

基于嵌入式数据库的海量存储技术解析
存储技术
描述
1嵌入式数据库
通常, 我们采用数据库来实现对数据的存储、检索等功能。像MySQL这类基于C/S结构的关系型数据库系统, 虽然代表着目前数据库应用的主流, 却并不能满足所有应用场合的需要。很多的应用,仅仅利用到了这些数据库产品的基本特性而已。有时我们需要的可能只是一个简单的基于磁盘文件的数据库系统,这样就不必安装庞大的数据库服务器, 以简化数据库应用程序的设计。在某些特殊应用场合,比如在嵌入式系统中,由于系统的硬件软件资源都有限,这些数据库产品就明显有一些臃肿,甚至是不可实现的。在这些情况下,嵌入式数据库的优势就特别明显了。
嵌入式数据库通常与操作系统和具体应用集成在一起, 无须独立运行的数据库引擎,由程序直接调用相应的API去实现对数据的存取操作。更直白地讲, 嵌入式数据库是一种具备了基本数据库特性的数据文件。嵌入式数据库与其它数据库产品的区别是,前者是程序驱动式,而后者是引擎响应式。嵌入式数据库的一个很重要的特点是它们的体积非常小,编译后的产品也不过几十KB, 在一些移动设备上极具竞争力。
从目前嵌入式应用的发展趋势来看,嵌入式数据库的实现必须充分体现系统的可定制性,即系统选择的技术路线要面向具体的行业应用,因而研究源码开放的嵌入式数据库具有特殊意义。
2 Berkeley DB
Berkeley DB是由sleepycat software开发的轻量级嵌入式数据库,它不仅适用于嵌入式系统,而且可以直接连接到应用程序内部,和应用程序运行在同一地址空间。传统的数据库一般作为独立服务器工作,而Berkeley DB是软件开发库,开发者将它嵌入到应用程序中,应用程序本身就是一个服务器,而只是利用嵌入式数据库开发来实现定制的数据库逻辑,避免了与应用服务器进程间通信的开销,因此Berkeley DB具有较高的运行效率,适用于资源受限的嵌入式系统。
一般而言,Berkeley DB数据库系统可以大致分为五个子系统,如图1所示。
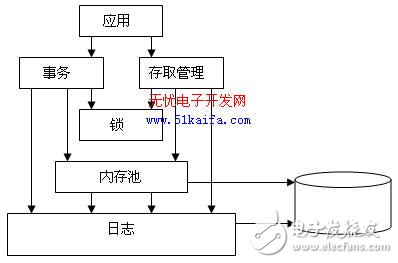
图1 Berkeley DB 子系统图
1、 存取管理子系统(Access Methods)
该子系统为创建和访问数据库文件提供基本的支持。在没有事务管理的情况下,该子系统中的模块可单独使用,为应用程序提供快速高效的数据存取服务。
2、 内存池管理子系统(Memory Pool)
该子系统就是Berkeley DB所使用的通用共享内存缓冲区,该子系统可以被应用程序单独使用。
3、 事务子系统(Transaction)
该子系统为Berkekey DB提供事务管理功能,保证操作的原则性、一致性和孤立性。事务子系统适用于对需要事务保证的数据进行修改的场合。
4、 锁子系统(Locking)
该子系统提供进程之间以及进程内部的并发管理机制,为系统提供多用户读取和单用户修改同一对象的共享控制。该子系统可以被应用程序单独使用。
5、 日志子系统(Logging)
该子系统采用的是先写日志的策略,支持事务子系统进行数据恢复,保证数据一致性。
3 基于嵌入式数据库的海量存储技术在网络性能管理系统中的应用
3.1 嵌入式数据库Berkeley DB 处理海量数据存储
传统的网络管理软件在海量数据存储方面大部分采取大型关系型数据库,由于网络管理软件要与数据库服务器进行通信,这种方式造成了系统性能的极大下降,另外随着所管网络规模的增大,信息采集的急剧增加,缓慢而频繁的数据库读写操作来不及处理实时采集到的海量数据,导致数据丢失,网络管理失真,甚至会导致系统的瘫痪。也有少数网络管理软件采取使用一种日志文件以ASCII 文本形式来记录采集到的流量数据,通常该种日志文件具有常量大小的特征,能够支持长期的网络监测任务,如国内外最为流行的免费且开放源代码的流量监测软件MRTG 就是采用这种方式实现海量数据存储的。