

自动摄影仍是未攻克的一道难题,相机能自动捕捉不平凡的瞬间吗?
描述
发布人:Clips 内容团队负责人兼研究员 Aseem Agarwala
在我看来,摄影就是在一瞬间内认识到某个事件的重要性,同时通过精准的形态组合完整记录其面貌。
- Henri Cartier-Bresson
在过去几年中,人工智能经历了一场类似寒武纪的大爆发,借助深度学习方法,计算机视觉算法已能够识别出优质照片的许多元素,包括人、微笑、宠物、日落和著名地标,等等。然而,尽管近期取得了一系列进展,自动摄影仍是未攻克的一道难题。相机能自动捕捉不平凡的瞬间吗?
前些日子,我们发布了 Google Clips,这是一款全新的免持相机,可自动捕捉生活中的有趣瞬间。我们在设计 Google Clips 时遵循了下面三个重要原则:
我们希望所有计算都在设备端执行。除了延长电池寿命和缩短延迟时间之外,设备端处理还意味着,除非保存或共享短片,否则任何短片都不会离开设备,这是一项重要的隐私控制措施。
我们希望设备能够拍摄短视频,而不是单张照片。因为动作能更好地记录瞬间的形态,留下更真实的记忆,而且,为一个重要瞬间拍摄视频往往比即时捕捉一个完美瞬间更容易。
我们希望专注于捕捉人和宠物的真实瞬间,而不是将精力放在捕捉艺术图像这种更抽象、更主观的问题上。也就是说,我们并未试图教 Clips 思考构图、色彩平衡和灯光等问题,而是专注于如何选取包含人和动物进行有趣活动的瞬间。
学习识别不平凡的瞬间
如何训练算法来识别有趣的瞬间?与大多数机器学习问题一样,我们首先从数据集入手。先设想 Clips 的各种应用场景,在此基础上创建出一个由数千个视频组成的数据集。同时,我们还确保这些数据集涵盖广泛的种族、性别和年龄群体。然后我们聘请了专业摄影师和视频剪辑师仔细检查视频,从中选出最佳的短视频片段。这些前期处理方式为我们的算法提供了可以模仿的实例。然而,仅仅依据专业人士的主观选择来训练算法并不容易,我们需要平滑的标签梯度来教会算法识别内容的质量(从"完美"到"糟糕")。
