

Atari:AI发展史上的关键词
电子说
描述
Ted Dabney(左一)和Pong游戏机
雅达利(Atari)公司的联合创始人Ted 逝世。“雅达利”这个名字,是人工智能历史上一个不可忽视的关键词。
那个花了250美元创办Atari(雅达利)的人,Ted Dabney,上个月去世了。
Ted Dabney(全名Samuel F. "Ted" Dabney)可能没有与他一起创办雅达利的诺兰·布什内尔(Nolan Bushnell)出名,但当年风靡世界的经典游戏Pong,就是出自Ted Dabney等人之手。
Pong开创了街机视频游戏的历史,也让Atari成为一代游戏的巨人,甚至还吸引了乔布斯等人的加入。
更重要的是,Atari系列游戏不仅丰富了几代人的童年生活,在计算机史上也功不可没:DeepMind已经能够操作49款雅达利游戏,OpenAI强化学习游戏库中也包含了大量的雅达利游戏。
Atari:AI发展史上的关键词
“Atari”是AI发展史上一个不可绕过的关键词。AI达到乃至超越人类水平的领域,最开始便来自雅达利。
Ted Dabney帮助发明的Atari游戏Pong!,是被AI攻克的游戏的常客,你能在网上搜到很多构建玩Pong!的AI的教程。
2013年12月,DeepMind宣布他们研发的AI玩Atari游戏Breakout(见下)超过了人类水平,这是DeepMind取得的首个突破之一。与Pong!类似,Breakout是一款单人的乒乓游戏,也即对着墙打乒乓。在Breakout当中,人类玩家或者AI,用横板(屏幕底部的红色粗线条)左右移动接住球(中间的红点),并用这个球撞击并消除屏幕上方像素构成的“墙”,消除完毕后过关。
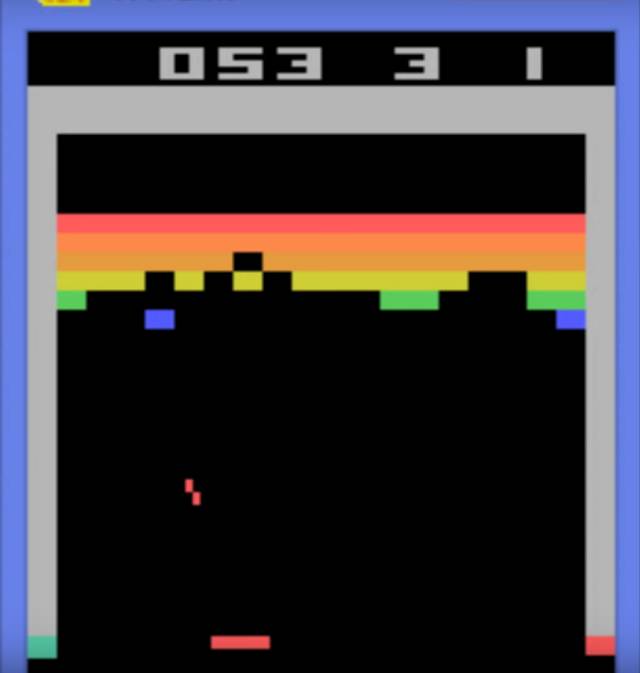
Breakout,最先被AI攻克的Atari游戏之一
Breakout的动作简单,而且能即时得到反馈,非常适于神经网络,也因此,DeepMind的AI玩Breakout的成绩,是专业人类玩家能达到的最好成绩的十倍以上。

Atari游戏,蒙特祖玛的复仇(montezuma revenge)
而其他游戏就没有那么简单。在另一款Atari游戏“蒙特祖玛的复仇”(见上)中,目标是找到埋在充满危险机关的金字塔里的宝藏。要达到目标,玩家必须达成许多个次级的小目标,例如找到打开门的钥匙。
这个游戏的反馈也不像“Breakout”那么即时,比如在一个地方找到的钥匙,也有可能打开另一个地方的门。最终找到宝藏的奖励,是之前的数千次动作的结果。这意味着网络很难将原因和结果联系起来。与玩“Breakout”的突出表现相反,神经网络目前在“蒙特祖玛的复仇”游戏中进展艰难。
DeepMind的启示:智能应该完全从经验中学习
视频游戏对 AI 的作用并非只是作为现实世界的模拟。不同的游戏需要不同的技能,这一事实有助于研究人员理解智能问题。
不过,这又带来了一个难题——神经网络只能一次玩一个游戏。例如,为了玩“Breakout”,必须要忘掉玩“Pong!”时学会的所有知识。这种遗忘是人工神经网络本身的性质,也是人工神经网络与真正的人类大脑相区别的地方。人工神经网络通过在全系统调整组成它们的虚拟神经元之间连接的强度来学习。一旦改变了要学习的任务,旧的网络连接就会逐渐被重写。
但是,进展也在发生,DeepMind 在2017年3月份发表论文,称已经解决了DNN“灾难性遗忘”的问题,DeepMind研究员让网络就像真正的人类大脑一样,能一次掌握许多个游戏。这是迁移学习——在一个上下文中使用从另一个上下文学会的行为模式的能力——这是 AI 研究中的一个热门话题。

