

工业应用的自然语言理解和结构化知识
电子说
描述
5月19日-20日,2018全球人工智能技术大会(GAITC)在北京国家会议中心隆重举办,全球业界顶尖领袖在此汇聚,围绕AI热点,分享AI领域最新洞见,引领年度行业发展风向标。
深知无限人工智能研究院首席科学家汉斯‧乌思克尔特院士(Prof. Dr. Hans Uszkoreit)担任本次大会主席。
以下内容为汉斯‧乌思克尔特院士演讲摘要:
工业4.0--智能工厂
▶ 工业4.0智能工厂的3个层级:
智慧工厂
智慧运营服务
智能支持服务
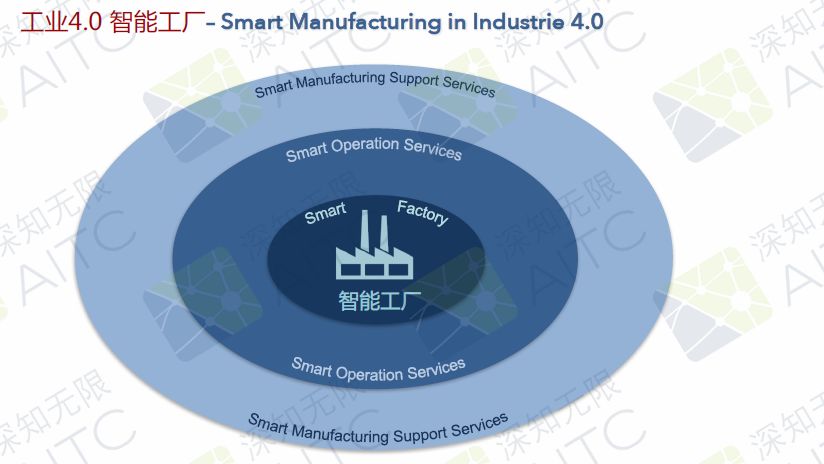
▶ 智能工厂核心点
第一,网络物理系统,包括传感器、行动体、处理器,都和物联网相连。通过数据的输入,我们可以进行很多的学习,并对图片进行很多的翻译和理解,还可以进行相关的推理,进行快速的迭代和自动化。
第二,在工业4.0中,还有很重要的一点:Digital Twin技术--具有历史/记忆的产品(或部件)的数字模型。Digital Twin主要是来自于语义产品记忆,在这个理念中,我们认为所有的部件都应该在自己的机器上有一个Digital Twin。一开始建立的模型并不是非常好,它们是使用一些结构化的语言以及模型,同时,人们也可以将自己的语言输入到Digital Twin之中。通过Digital Twin,我们的机器可以为人所用,也可以被机器自己使用。
第三,柔性产品驱动的生产配置。比如我们的产品会告诉我们的机器它下一步需要做什么样的步骤,比如去年到哪一个生产点进行怎么样的加工。所以我希望我们整个的系统是柔性并且非常灵活的,而不是非常僵硬的。
第四,智能自动化机器人以及人机协同。
第五,基于AI的流程优化 - 预测资源利用率。我们可以使用预测性的资源,不光是预测性的维护,而且可以预测我们的能源使用、物料使用,可以预测所有和生产相关的资源。
这些都是通过我们与现实生产得到的学习结论。在DFKI,我们和很多工厂进行了合作,希望可以把我们的技术和想法放到这些工厂里进行实践。
▶ 智能运营服务
智能工厂的外层是智能运营服务,现在已经有了智能出行、智能物流、智能大楼、智能产品、智能电网,这些就是智能工厂外层的一些设施,他们会和生产密切相关。对于运行服务而言,它的重点和智能工厂或者智能手工生产是相当的。
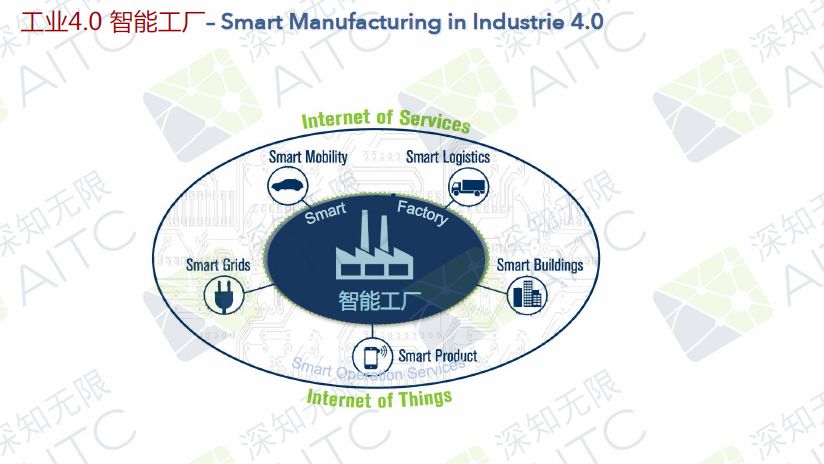
▶ 智能支持服务
智能工厂的第三层——智能支持服务,我认为对于工厂而言,最重要的东西并不在工厂之内,很多在工厂工作的人觉得工厂或者产品是最重要的,但其实并非如此。产品的最终消费者是最重要的,以及供应商等,如果我的供应商对我停止供应,工厂会停产,还有投资人、监管者、技术提供商、服务合作伙伴等等都非常重要。
