

一种以50帧/秒进行端到端车道检测的方法
电子说
描述
摘要:现代汽车融合了越来越多的驾驶辅助功能,其中包括车道保持功能。该功能可以让汽车正确定位在车道线内,这对于完全自动驾驶汽车中车道偏离或轨迹规划决策有很重要的意义。传统车道检测方法依赖于高度专业的手工特征标记和后处理启发式算法的组合,这些技术计算昂贵,并且由于道路现场变化而易于扩展。最近有研究利用深度学习模型来进行像素级车道分割训练,也可以用于图像由于较大的接收范围而没有标记的情况。尽管有其优点,但这些方法仅限于检测预和定义固定数量的车道,并且不能应对车道变化。
在本文中,我们超越了上述限制,提出将车道检测问题看作一个实例分割问题(其中每个车道都形成自己的实例)可以进行端到端的训练。为了在装配车道前对分段的车道实例进行参数化,我们应用了一个以图像为条件的学习透视变换(不适用于固定的“鸟瞰”变换),这样,我们确保了一种对道路变化具有鲁棒性的车道匹配,不像现有的方法,依靠固定、预定义转换的方法。总之,我们提出了一种快速车道检测算法,运行速度为50帧/秒,可以处理不同数量的车道并应对车道变化。我们在tuSimple数据集上验证了我们的方法并获得了不错的结果。
本文作者Davy Neevn是鲁汶大学博士研究生,鲁汶大学是比利时久负盛名的最高学府,欧洲历史最悠久且最受人尊敬的大学之一,也是享誉全球的世界级顶尖研究型大学。Davy Neevn近几年一直在从事语义分割、场景理解、实例分割等课题的研究。
传统车道线检测技术
目前,无论是在学术还是工业层面,自动驾驶都是计算机视觉和机器人技术研究的主要焦点。不论何种方案,都需要使用各种传感器和控制模块,感知汽车周围的环境。基于摄像头的车道检测是环境感知的重要方法,它可以让车辆在车道内正确定位,同时它对后续的车道偏离或轨迹规划也至关重要。因此,准确的基于摄像头的车道检测是实现完全自动驾驶的关键推动因素。传统的车道检测方法(例如[9],[15],[17],[33],[35])依靠高度专业化的手工特征标记和启发式识别来识别车道线。这种手工标记的方法主要是基于颜色的特征[7],结构张量[25],条形过滤器[34],脊线特征[26]等,它们可能与霍夫变换 [23], [37]或卡尔曼滤波器[18],[8],[34] 相结合。识别车道线后,采用后处理技术来滤除误检以形成最终车道。通常,这些传统方法很容易由于道路场景变化而导致鲁棒性问题。
基于深度学习的车道线检测
最近的研究有人用深度神经网络取代手工标记,通过构建一定量学习密集的特征检测器进行预测,即像素级的车道分段。 Gopalan等人[11]使用像素级特征描述符来建模,并且使用增强算法来选择用于检测车道标记的相关特征。类似地,Kim和Lee [19]将卷积神经网络(CNN)与RANSAC算法结合起来以检测车道线。注意,在他们的方法中,CNN主要用于图像增强,并且只有道路场景复杂时才会使用。Huval等人[16]用CNN模型用于高速公路驾驶,其中包括执行车道检测和端到端CNN分类。Li等人[22]提出了使用多任务深度卷积网络,其重点在于寻找几何车道属性,如位置和方向,以及检测车道的循环神经网络(RNN)。还有人 [21] 做了更多的研究,利用深度神经网络训练如何在不利的天气和低照度条件下共同处理车道和道路标记检测和识别。上述神经网络模型除了更好地划分车道标记的能力之外[16],它们也可以在图像中标记不存在的情况下,估计车道线。然而,生成的二元分段车道仍然需要分解到不同的车道实例中。
