

多层分布式表征学习不仅有深度神经网络,同时还有决策树!
电子说
描述
自去年周志华等研究者提出了「深度森林」以后,这种新型的层级表征方式吸引了很多研究者的关注。今日,南京大学的冯霁、俞扬和周志华提出了多层梯度提升决策树模型,它通过堆叠多个回归 GBDT 层作为构建块,并探索了其学习层级表征的能力。此外,与层级表征的神经网络不同,他们提出的方法并不要求每一层都是可微,也不需要使用反向传播更新参数。因此,多层分布式表征学习不仅有深度神经网络,同时还有决策树!
近十年来,深层神经网络的发展在机器学习领域取得了显著进展。通过构建分层或「深层」结构,该模型能够在有监督或无监督的环境下从原始数据中学习良好的表征,这被认为是其成功的关键因素。成功的应用领域包括计算机视觉、语音识别、自然语言处理等 [1]。
目前,几乎所有的深层神经网络都使用具有随机梯度下降的反向传播 [2,3] 作为训练过程中更新参数的幕后主力军。实际上,当模型由可微分量(例如,具有非线性激活函数的加权和)组成时,反向传播似乎仍是当前的最佳选择。其他一些方法如目标传播 [4] 已经被作为训练神经网络的替代方法被提出,但其效果和普及还处于早期阶段。例如,[5_]_的研究表明,目标传播最多可达到和反向传播一样的效果,并且实际上常常需要额外的反向传播来进行微调。换句话说,老掉牙的反向传播仍然是训练神经网络等可微分学习系统的最好方法。
另一方面,探索使用非可微模块来构建多层或深度模型的可能性的需求不仅仅是学界的兴趣所在,其在现实应用上也有很大的潜力。例如,基于树的集成(例如随机森林 [6] 或梯度提升决策树(GBDT)[7] 仍然是多个领域中建模离散或表格数据的主要方式,为此在这类数据上使用树集成来获得分层分布式表征是个很有趣的研究方向。在这样的案例中,由于不能使用链式法则来传播误差,反向传播不再可行。这引发了两个基本的问题:首先,我们是否可以用非可微组件构建多层模型,从而中间层的输出可以被当作分布式表征?其次,如果是这样,如何在没有反向传播的帮助下,联合地训练这种模型?本文的目的就在于提供这种尝试。
近期 Zhou 和 Feng [8] 提出了深度森林框架,这是首次尝试使用树集成来构建多层模型的工作。具体来说,通过引入细粒度的扫描和级联操作(cascading operation),该模型可以构建多层结构,该结构具备适应性模型复杂度,且能够在多种类型的任务上取得有竞争力的性能。[8] 提出的 gcForest 模型利用了集成学习多样性增强的各种策略,然而该方法仅适用于监督学习设置。同时,该论文仍然不清楚如何利用森林来构建多层模型,并明确地测试其表征学习能力。由于很多之前的研究者认为,多层分布式表征 [9] 可能是深度神经网络成功的关键,为此我们应该对表征学习进行这样的探索。