同时,语言也是至关重要的。我们需要从所有工厂以外的地方获取很多的数据,并把这些数据应用于我们的工厂,比如进行产品研发、产品升级、生产计划,比如我们希望看消费者需要的功能有哪些,消费者的理想定价是怎样的,还需要看我们从供应商那里可以得到什么,因为如果没有供应商,我们无法进行生产。
在这里有很多非结构性数据,智能工厂的第三层到第一层是相互贯穿的,一方面我们需要翻译很多的数据、语言,理解很多来自于不同行动体或者合作伙伴的数据,另一方面我们也会把数据发给合作伙伴(如供应商),需要发给他们很多数据告诉他们我们所需要的规格是什么样的,所以整个的结构非常复杂。通过这样的合作可以获得智能产品管理、智能客户关系管理、智能产品经理、智能投资者管理、智能监管者管理、智能市场调查等等。
如何从外部获得数据?有很多数据都来自于合作伙伴的数字内容,包括投资人、政府等等。我们在外部的数据,需要使用媒体、社交媒体、开放知识、开放数据。
例如:
①去年,大众因为供应商出现了一些问题,他们并没有及时获得警告,而大众花费了14个月来寻找替代供应商。
②我们之前在一个项目上可以和西门子合作,他们当时有19万多的直接供应商,还有数百万的间接供应商。我们希望能够用我们的技术帮助他们,例如系统找出一些早期的预警信号。
知识图谱
我们是整个开放数据库,我们希望做一个桥梁连接公有和私有的知识库,希望能够在整个知识领域中,包括不同的百科网站(如维基百科)或者其他的知识管理项目中,把它们和工厂的私有知识库连接起来,这样就能以知识图谱的方式构建这个大桥。比如说Google、必应、百度等不同类型的知识图谱。为了把内部和外部的知识库联系在一起,通常会构建一个公司内部的知识图谱,这样才会有更多的可能。
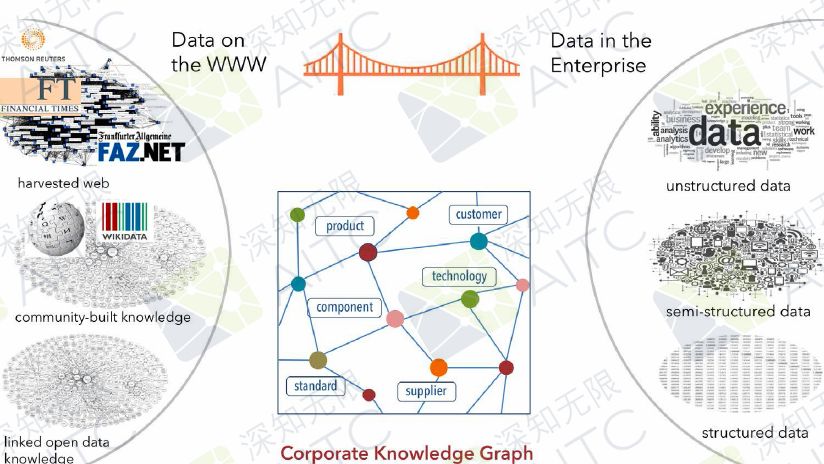
维基百科非常庞大,是一个巨大的数据库。但维基百科所有的印刷版,公开发行的只有这么多,这也是我们为什么想真正实现线上浏览或者查询。因为如果完全都做打印版的,对于语音学家或者知识领域的专家来说,很难实现突破。如果我们想做一些搜索和检索会非常困难,并且有些知识是没有办法转化为知识图谱的。
我从Google的系统中截取了一个关于艺术领域的例子。由Google的知识图谱所提供,并不是来自于某一个单一的文档,而是一个结合。
针对大数据的NLP技术
▶ 自然语言理解存在的2个问题
语言模糊性
同样的句子,在一些语境下可能会有不同理解,比如某一个词语、某一个句子可以有不同的解读。比如“放”这个词,如果去字典上查有很多不同的理解,或者时光如梭的英文也有不同的理解。人们对于解读同一件事情的方式是千千万万的,大家都有不同的解读,所以对于语言的解读和翻译非常困难。