为了解决这个问题,一些研究应用了后处理技术,这些技术依赖几何特性为指导的启发式算法。启发式方法在计算上比较昂贵,并且由于道路场景变化容易出现鲁棒性问题。
实例分割方法实现端到端车道检测
在本文中,我们超越了上述限制,提出将车道检测问题作为一个实例分割问题,其中每个车道在车道类中形成自己的实例。受密集预测网络在语义分割[24],[28],[31],[6]和实例分割任务[36],[38],[30],[2],[14]等成功的启发, [5]我们设计了一个多任务网络分支,包括一个车道分割分支和一个车道嵌入分支,可以进行端到端的训练。车道分割分支具有两个输出类别,即背景或车道,而车道嵌入分支进一步将分段的车道像素分解成不同的车道实例。通过将车道检测问题分解为上述两个任务,我们可以充分利用车道分割分支的功能,而不必为不同的车道分配不同的类别。相反,使用聚类损失函数训练的车道嵌入分支将车道ID分配给来自车道分割分支的每个像素,同时忽略背景像素。通过这样做,我们减轻了车道变化的问题,并且我们可以处理可变数量的车道。
通过估算车道实例,即哪些像素属于哪条车道,我们希望将它们中的每一个转换为参数描述。为此,曲线拟合算法被广泛用于文献中。流行的模型是三次多项式[32],[25],样条曲线[1]或布卢姆曲线[10]。为了在保持计算效率同时提高组合的质量,通常使用变换[39]将图像转换为“鸟瞰”图像并在那里执行曲线拟合。通常,变换矩阵是在单个图像上计算的,并保持固定。但是,如果地平面变化较大(例如通过倾斜上坡),则该固定变换不再有效。为了弥补这种情况,我们在对曲线进行拟合之前对图像应用透视变换,与现有的依靠固定变换矩阵进行透视变换的方法相反,我们训练一个神经网络来输出变换系数。神经网络将图像作为输入,并针对车道配合问题量身定制一个损失函数进行优化。
该方法的一个固有优点是对路面变化具有鲁棒性,并且为了更好地拟合车道而特别进行了优化。整个识别过程的概述可以在图1中看到。我们的贡献可以总结如下:(1)分支的多任务体系结构,将车道检测问题作为实例分割任务来处理,处理车道变化和允许推断任意数量的车道。特别地,车道分割分支输出密集的每像素车道段,而车道嵌入分支进一步将分段的车道像素分解成不同的车道实例。(2)给定输入图像的网络估计透视变换的参数,透视变换允许车道拟合对路面变化具有鲁棒性,例如,上坡/下坡。
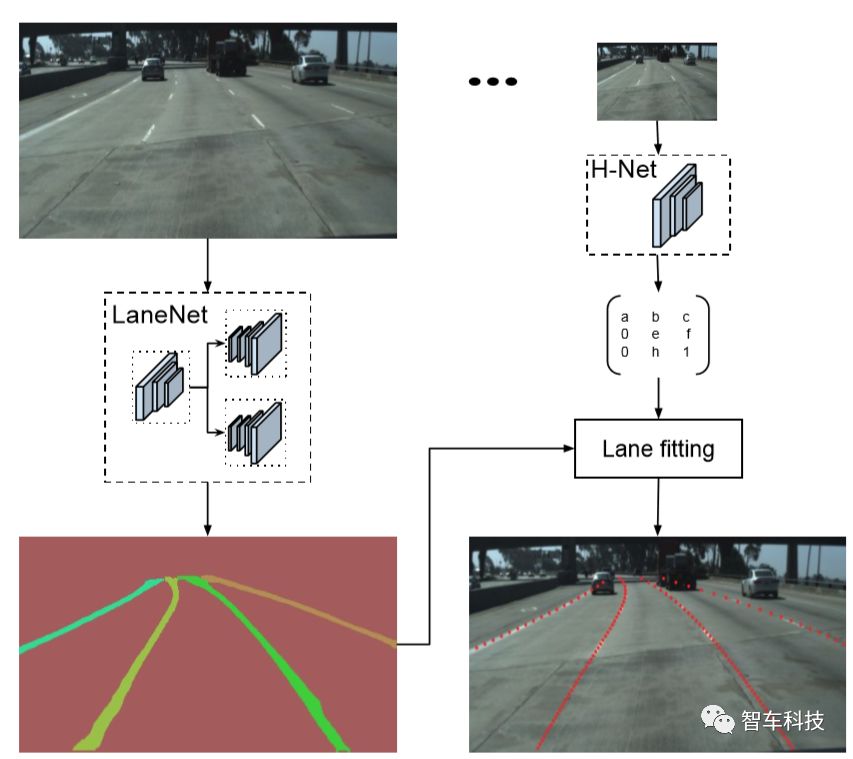
