

一个基于卡片的增强现实应用程序
描述
你可能已经(或可能没有)听过或看过增强现实电子游戏隐形妖怪或Topps推出的3D棒球卡。其主要思想是在平板电脑,PC或智能手机的屏幕上,根据卡片的位置和方向,渲染特定图形的3D模型到卡片上。
图1:隐形妖怪增强现实卡。
上个学期,我参加了计算机视觉课程,对投影几何学的若干方面进行了研究,并认为自己开发一个基于卡片的增强现实应用程序将是一个有趣的项目。我提醒你,我们需要一点代数来使它工作,但我会尽量少用。为了充分利用它,你应该轻松使用不同的坐标系统和变换矩阵。
<免责声明
首先,这篇文章并不是一个教程,也不会涉及计算机视觉技术的全面指南或解释,我只提及后续工作所需的要点。不过,我鼓励你深挖这一路上出现的概念。
其次,不要指望一些专业的结果。我这样做只是为了好玩,而且我做的很多决策本可以做的更好。文章的主要思想是开发一个概念验证应用程序。
/免责声明>
说到这里,后面的我负责了。
我们从哪里开始?
从整体上看这个项目可能会比实际上更困难。所幸的是,我们能够把它划分成更小的部分,当这些部分合并在一起时,我们就可以使增强现实应用程序工作了。现在的问题是,我们需要哪些更小的块?
让我们仔细看看我们想要达到的目标。如前所述,我们希望在屏幕上投影一个图形的三维模型,其位置和方向与某个预定义平面的位置和方向相匹配。此外,我们希望实时进行,这样,如果平面改变其位置或方向,投影模型就会相应地改变。
为了实现这一点,我们首先必须能够识别图像或视频帧中的参考面。一旦确定,我们可以轻松确定从参考面图像(2D)到目标图像(2D)的转换。这种变换叫做单应。但是,如果我们想要将放置在参考面顶部的3D模型投影到目标图像上,我们需要扩展前面的变换来处理参考面坐标系中要投影点的高度不是零的情况。这可以用一些代数来实现。最后,我们将这个转换应用到我们的3D模型并在屏幕上绘制。考虑到前面的观点,我们的项目可以分为:
1、识别参考平面。
2、估计单应性。
3、从单应性推导出从参考面坐标系到目标图像坐标系的转换。
4、在图像(像素空间)中投影我们的3D模型并绘制它。
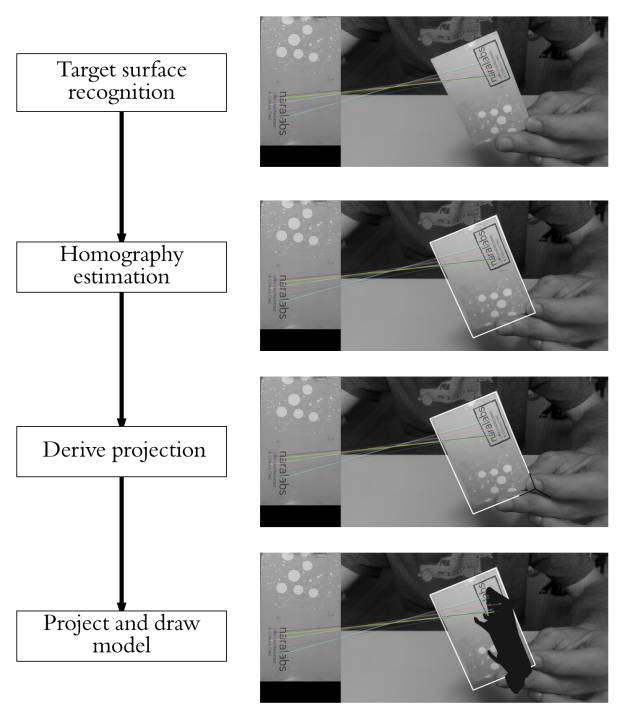
图2:概述增强现实应用程序的整个过程。
我们将使用的主要工具是Python和OpenCV,因为它们都是开源的,易于建立和使用,并且使用它们能快速构建原型。用到代数,我将使用numpy。
识别目标表面
从对象识别的许多可能的技术中,我决定用基于特征的识别方法来解决这个问题。这种方法不深入细节,包括三个主要步骤:特征检测或提取、特征描述和特征匹配。
特征提取
大体而言,这一步骤包括先在参考图像和目标对象中寻找突出的特征,并以某种方式描述要识别的对象的一部分。这些特征稍后可以用于在目标对象中查找参考对象。当目标对象和参考图像之间找到一定数量的正特征匹配时,我们假设已经找到目标。为了使之工作,重要的是要有一个参考图像,在那里唯一能看到的是要被发现的物体(或表面,在这种情况下)。我们不想检测不属于表面的特征。而且,虽然我们稍后会处理这个问题,但是当我们估计场景中表面的样子时,我们将用到参考图像的尺寸。
对于要被标记为特征的图像的区域或点,它应该有两个重要的属性:首先,它应该至少在本地呈现一些唯一性。这方面典型的例子可能是角或边。其次,因为我们事先不知道它是什么,例如,在我们想要识别它的图像中,同一物体的方向、尺度或亮度条件,理想情况下,应该是不变的变换,即不变的尺度、旋转或亮度变化。根据经验,越恒定越好。

