

LSTM之父Jürgen Schmidhuber再发新作!
电子说
描述
LSTM之父Jürgen Schmidhuber,借鉴了人类认知世界的模式,为机器建造了一个世界观模型,本文带你一起来读LSTM之父的一篇最新力作,同时,手把手教你训练出一个有简单世界观的AI赛车手。
LSTM之父Jürgen Schmidhuber再发新作!
这一次,他借鉴了人类认知世界的模式,为机器建造了一个世界观模型。
诸多证据表明,人脑为了处理日常生活中的海量信息,学会了对这些时空信息作出抽象化的处理。借此,我们能够在面对周遭复杂的信息时,进行迅速而准确的分析。而我们在当前所“看”到的这个世界,也受到了大脑对未来世界预测的影响。
比方说,棒球选手可以毫不费力地击中时速100英里的棒球,正是得益于大脑对棒球运动轨迹的精确判断。
那么,我们能不能让机器也学会这样的世界观呢?机器有了世界观后又将具备怎么样的能力呢?
今天,我们就带你一起来读LSTM之父的一篇最新力作。同时,也会手把手教你训练出一个有简单世界观的AI赛车手。到底有多厉害,试了就知道!
提出问题
让我们通过一个具体案例来探究这个问题:如何让机器拥有世界观?
假设我们要训练出一个AI赛车手,让它擅长在2D赛道上驾驶汽车。示例如下图。
在每个时间节点,这个AI赛车手都会观察它的周围环境(64×64像素彩色图像),然后决定并执行操作——设定方向(-1到1)、加速(0到1)或制动(0到1)。在它执行操作后,它所处的环境会返回下一个观测结果。以此类推,这个过程讲不断重复。
它的目标是,在尽可能短的时间内走完赛道。
解决方案
我们给出一个由三部分组成的解决方案。
变分自编码器(VAE)
当你在开车的时候做决定时,你并不会主动分析你视图中的每一个“像素”——相反,你的大脑会将视觉信息凝聚成较少数量的“隐藏”实体,比如道路的笔直程度、即将到来的弯道以及你在道路中的相对位置,从而判断出你需要操作的下一个动作。
这正是VAE的要义所在——将64x64x3(RGB)输入图像压缩成一个长度为32的特征向量(z)。
借此,我们的AI赛车手可以用更少的信息去表示周围的环境,从而提高学习效率。
递归神经网络(RNN)
没有递归神经网络的AI赛车手可能会把车开成这样。。。
回想一下。当你开车的时候,其实是会对下一秒可能出现的情况进行持续预估的。
而RNN就能够模拟这种前瞻性思维。
与VAE类似,RNN试图捕捉到汽车在其所处环境中当前状态的隐藏特性,但这次的目的是要基于先前的“z”和先前的动作来预测下一个“z”的样子。
控制器(Controller)
目前为止,我们还没有提到任何有关选择动作的事情。因为,这些选择都是控制器要做的。
控制器是一个密集连接的神经网络,输入是z(VAE的当前隐藏状态——长度为32)和h(RNN的隐藏状态——长度为256)的串联,3个输出神经元对应于三个动作,并被缩放到适当的范围内。
为了理解这三个组成部分所担任的不同角色,以及他们是如何一起工作的,我们可以想象他们之间的一段对话:
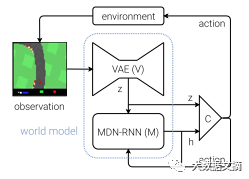
世界模型体系结构图
VAE:(关注最新的64 * 64 * 3的观测结果)这看起来像一条直路,前方稍微向左弯曲,汽车朝向道路方向(z)。
RNN:基于该描述(z)和控制器在上一个时间节点(动作)选择加速的情况,我将更新我的隐藏状态(h),以便预测下一个观测结果仍然是笔直的道路,但要略微左转一点。
Controller:基于VAE(z)的描述和RNN(h)反馈的当前隐藏状态,我的神经网络下一个输出的动作为[0.34,0.8,0]。
然后,这个操作会被传递给环境,该环境会返回更新后的观测结果,并重新开始循环。
现在,让我们来实际演练一下吧!