该研究力求利用两个方面的优势:树集成的出色性能和分层分布式表征的表达能力(主要在神经网络中进行探索)。具体来说,本研究提出了首个多层结构,每层使用梯度提升决策树作为构造块,明确强调其表征学习能力,训练过程可以通过目标传播的变体进行联合优化。该模型可以在有监督和无监督的环境下进行训练。本研究首次证明,确实可以使用决策树来获得分层和分布式表征,尽管决策树通常被认为只能用于神经网络或可微分系统。理论论证和实验结果均表明了该方法的有效性。
3 提出的方法
这一部分机器之心并不详细介绍,具体的方法读者可参考原论文第三章。在一般的多层前馈结构中,每一层都是可微函数,因此我们可以使用反向传播传递梯度并高效地更新参数。但是当每一个层级函数都是不可微或者非参数化的,那么我们就不能使用反向传播。所以这一部分重点在于解决当层级函数 F_i 是梯度提升决策树时,其参数的更新方法。
训练神经网络时,初始化可以通过向每个参数分配随机高斯噪声来实现,然后该步骤移动到下一阶段,即参数更新。对于此处介绍的树结构模型来说,从所有可能的树配置分布中绘制随机树结构不是一件容易的事情,因此本论文没有随机初始化树结构,而是生成一些高斯噪声作为中间层的输出,并训练一些非常小的树来获取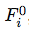 ,其中索引 0 表示该初始化阶段获取的树结构。之后训练步骤移动到迭代更新正向映射和逆向映射。图 1 和算法 1 总结了该步骤。
,其中索引 0 表示该初始化阶段获取的树结构。之后训练步骤移动到迭代更新正向映射和逆向映射。图 1 和算法 1 总结了该步骤。
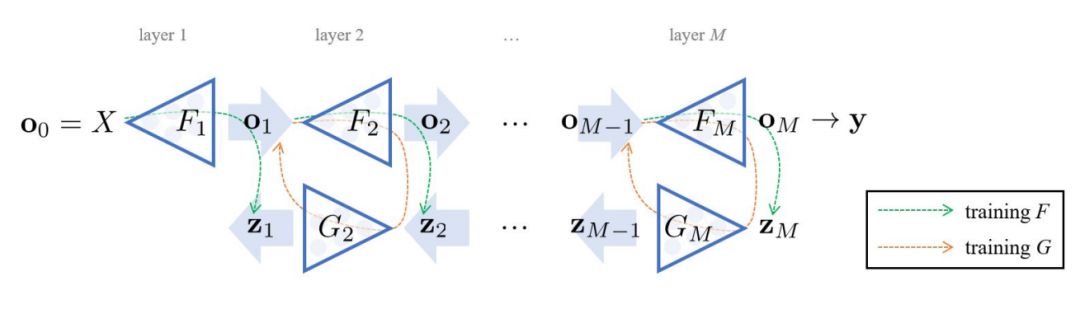
图 1:训练 mGBDT 步骤的示意图。
值得注意的是,[23] 利用 GPU 加速训练 GBDT,Korlakai & Ran [24] 展示了一种实施 GBDT drop-out 技术的高效方式,进一步提升了性能。至于多维输出问题,使用 GBDT 的原始方法内存效率较低。Si 等人 [25] 提出了解决该问题的有效方式,可以在实践中将内存降低一个数量级。

4 实验