MRTG 定期对数据进行整合,根据记录数据的日期不同而以不同的粒度保存数据,随着时间的推移,相应数据的粒度逐渐变大,但这种方式存在两个缺点:(1)所存储的数据粒度受到限制,如不能从中得到一个月前的某天平均每半个小时的数据;(2)每次数据采集后,MRTG 都根据日志文件进行流量图生成,并以HTML 格式呈现,而在实际应用场合,一个端口的流量统计分析图形被用户调用查看的概率远远小于不被调用的概率,因此浪费了大量用于生成图形的系统开销,随着网络规模的扩大,MTRG 在性能上明显不能满足要求。本文提出了一种如图2所示的流量数据采集及存储方案。网络性能管理软件实时地接收路由器发送过来的Netflow/sFlow 包(当然这里也包括用SNMP 协议定时采集到的流量数据),将其结果存储到嵌入式数据库Berkeley DB 当中,供长期历史保存。与MRTG 不同的是:(1)它采用了嵌入式数据库Berkeley DB, Berkeley DB可以直接连接到应用程序内部,和应用程序运行在同一地址空间,因此它不需要与另外的数据库应用程序进行通信,提高了应用程序的速度,减少磁盘操作的时间,防止了数据因磁盘操作缓慢而导致的数据丢失现象。(2)它并非每次采集都生成图形,而是引入触发控制方式的“按需成图”,当客户需要查看某一段时间里的图形、或者是某一端口流量、或者是某一种服务的图形等时,只需对成图控制模块执行相应的操作,成图模块则向数据库里查找特定的数据生成相应的图形。
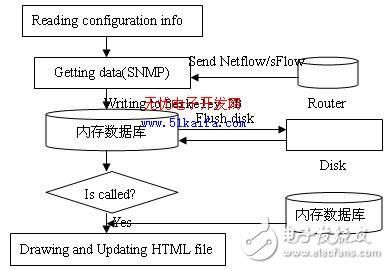
图2 流量数据采集及存储方案图
3.2 多进程、多数据库加锁机制在网络性能管理系统中处理海量数据的实现
网络管理的前提是信息采集,全面而实时地采集到所有的信息,然后对信息进行分类汇总,进而使网络管理软件实现:网络性能实时监测、系统性能实时监测、应用性能实时监测、SLA 服务质量管理、故障预警、DOS 攻击定位、病毒扫描、统计分析报告、网络容量趋势分析、系统管理与维护等功能。由于Berkeley DB 单个数据库的容量只能为256T,而网络管理信息庞大,为了扩充其存储容量,采取了多个数据库的方法。另外客户在使用网络性能管理系统软件的成图控制模块时,往往关注的是某一段时间里的图形如:某一段时间里某一端口流量图、某一段时间里某一种服务图等等,因此为了日后的成图,我们以时间(年、月、日)为单位建立若干个数据库。数据库名以某年某月某日某小时(24 小时制)命名,来存放该小时里采集到的信息。另外为了缓冲网络管理当中采集到的海量信息,我们采取了消息队列机制,父进程将采集到的信息先写入消息队列。然后子进程从消息队列中读出信息写入数据库(为了防止消息队列中信息过多单进程来不及读消息队列并写数据库而导致消息队列阻塞,整个系统效率低下。为此我们创建了多个子进程来读消息队列写数据库)。
采用上述方法以时间点(小时)为单位命名数据库,存放对应时间里的信息。但由于路由器偶尔会发生信息滞留现象(路由器滞留时间最大为30 分钟,例如:可能6 点30 以后收到的信息7 点才转发),如果按照上述存储方法将会存入7 点的数据库。导致存储信息失真,不是网络某一时刻的真实反映。为解决这一现象,每次打开两个数据库,即既打开当前点的数据库亦打开前一时间点的数据库。当收到数据包时,根据数据包中Netflow/sFlow流到达路由器的时间来判别写哪个数据库。
由于上述两个原因系统当中存在着多个子进程写多个数据库,如果不采取一定的措施很容易发生一序列的问题如:哪个进程负责创建数据库、那个进程负责关闭数据库、多个进程之间如何管理。为解决这些问题系统采取了基于多进程、多数据库的加锁机制和心跳机制。
多进程、多数据库的加锁机制实现流程如图3所示

图3 多进程、多数据库的加锁机制实现流程图
3.3 多个附加数据库查询机制的实现