实现代码来了
如果你使用的是高规格笔记本电脑,则可以在本地运行此解决方案,但我建议你在谷歌云计算平台(Google Cloud Compute)上用功能更强大的计算机来运行,从而在短时间内完成。
以下步骤已经在Linux(Ubuntu 16.04)上进行了测试——在Mac或Windows上只需要更改软件包安装的相关命令即可。
第一步:下载代码
在命令行中输入以下内容:
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
第二步:创建虚拟环境
创建一个Python3虚拟环境(这里使用的是virutalenv和virtualenvwrapper):
sudo apt-get install python-pipsudo pip install virtualenvsudo pip install virtualenvwrapperexport WORKON_HOME=~/.virtualenvssource /usr/local/bin/virtualenvwrapper.shmkvirtualenv --python=/usr/bin/python3 worldmodels
第三步:安装程序包
sudo apt-get install cmake swig python3-dev zlib1g-dev python-openglmpich xvfb xserver-xephyr vnc4servercd WorldModelspip install -r requirements.txt
第四步:生成随机训练数据
对于这个塞车问题,VAE和RNN都可以使用随机生成的训练数据——也就是在每个时间节点随机采取动作所生成的观测数据。实际上,我们可以使用伪随机动作,使车在初始状态就能加速离开起跑线。
由于VAE和RNN独立于决策控制器,我们需要确保遇到各种各样的观测结果,并且选择不同行动来应对,并将结果保存为训练数据。
要生成随机策略,请从命令行运行以下命令:
python 01_generate_data.py car_racing --total_episodes 2000 –start_batch 0 --time_steps 300
如果你的服务器没有显示结果,你可以运行以下命令:
xvfb-run -a -s "-screen 0 1400x900x24" python 01_generate_data.pycar_racing --total_episodes 2000 --start_batch 0 --time_steps 300
以上命令将会产生2000个策略,保存在200个批次中,每个批次10个)。
在./data文件夹中,你会看到以下文件(*为批次号):
obs_data_*.npy (此文件将64 * 64 * 3图像存储为numpy数组)
action_data_*.npy (此文件存储三维动作)
第五步:训练VAE
这里我们只需要用obs_data_*.npy就可以训练VAE。确保你已经完成了第四步,否则这个文件不在./data文件夹下。
在命令行中运行下列语句:
python 02_train_vae.py --start_batch 0 --max_batch 9 --new_model
在每一批从0到9的数据中都会训练出一个新的变分自编码器VAE。模型的权重保存在./vae/weights.h5中。“--new_model”参数表明从头开始训练模型。
如果文件夹中已经存在weights.h5,也没有声明“--new_model”参数,脚本将直接导入这个文件中的权重,继续训练现有的模型。这样的话,你就可以实现模型的迭代训练,而不需要对每批数据都重新运行。
VAE架构的相关参数都在 ./vae/arch.py文件里声明。
第六步:生成循环神经网络RNN数据
现在我们就可以利用这个训练好的VAE模型生成RNN模型的训练集。
RNN模型要求把经由VAE编码后的图像数据(z)和动作(a)作为输入,把一个时间步长前的由VAE模型编码后的图像数据作为输出。
运行这行命令可以生成这些数据:
python 03_generate_rnn_data.py --start_batch 0 --max_batch 9
这一步需要把第0至9批的obs_data_*.npy 和 action_data_*.npy文件转成在RNN中训练所需要的格式。
这两组文件保存在./data(*是批量编号)
rnn_input_*.npy(存储了[z a]串联向量)
rnn_output_*.npy(存储了前一个时间步长的z向量)
第七步:训练RNN模型
训练RNN只需要用到rnn_input_*.npy和rnn_output_*.npy文件。确认你已经完成了第六步,否则这个文件不在./data文件夹下。
在命令行运行:
python 04_train_rnn.py --start_batch 0 --max_batch 9 --new_model
在每一批从0到9的数据中都会训练出一个新的VAE。模型的权重保存在./rnn/weights.h5。“--new_model”表明从头开始训练模型。
和VAE训练很相似的是,如果文件夹中已经存在weights.h5,也没有声明“--new_model”标志,脚本将直接导入文件中的权重,继续训练现有的模型。这样的话,你就可以实现RNN模型的迭代训练,而不需要对每批数据都重新运行。
RNN循环神经网络模型的具体参数都在./rnn/arch.py文件里声明。
第八步:训练控制器
到了最有趣的部分了!