4.1 合成数据
为了进行完整性检查,研究者在合成数据集上训练两个小的多层 GBDT。
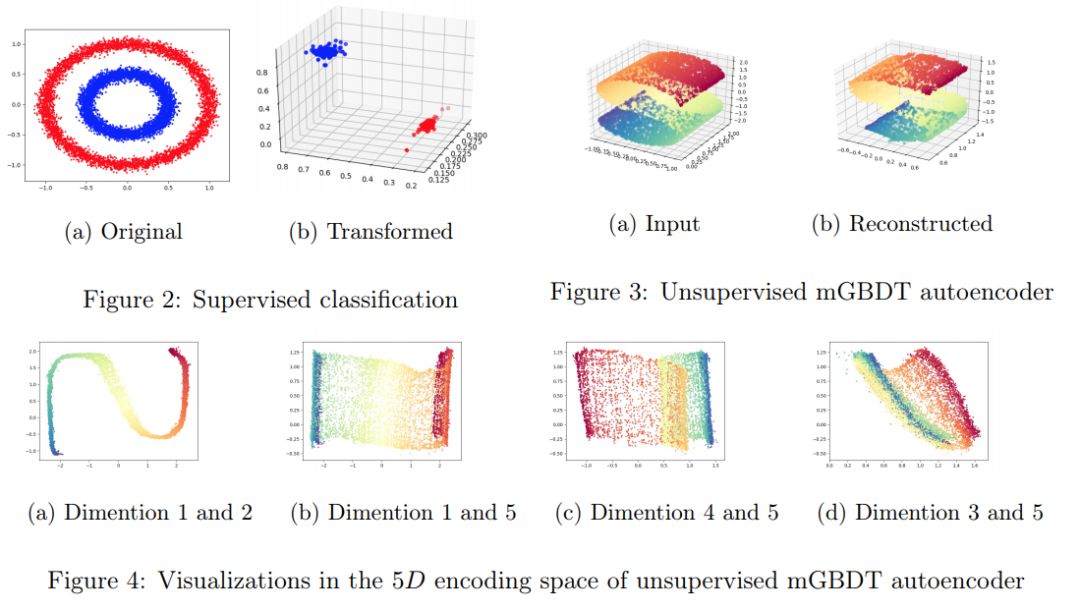
如图 2a 所示,研究者在 R^2 上得到了 1.5 万个点,分为两个类别(70% 用于训练,30% 用于测试)。用于训练的结构是(输入 − 5 − 3 − 输出),其中输入点在 R^2 中,输出是 0/1 分类预测。
研究者还进行了一项自动编码的无监督学习任务。生成了 1 万个 3D 点,如图 3a 所示。然后研究者用结构为(3 - 5 - 3)的 mGBDT 构建了一个自编码器,MSE 为重建损失。
重建输出如图 3b 所示。输入 3D 点的 5D 编码不可能直接可视化,这里研究者使用一种通用策略来可视化 2D 中 5D 编码的一些维度对,如图 4 所示。
4.2 收入预测
收入预测数据集 [28] 包含 48, 842 个样本(其中 32, 561 个是训练数据,16, 281 个是测试数据),这些样本是表格数据,具备类别属性和连续属性。每个样本包括一个人的社会背景,如种族、性别、工作种类等。这里的任务是预测这个人的年薪是否超过 50K。
图 5:收入数据集的特征可视化。
实验结果见图 6 和表 1。首先,基于同样的模型结构,多层 GBDT 森林(mGBDT)与使用反向传播或目标传播(target-prop)的 DNN 方法相比取得了最高的准确率。它的准确率还比单个 GBDT 或多个 GBDT 的简单堆叠更高。其次,与期望相反,NN^TargetProp 的收敛效果不如 NN^BackProp(与 [5] 的结果一致),而使用 GBDT 层的同样结构可以达到更低的训练损失,同时避免过拟合。
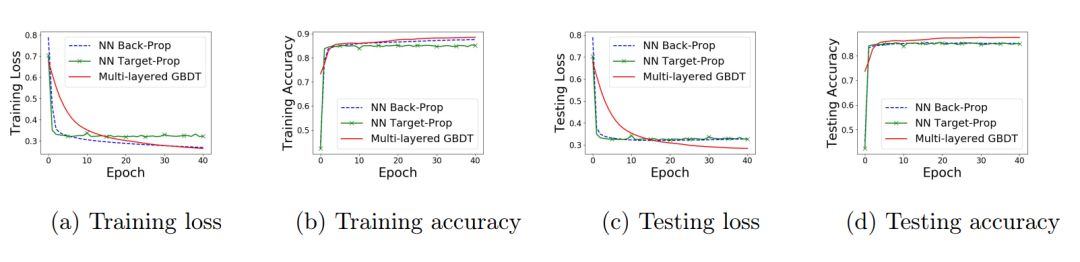
图 6:收入数据集学习曲线。
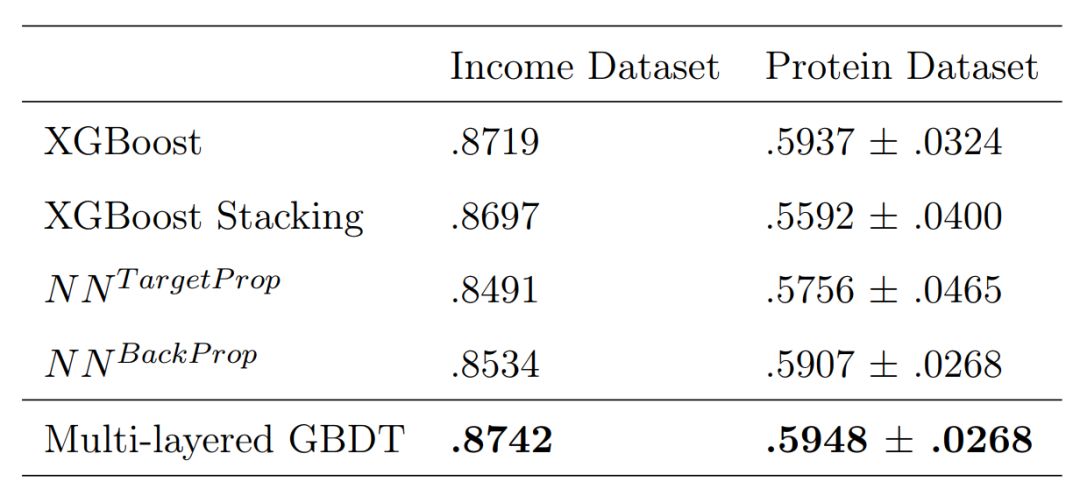
表 1:分类准确率对比。对于蛋白质数据集,使用 10 折交叉验证评估出的准确率以平均值 ± 标准差的形式表示。
4.3 蛋白质定位
蛋白质数据集 [28] 是一个 10 类别分类任务,仅包含 1484 个训练数据,其中 8 个输入属性中的每一个都是蛋白质序列的一个测量值,目标是用 10 个可能的选择预测蛋白质定位位点。
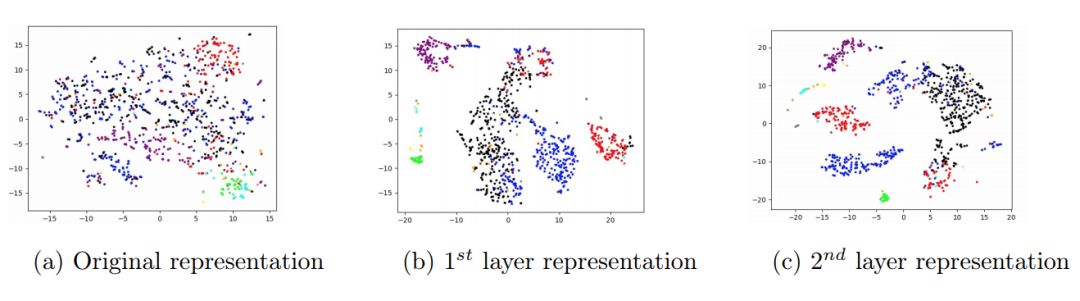
图 7:蛋白质数据集的特征可视化