由于Berkeley DB 不是关系型数据库,因此我们不能像对关系型数据库一样对其进行复合条件查询,而经常客户需要查看某一段时间里的图形如:某一段时间里某一端口流量图、某一段时间里某一种服务图等等,而这些图形的成图数据都是基于复合条件查询所得到的。为解决这个问题Berkeley DB 为我们提供了附加数据库(二级数据库),在附加数据库中我们可以设定任意的key(可以是关系数据库中多列属性的组合),因此我们可以根据附加数据库的key方便地在附加数据库中进行查询,得到所需要的数据然后在成图模块展示,为此我们引入了在对网络流量数据做统计时使用频率较高、方便成图模块查询的的5 个附加数据库分别是: SCRIP_SUBDB 、DSTIP_SUBDB 、SRCPORT_SUBDB 、DSTPORT_SUBDB 、STARTTIME_SUBDB。而且根据实际的情况我们还可以增加附加数据库的个数。另外为了提高数据库的查询效率和数据的插入速度,结合Berkeley DB 的四种访问方式,我们为主数据库采取Queue 访问方式以提高数据插入速度,并且以时间作为key。而对于附加数据库我们则BTree 访问方式以提高查询效率,而其key 则根据不同的关联函数产生,这里我们以附加数据库SCRIP_SUBDB 为例讨论主数据库与附加数据库之间的关系:
initenv(const conf_ST *conf)//初始化数据库环境
initalldb (const conf_ST *conf ,int type) //初始化所有数据库
{
⋯⋯
init_primary_db(conf,&last-db,LAST,type);//初始化前一时间点数据库
init_primary_db(conf,&(current-db),CURRENT,type); //初始化当前时间点数据库
⋯⋯
INIT_SEC_DB(srcip,SRCIP,type); //该函数实际上是定义为初始化附加数据库的一个宏
⋯⋯
}
int get_item_srcip(DB *sdbp,const DBT *pkey,const DBT *pdata,DBT *skey)
//附加数据库到主数据库设定key 的关联函数
int init_sub_db(const conf_ST *conf, DB**primary_db, DB **sub_db, int sub_db_type, int\time_db_type, int type)//初始化附加数据库
{
⋯⋯
ret =(*primary)-》associate(*primary_db,NULL,*sub_db,get_item_srcip,\
DB_CREATE); //调用Berkeley DB 系统函数将附加数据关联到主数据库并设定附加数据库中的key
⋯⋯
}
⋯⋯
4 小结:
本文作者创新点是在项目的开发和实践过程中,我们分别以不同数量级的记录写入关系型数据库Mysql 和嵌入试数据库BerkeleyDB,比较发现引入嵌入试数据库Berkeley DB 大大提高了系统的存储速度,使存取时间成倍减少。由此看来,嵌入式数据库Berkeley DB 在处理海量数据存储上比关系型数据库赢得了时间和速度上的优势,但网络管理性能系统中采集到的信息庞大,如何将Berkeley DB 数据库中存储的海量数据进行压缩仍然是值得探讨的问题。
-
基于组件的嵌入式移动数据库怎么实现?2019-10-11 0
-
嵌入式数据库msql在Linux下有哪些应用?2019-10-22 0
-
嵌入式系统到底该选哪款数据库,SQLite真的是最优解吗?2020-02-11 0
-
为什么要选择嵌入式内存数据库引擎?2021-04-27 0
-
嵌入式实时数据库基本特性是什么?有哪些应用领域?2021-04-27 0
-
怎样去实现嵌入式移动数据库的查询优化?2021-04-27 0
-
嵌入式数据库有哪些应用实例?2021-05-12 0
-
嵌入式移动数据库的关键技术有哪几种?2021-05-28 0
-
嵌入式数据库相关资料下载2021-10-27 0
-
在Spring框架中配置嵌入式数据库引擎2021-10-27 0
-
嵌入式数据库sqlite移植及使用的资料分享2021-10-28 0
-
嵌入式系统中的数据存储和管理的相关资料分享2021-12-17 0
-
跨平台嵌入式数据库EffiProz介绍2021-12-21 0
-
嵌入式数据库的作用是什么2021-12-21 0
-
嵌入式数据库的海量存储技术研究2009-07-30 443
全部0条评论

快来发表一下你的评论吧 !
