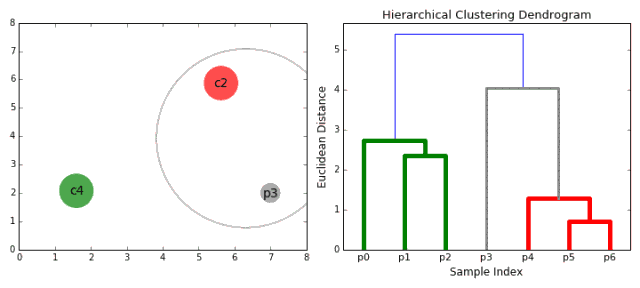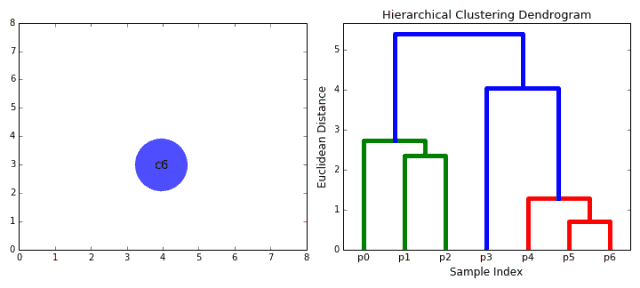
1.首先将每一个数据点看成一个类别,通过计算点与点之间的距离将距离近的点归为一个子类,作为下一次聚类的基础;
2.每一次迭代将两个元素聚类成一个,上述的子类中距离最近的两两又合并为新的子类。最相近的都被合并在一起;
3.重复步骤二直到所有的类别都合并为一个根节点。基于此我们可以选择我们需要聚类的数目,并根据树来进行选择。
层次聚类无需事先指定类的数目,并且对于距离的度量不敏感。这种方法最好的应用在于恢复出数据的层次化结构。但其计算复杂度较高达到了O(n^3).
每个聚类算法都有各自的优缺点,我们需要根据计算需求和应用需求选择合适的算法来进行处理。随着深度学习的出现,更多的神经网络、自编码器被用来提取数据中的高维特征用于分类,是值得注意的研究热点。
最后如果想练练手的话,scikit Learn上有很多例子可以操练,实践才是最好的老师~~http://scikit-learn.org/stable/modules/clustering.html#clustering
-
三种聚类算法学习2020-03-12 0
-
聚类算法及聚类融合算法研究2011-08-10 884
-
基于近邻传播的迁移聚类算法2018-01-07 681
-
基于密度DBSCAN的聚类算法2018-04-26 21677
-
Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述2018-05-27 30294
-
金融机构使用案例分析机器学习算法——聚类clustering2020-10-12 2834
-
如何在python中安装和使用顶级聚类算法?2021-03-12 2214
-
最实用的的五种机器学习算法2021-03-24 6505
-
K-MEANS聚类算法概述及工作原理2022-06-06 3935
-
10种聚类算法和Python代码12023-02-20 831
-
10种聚类算法和Python代码22023-02-20 977
-
10种聚类算法和Python代码32023-02-20 1116
-
10种聚类算法和Python代码42023-02-20 1279
-
机器学习算法的5种基本算子2023-08-17 1761
-
机器学习算法总结 机器学习算法是什么 机器学习算法优缺点2023-08-17 1850
全部0条评论

快来发表一下你的评论吧 !