我们在2008年做过一个研究,微软买入了Powerset这个公司,其实可以用不同的词语,比如说买入、收购或者其他的词语,它可能只是用了非常模糊的词,但我们知道他们是全资收购了,甚至是吞并。不同的词语可以表达出相同的意思。对人们来说,他们可以想出不同类型的词语,比如社交媒体上的人或者记者可能会根据自己的内容表达选择一个最佳的词语,但对于机器学习来说比较困难。
我们需要打造出一套基于统计学的机器学习、神经元学习,而且整个的潜力和挑战都是前所未有的。如果我们学习了这些词组,比如A收购B,我们需要让机器理解,他究竟是获得了某一个东西,还是真的收购了某一家公司。所以我们必须从这些句子中提取相应的信息。比如说它的价格、涉及到的公司,我们需要提取出正确关键的词组。而且我们需要高亮出最关键的信息,还有一些简单的信息,简单的信息可以忽略不计,因为它可能会有变化。所以我们在分析语料时,我们会用绿色标注出最重要的信息是我们想让机器去学习的。


超级学习技术
我们还会根据神经原的组成部分进行具体的语义解析,我们会提取信息做语义的筛选。因为可能一句话里,他说微软投资了Powerset这家公司,他用了投资这个词,但我们还要对整个信息做一些筛选和解读。这样才能把非结构化的信息真正的结构化。
我们之前也发表了很多的文献和相应的专利,我们也在很多行业的应用上有所推广,目前也在中国有一些合作的项目。我们还在不断地更新、改进,现在也可以识别中文。同时我们也希望能够覆盖更多的语言。
-
python自然语言2018-05-02 0
-
NLPIR语义分析是对自然语言处理的完美理解2018-10-19 0
-
hanlp汉语自然语言处理入门基础知识介绍2019-01-02 0
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
自然语言处理的语言模型2020-04-16 0
-
什么是自然语言处理2021-09-08 0
-
基于自然语言处理的知识检索算法研究2017-01-07 679
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5113
-
浅析自然语言处理知识体系结构2018-08-18 4657
-
自然语言处理(NLP)知识结构总结2018-08-29 4426
-
解读人工智能理解的自然语言的原理和概念2019-08-09 5633
-
谷歌和微软自然语言理解榜单中超越人类表现2021-01-08 1712
-
一窥AMR图谱在自然语言处理中的应用2022-09-05 1344
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 831
全部0条评论

快来发表一下你的评论吧 !