图3:左侧,从我将使用的表面模型中提取的特征。右侧,从场景中提取的特征。注意,最右侧图形的角落是如何检测为兴趣点的。
特征描述
一旦找到特征,我们应该找到它们提供的信息的适当表示形式。这将允许我们在其它图像中寻找它们,并且还可以获取比较时两个检测到的特征相似的度量。描述符提供由特征及其周围环境给出的信息的表示。一旦描述符被计算出来,待识别的对象就可以被抽象成一个特征vector,该vector包含图像和参考对象中发现的关键点的描述符。
这当然是个好注意,但实际上该怎么做呢?有很多算法可以提取图像特征并计算其描述符,因为我不会更详细地讨论(整篇文章可能仅限于此),如果你有兴趣了解更多的话,可以看看SIFT, SURF,或 Harris。我们将使用在OpenCV实验室开发的,它被称为ORB(Oriented FAST and Rotated BRIEF)。描述符的形状和值取决于所使用的算法,在我们的例子中,所获得的描述符将是二进制字符串。
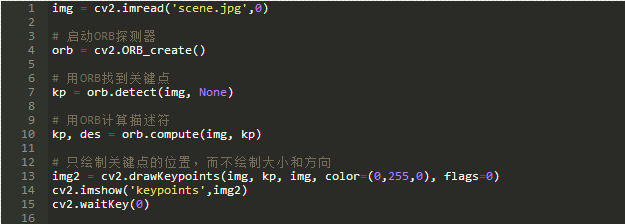
使用OpenCV,通过ORB探测器提取特征及其描述符很容易:
特征匹配
一旦我们找到了对象和场景的特征,就要找到对象并计算它的描述符,是时候寻找它们之间的匹配了。最简单的方法是取第一个组中每个特征的描述符,计算第二组中所有描述符的距离,并返回最接近的一个作为最佳匹配 (在这里我要指出,选择一种与使用的描述符相匹配的距离测量方法很重要。因为我们的描述符是二进制字符串,所以我们将使用明汉距离)。这是一种暴力方法,而且存在更先进的方法。
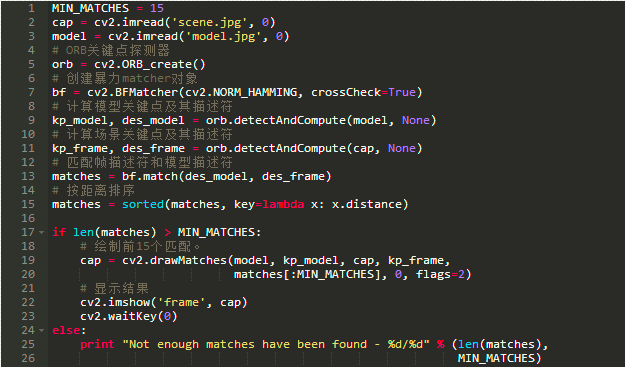
例如,我们将使用的,我们可以检查,前面解释过的匹配从第二组向第一组方向来计算匹配时也是最好的匹配。这意味着这两个特征相互匹配。一旦两个方向的匹配完成,我们只接受满足先前条件的有效匹配。图4显示了使用该方法找到15个最佳匹配项。
减少误报数量的另一种选择是检查到第二个最佳匹配的距离是否低于某一阈值。如果是,那么匹配被认为是有效的。