到目前为止,我们已经使用深度学习搭建了VAE模型和RNN模型。VAE能把高维的图片降至低维的隐藏数据,RNN用来预测隐藏空间中数据的时序变化。正因为我们可以对每个模型都采用随机抽取的数据来创建训练集,模型才有可能达到预期效果。
为了训练控制器,我们将采用强化学习的方法,它使用了名叫CMA-ES(自适应协方差矩阵进化算法)的进化算法。
输入是一个288(32+256)维向量,输出是一个3维向量,因此我们要训练的参数有288 * 3 + 1 (bias) = 867个。
CMA-ES算法,首先随机生成867个参数(即一个群体)的副本,然后对环境中每个群体成员变量做测试,并记录其平均得分。正如自然选择中的法则一样,产生最高得分的权重变量允许其继续“繁殖”,并生出下一代。
运行下列代码将在你的机器上启动这个过程,并为变量选择合适的值。
python 05_train_controller.py car_racing --num_worker 16 –num_worker_trial 4 --num_episode 16 --max_length 1000 --eval_steps 25
或者在服务器上运行,但不显示结果:
xvfb-run -s "-screen 0 1400x900x24" python 05_train_controller.py car_racing --num_worker 16 --num_worker_trial 2 --num_episode 4 –max_length 1000 --eval_steps 25
--num_worker 16:worker的个数不要超过可用内核的数量
--num_work_trial 2 :每个worker测试的群体成员的数量(num_worker * num_work_trial表示每一代群体的总规模)
--num_episode 4:为群体的每个成员进行打分的次数(分数将是该次打分的平均得分)
--max_length 1000:一次打分中最大时间步长
--eval_steps 25:每隔25步对权重进行评估
默认情况下,控制器每次运行都会从零开始,将进程的当前状态保存到controller目录的pickle文件中。这样你就可以通过指定相关文件,从上一次保存的地方继续训练。
每生成一代后,算法的当前状态和最佳权重的集合将会输出到./controller文件夹。
第九步:可视化结果
经过200代的训练,我已经训练出一个平均得分约为833.13的角色。我在谷歌云上使用配置为Ubuntu 16.04, 18 vCPU, 67.5GB RAM的机器,采用的是本文给出的步骤和参数。
在论文中,作者试图在2000代训练后达到约906的平均得分,这是迄今为止该环境下的最高分。他利用了稍高的规格设置(例如10,000集训练数据,群体大小设为64,64台核心机器,每次试验16次)。
如果你想可视化控制器的当前状态,那你只需要运行下列代码:
python model.py car_racing –filename ./controller/car_racing.cma.4.32.best.json --render_mode –record_video
--filename:想要添加到控制器的权重json的路径
--render_mode :在屏幕上显示环境
--record_video:输出mp4文件到./video文件夹,展现出每个片段
--final_mode:运行100次控制器测试,输出平均得分
就是这样啦!
第十步:幻觉学习
到这一步已经很了不起了——但下一步则更令人兴奋哦,同时对人工智能未来的发展也很有启发意义。
增加难度,我们可以让赛车在行进过程中避免火球的袭击。
作者展示了角色将怎样实际地学会如何在自己的VAE / RNN模型启发的幻觉梦境中玩游戏,而不是在实际的游戏环境中。
我们唯一需要做出的改变是,训练RNN使其也可以预测出在下一个时间步长中赛车被火球击中的概率。这样,VAE / RNN组合模型可以作为一个独立的环境被封装起来,并用于训练控制器。这就是“世界模式”的概念。
我们将幻觉学习的概念总结如下:
角色的初始训练数据不过是与真实环境的随机互动。通过这一互动,它对世界“如何运作”形成了一种潜在的理解——世界运作的物理规律,以及自己的行为会如何影响世界的状态。
然后,它可以利用这种理解为一个给定的任务建立一个最佳策略,甚至无需在现实环境中进行测试,因为它可以使用自己的一套环境模型作为各种测试的“试验场”。
就像婴儿学走路一样。小婴儿通过自己的探索建立一个初步的世界观,明白自己的动作会带来的后果,然后一步步调整自己的策略。在这一过程中,婴儿甚至能够在脑海中进行自我模拟。
-
版主新作。废旧笔记本屏幕改成显示器。申请加精。2013-04-06 0
-
群主新作。呵呵。2013-04-06 0
-
最新作品2014-04-10 0
-
JU38200WA000,JU38250WN000 日本CHINO晶闸管2020-03-05 0
-
调整器JU40100WA000 JU119k0982021-01-20 0
-
什么是LSTM神经网络2021-01-28 0
-
22JU6.pdf 电子管资料数据手册2009-08-01 399
-
深度解析LSTM的全貌2018-02-02 9932
-
图灵奖为什么没颁给LSTM之父Jürgen Schmidhuber?2019-04-08 8963
-
LSTM的硬件加速方式2019-08-24 2832
-
人工智能300年!LSTM之父万字长文:详解现代AI和深度学习发展史2023-01-10 500
-
PyTorch教程-10.1. 长短期记忆 (LSTM)2023-06-05 572
-
C++之父新作带你勾勒现代C++地图2023-10-30 441
全部0条评论

快来发表一下你的评论吧 !