DeepMind研究,学习两项任务过程的示意图:使用EWC算法的深层神经网络能够学习玩一个游戏,然后转移它学到的玩一个全新的游戏。
但即便掌握了迁移学习,构建可以用的人工智能仍然是一些零散的活动。研究人员真正希望得到的,是如何系统地进行这些活动的一种基本的理论。这种理论的一个候选,被称为具身认知(embodied cognition)的理论认为,智能应该完全从经验中学习,而不是试图将智能从头开始设计到一个程序里。
现实世界是最大的游戏场
DeepMind 的创始人 Demis Hassabis 认为,重要的事情是得确保虚拟机器人不会作弊。它只能使用虚拟的传感器可以收集到的信息进行导航。如果一个机器人要在“蒙特祖玛的复仇”或者“侠盗猎车手”游戏中学习度过重重危险,它必须得自己弄明白自己在游戏环境里的位置,处理当时“看到”的事情,而不能问运行游戏的计算机它在那个坐标。这是 DeepMind 教程序学习玩游戏采用的方式。
在虚拟世界里的AI可以做很多事情,虚拟机器人是没有重量的,也没有各种部件,因此不需要维护。要改变它的技术参数也不需要拆开它,敲几下键盘就可以了。它的环境也可以轻松改变。一台计算机,一次就可以运行数千个这样的模拟,让大量虚拟机器人一次又一次地尝试任务,每次尝试都是在学习。这是一种大规模的测试,而且允许学习过程被监视和理解,根本就不使用真实的机器。
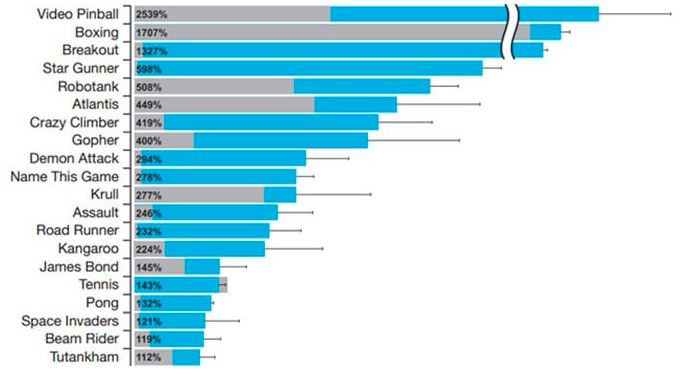
AI攻克的Atari游戏(部分,列表还在增加中……)
AI攻克的Atari游戏,以及其他视频游戏,还在不断扩展。最后,也是最重要的,视频游戏等虚拟世界,其中所发生的一切,都是现实世界的预演。
-
[讨论]提高网站关键词排名的28个SEO小技巧2010-12-01 0
-
网站定位之关键词的选取2011-04-19 0
-
LED四大关键词与四大疑问2012-08-30 0
-
请问DSP里如何确定ioport关键词定义的地址对应的引脚?2013-06-28 0
-
☑网站建设 ☑网站推广 ☑关键词优化 ☑百度地标 ☑欢迎...2014-03-15 0
-
TF-IDF测量文章的关键词相关性研究2016-01-26 0
-
2015年全球平板显示行业七大关键词2016-01-27 0
-
亚马逊代运营 amazon Search term 关键词填写的“神技”2017-06-05 0
-
HanLP关键词提取算法分析详解2018-11-05 0
-
基于Cortex-M处理器的高精度关键词识别实现2019-07-23 0
-
关键词优化有哪些实用的方法2019-08-11 0
-
百度关键词排名掉完了怎么办2021-01-27 0
-
如何在Cortex-M处理器上实现高精度关键词的识别2021-02-05 0
-
example/speech_recognition/asr样例写了一个关键词识别程序,关键词识别后播放提升音失败的原因?2023-03-10 0
-
#2023,你的 FPGA 年度关键词是什么? #2023-12-06 0
全部0条评论

快来发表一下你的评论吧 !