图4:参考面和场景之间找到最接近的15个暴力匹配
最后,在找到匹配之后,我们应该定义一些标准来决定对象是否被找到。为此,我定义了应该找到的最小匹配数的阈值。如果匹配的数量高于阈值,则我们假设对象该已经被找到。否则,我们认为没有足够的证据表明识别是成功的。
使用OpenCV ,所有这些识别过程都可以用几行代码完成:
最后要说明的是,在进入这个过程的下一步之前,我必须指出,因为我们想要一个实时的应用程序,所以最好是实现一个跟踪技术,而不仅仅是简单的识别。这是因为,对象识别将独立地在每个帧中执行,而不考虑以前的帧,这可以添加引用对象位置的有价值的信息。另一件需要考虑的事是,找到参考面越简单检测越健壮。从这个特定的意义上,我使用的参考面可能不是最佳的选择,但它有助于理解过程。
单应估计
一旦我们识别当前帧的参考面而且有一组有效匹配,我们可以估计两幅图之间的单应。前面已经解释过,我们想要找到将点从参考面映射到图像平面的转换(参见图5)。这个转换必须更新我们处理的每个新帧。
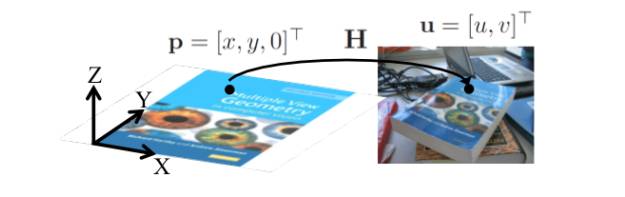
图5:平面和图像之间的单应。来源: F. Moreno.
我们怎么能找到这样的转变呢?既然我们已经找到了两幅图像之间的一组匹配,我们当然可以直接通过任何现有的方法(我提议使用RANSAC)找到一个同构转换来执行映射,但让我们了解一下我们正在做什么(见图6)。如果需要,你可以跳过以下部分(在图10之后继续阅读),因为我只会解释我们将要估计的转换背后的原因。
我们所拥有的是一个具有已知坐标的对象(在这种情况下是一个平面),比方说世界坐标系,我们用位于相对于世界坐标系的特定位置和方向的摄像机拍摄它。我们假定相机遵循针孔模型工作,这大致意味着穿过3D点p和相应的2D点u的光线相交于摄像机的中心c。如果你有兴趣了解更多关于针孔模型的知识,这里有一个好的资源。
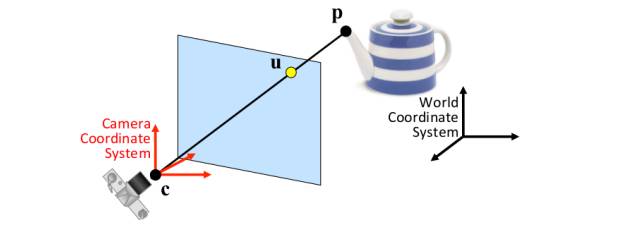
图6:成像假定为针孔成像模型。来源:F. Moreno.
虽然不是完全正确的,但针孔模型假设简化了我们的计算,并对于我们的目的来说工作得很好。如果我们假设可以计算为针孔照相机(公式的推导作为练习留给读者),则点p在相机坐标系统中表示为u,v坐标(图像平面中的坐标):