图1.系统概述。给定一个输入图像,Lane Net输出一个车道实例地图,车道ID标记每个车道像素。接下来,使用H-Net输出的变换矩阵变换车道像素,H-Net学习以输入图像为条件的透视变换。对于每一条车道,都用三阶多项式拟合,并且车道被重投影到图像上。
通过训练神经网络进行端到端的车道检测,将车道检测作为实例分割问题来实现,解决了上述车道切换以及车道数的限制的问题。我们将称之为LaneNet(参见图2)的网络,将二进制车道分割与单镜头实例分割的聚类损失函数相结合。在LaneNet的输出中,每个车道像素被分配它们对应车道的ID。因为LaneNET输出每个车道的像素集合,我们必须通过这些像素来获得车道参数化的曲线。
通常情况下,车道像素被投影成“鸟瞰图”表示,使用一个固定的转换矩阵。然而,由于变换参数对所有图像都是固定的,所以当遇到非地面时,例如在斜坡上,这会引起一些问题。为了缓解这个问题,我们训练一个网络,称为H-Network,它可以估算输入图像上的“理想”透视变换的参数。
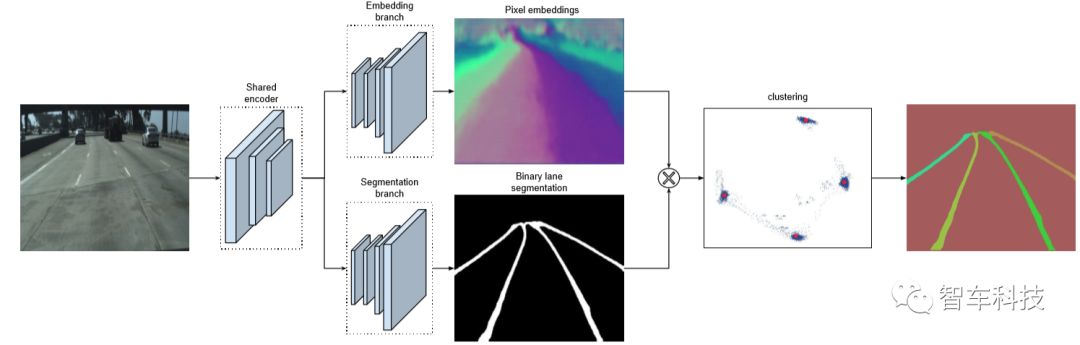
图2. LaneNet结构。分割分支(底部)被训练以产生二进制车道。嵌入分支(TOP)生成每个车道像素的n维嵌入,使得来自同一车道的嵌入是紧密的,而来自不同车道的嵌入是相距甚远的。为了简单起见,我们展示了每个像素的二维嵌入,它被可视化为XY网格中的颜色映射(所有像素)和点(仅是车道像素)。在利用分割分支的二值分割图遮蔽背景像素之后,将车道嵌入(蓝点)聚集在一起并分配给它们的聚类中心(红点)。
结论
在本文中,我们介绍了一种以50帧/秒进行端到端车道检测的方法。受到最近实例分割技术的启发,与其他相关的深度学习方法相比,我们的方法可以检测可变数量的车道并且可以应对车道变换。为了使用低阶多项式对分段车道进行参数化,我们已经训练了一个网络来生成透视变换的参数,以图像为条件,其中车道拟合是最优的。与流行的“鸟瞰视图”方法不同,我们的方法通过调整相应地参数进行变换,可以有效抵抗地平面的坡度变化。
-
一种新的判别变压器绕组同名端的检测方法2012-08-10 0
-
一种在金上生成硫醇封端的SAM的新方法2019-10-30 0
-
安捷伦使用N2X进行端到端测试2019-11-04 0
-
一种先分割后分类的两阶段同步端到端缺陷检测方法2020-07-24 0
-
一种全新的电缆在线检测方法2020-12-03 0
-
怎样去设计一种发射端和接收端调制解调器?2021-05-25 0
-
求大佬分享一种嵌入式系统中串口通信帧的同步方法2021-05-27 0
-
求一种端到端的定制IC模拟与验证解决方案2021-06-22 0
-
基于图像的车道线检测2021-07-20 0
-
一种基于图像平移的目标检测框架2021-08-31 0
-
一种常规可靠的检测多芯排线线序是否正常的方法2022-01-19 0
-
esp8266有没有一种方法可以在连接尝试时读取客户端的mac地址?2023-02-28 0
-
一种快速的公交专用车道检测方法2012-09-03 12403
全部0条评论

快来发表一下你的评论吧 !