10 折交叉验证的训练和测试曲线用平均值绘制在图 8 中。多层 GBDT(mGBDT)方法比神经网络方法收敛得快得多,如图 8a 所示。
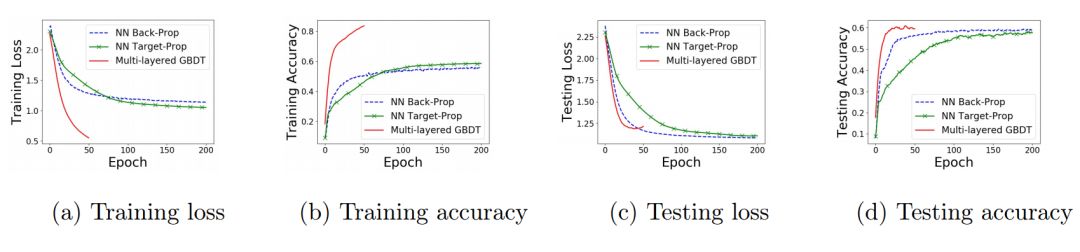
图 8:蛋白质数据集学习曲线。
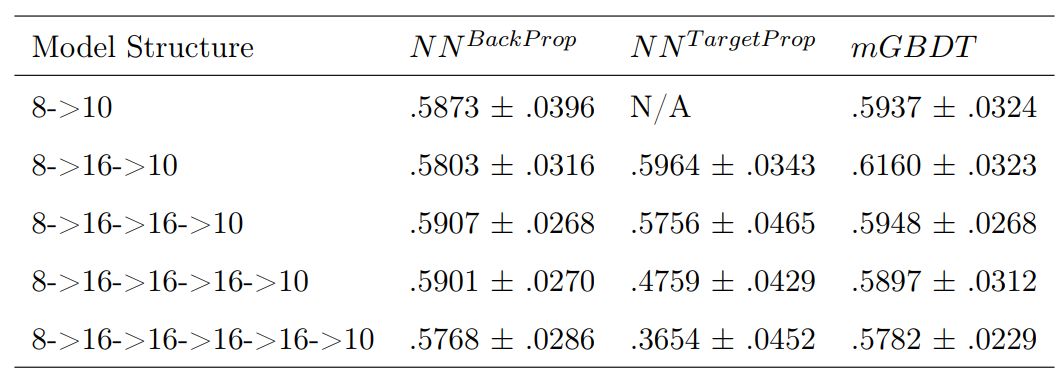
表 2:不同模型结构的测试准确率。使用 10 折交叉验证评估出的准确率以平均值 ± 标准差的形式表示。N/A 表示并未应用。
论文:Multi-Layered Gradient Boosting Decision Trees

摘要:多层表征被认为是深度神经网络的关键要素,尤其是在计算机视觉等认知任务中。尽管不可微模型如梯度提升决策树(gradient boosting decision tree,GBDT)是建模离散或表格数据的主要方法,但是它们很难整合这种表征学习能力。在本文中,我们提出了多层 GBDT 森林(mGBDT),通过堆叠多个回归 GBDT 层作为构建块,探索学习层级表征的能力。该模型可以使用层间目标传播的变体进行联合训练,无需推导反向传播和可微性。实验和可视化均证明该模型在性能和表征学习能力方面的有效性。
-
关于决策树,这些知识点不可错过2018-05-23 0
-
深度学习与数据挖掘的关系2018-07-04 0
-
决策树在机器学习的理论学习与实践2019-09-20 0
-
分类与回归方法之决策树2019-11-05 0
-
机器学习的决策树介绍2020-04-02 0
-
解析深度学习:卷积神经网络原理与视觉实践2020-06-14 0
-
ML之决策树与随机森林2020-07-08 0
-
深度神经网络是什么2021-07-12 0
-
介绍支持向量机与决策树集成等模型的应用2021-09-01 0
-
探讨一下深度学习在嵌入式设备上的应用2021-10-27 0
-
决策树的生成资料2023-09-08 0
-
基于神经网络的分布式电源在PSASP中应用2018-02-28 626
-
结合深度神经网络和决策树的完美方案2018-07-25 9103
-
深度神经决策树:深度神经网络和树模型结合的新模型2018-08-19 11939
-
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别2023-08-21 2225
全部0条评论

快来发表一下你的评论吧 !