图7: 成像假定为针孔成像模型。来源: F. Moreno。
在焦距是从针孔到图像平面的距离的情况下,光学中心的投影是光学中心在图像平面的位置,k是缩放因子。前面的方程告诉我们图像是如何形成的。然而,如前所述,我们知道点p在世界坐标系而不是相机坐标系中的坐标,因此我们必须添加另一个将世界坐标系中的点映射到相机坐标系的转换。根据变换,世界坐标系中的p点的图像平面坐标是:
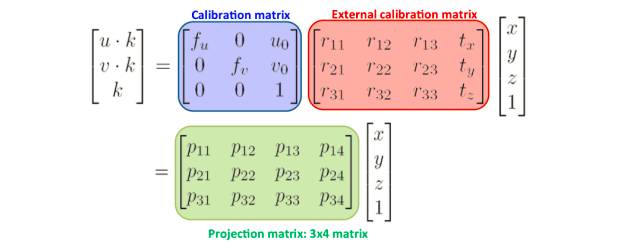
图8:计算投影矩阵。来源: F. Moreno。
幸运的是,由于参考面的点的z坐标始终等于0(参考图5),我们可以简化上面发现的转换。很容易看出,z坐标和投影矩阵的第三列的乘积将是0,所以我们可以将该列和z坐标从前面的等式中删除。将校准矩阵重命名为A,并考虑到外部校准矩阵是齐次变换:
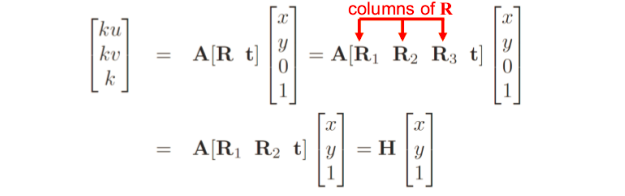
图9:简化投影矩阵。来源: F. Moreno。
从图9我们可以得出结论,参考面与图形平面之间的单应,这是我们从之前发现的匹配中估计出的矩阵:
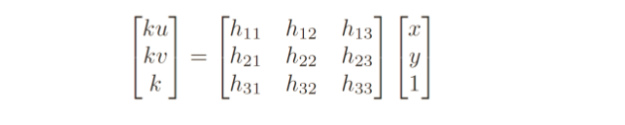
图10:参考平面和目标图像平面之间的单应矩阵。来源: F. Moreno。
有几种可以让我们估计单应矩阵的值,并且你可能熟悉其中的一些。我们将使用的是RANdom SAmple Consensus(RANSAC)。RANSAC是一种用于存在大量异常值的模型拟合的迭代算法,图12列出了该过程的纲要。因为我们不能保证我们发现的所有匹配都是有效的匹配,我们必须考虑有可能存在一些错误的匹配(这将是我们的异常值),因此我们必须使用一种对异常值有效的估计方法。图11说明了如果我们认为没有异常值估计单应时,可能会存在的问题。
图11:存在异常值的单应估计。来源: F. Moreno。

图12:RANSAC算法概述。来源: F. Moreno。
为了说明RANSAC如何工作,并且使事情更清楚,假设我们有一组要使用RANSAC拟合一条线的点:

图13:初始点集。来源: F. Moreno。
根据图12所示的概述,我们可以推导出使用RANSAC拟合线的具体过程(图14)。

图14:RANSAC算法将一条线拟合到一组点。来源: F. Moreno。
运行上述算法的一个可能的结果可以在图15中看到。注意,该算法的前3个步骤只显示第一次迭代(由右下角的数字表示),并且只显示评分步骤。
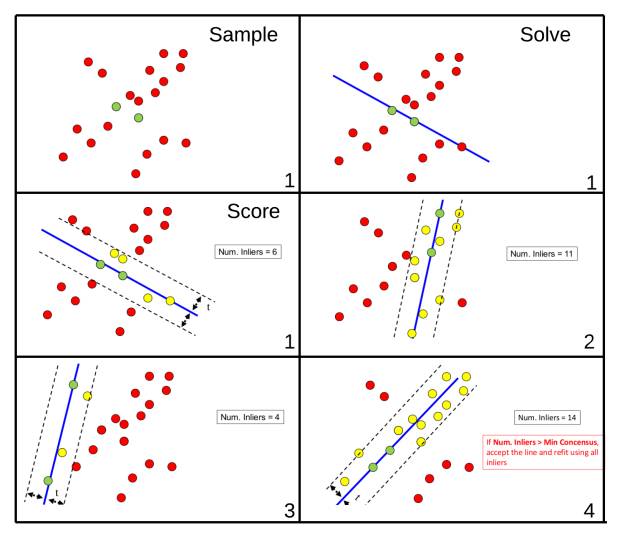
图15:使用RANSAC将一条线代入一组点。来源:F. Moreno。
现在回到我们的用例,单应矩阵估计。对于单应估计,算法如图16所示。由于它主要是数学,所以我不会详细讨论为什么需要4个匹配或者如何估计H。但是, 如果你想知道为什么以及如何完成,这有一个很好的解释。

图16:用于单应矩阵估计的RANSAC。来源: F. Moreno。
在看OpenCV如何为我们处理这个问题之前,我们应该讨论一下算法的决定性的一个方面,就是匹配H的含义。它的主要含义是,如果在估计单应性之后,我们将未用于估计的匹配映射到目标图像,那么参考面的投影点应该接近目标图像中的匹配点。 如何认为它们一致取决于你。
我知道要达到这一点很困难,但谢天谢地,在OpenCV中,使用RANSAC估计单应很简单:
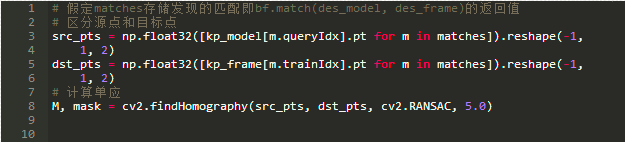
其中5.0是距离阈值,用来确定匹配与估计单应是否一致。如果在估计单应之后,我们将目标图像的参考面的四个角投影到一条线上,我们应该期望得到的线将参考面包围在目标图像中。我们可以这样做:
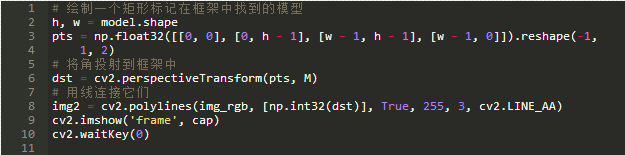
结果是:
图17:具有估算单应的参考面的投射角。
我想今天就到这里了。在下一篇文章,我们将看到如何扩展我们已经估计的单应矩阵,不仅可以在投影参考面上的点,而且可以投影从参考面坐标系到目标图像的任何3D点。我们将使用这个方法来实时计算,每个视频帧的特定投影矩阵,然后从.obj文件选择投影的视频流3D模型。在下一篇文章的结尾,你可以看到类似于下面GIF中所看到的内容:
与往常一样,发布第2部分时,我会上传该项目的完整代码和一些3D模型到GitHub供你测试。
-
【BPI-M64试用体验】之结项——特征识别及增强现实应用2017-05-25 0
-
AR增强现实智能车硬创客 2021-08-24
-
增强现实和虚拟现实改变工厂车间面貌2019-08-19 0
-
AR增强现实技术介绍2021-01-26 0
-
Thred:对增强现实功能的Sweep应用程序进行独立的、史无前例的测试2018-01-17 3474
-
RelayCar应用程序正式支持增强现实体验2018-11-30 777
-
NASA阿姆斯特朗飞行研究中心一直致力于开发增强现实应用程序2018-12-18 2631
-
增强现实技术将应用到广告中 颠覆当前广告模式2020-08-06 1592
-
微软官宣获得“增强”TikTok应用程序2020-12-16 1677
-
增强现实隐形眼镜初创公司开发应用程序2021-03-22 1461
-
增强开源应用程序中的处理器性能2021-05-15 377
-
移动应用程序开发 2k19 的设计趋势2022-07-28 587
-
使用语音AI开发下一代扩展现实应用程序2022-10-11 990
-
一文告诉你什么是增强现实(AR)?2022-09-15 926
-
增强现实是人机交互技术吗2023-08-12 627
全部0条评论

快来发表一下你的评论吧 !