为了解决这个问题,我们采取了另一种数据收集方法,目标是为整个视频创建连续的质量得分。我们将每个视频剪辑成短片段(类似于 Clips 捕捉到的内容),然后随机选择片段对,并要求人类评分者选择他们喜欢的片段。
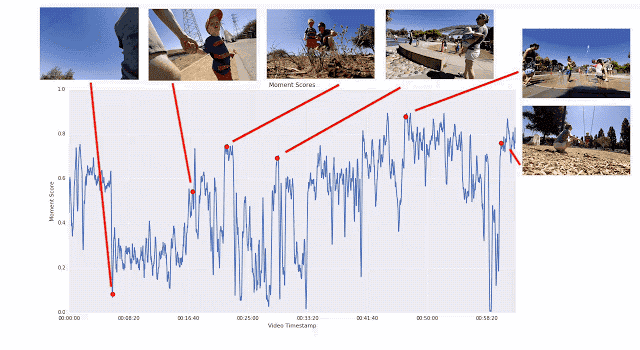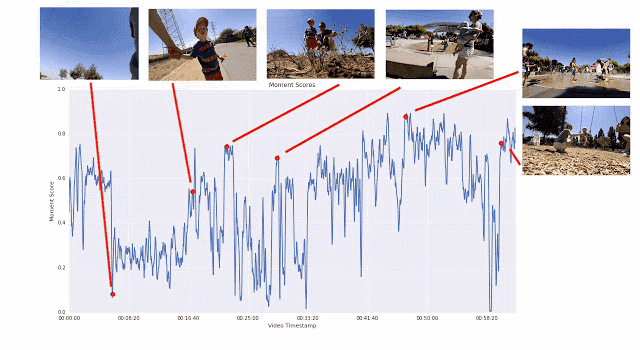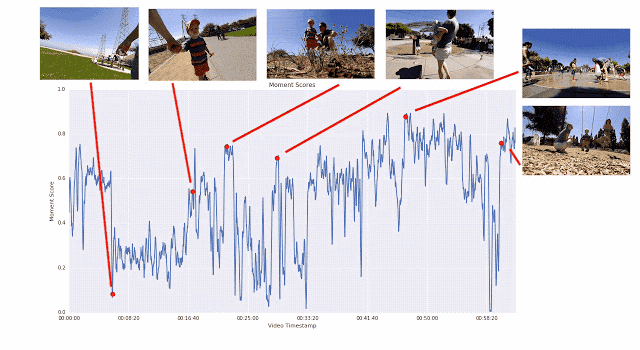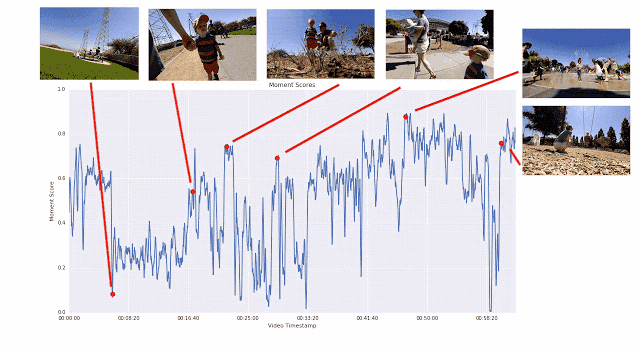
之所以采用这种成对比较的方法,而不是让评分者直接为视频打分,是因为两者择其优要比给出具体分数容易得多。我们发现评分者在成对比较时的结论非常一致,而在直接评分时则有较大分歧。如果为任意给定视频提供足够多的成对比较短片,我们就能计算整个视频的连续质量得分。通过这一过程,我们从 1000 多个视频中收集了超过 5000 万对成对比较短片。如果单纯依靠人力,这项工作将异常辛苦。
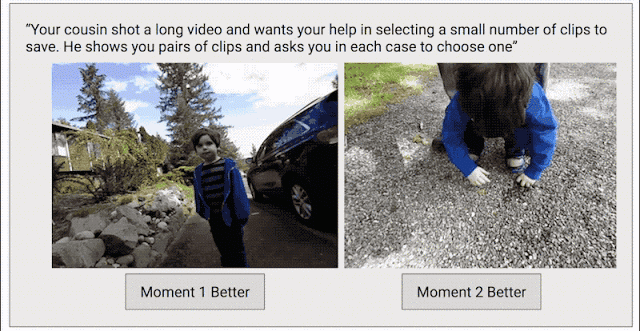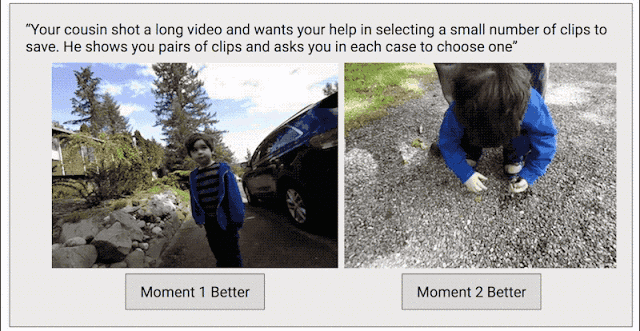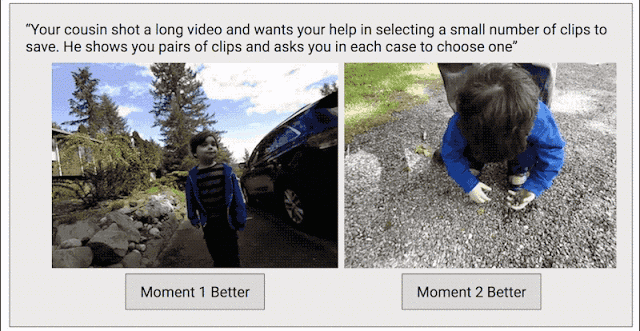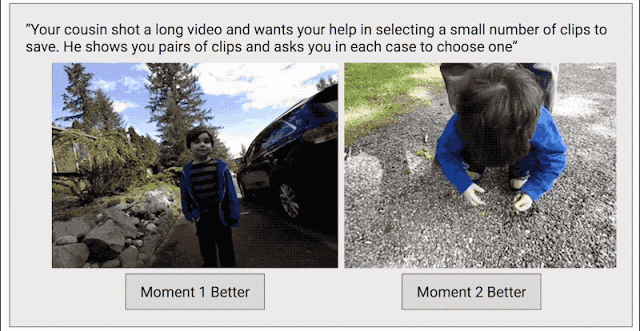
训练 Clips 质量模型
掌握质量得分训练数据后,下一步是训练一个神经网络模型来评估设备捕捉到的任意照片的质量。我们首先做了一个基本假设,即了解照片中的内容(例如人、狗和树等)有助于确定"有趣性"。如果此假设正确,那么我们可以学习一个函数,通过识别到的照片内容来预测其质量得分(如上文所述,得分基于人类的对比评估结果)。
为了确定训练数据中的内容标签,我们使用了支持 Google 图像搜索和 Google 照片的 Google 机器学习技术,这项技术可以识别超过 27000 个描述物体、概念和动作的不同标签。我们当然不需要所有标签,也无法在设备上对所有标签进行计算,因此请专业摄影师从中选择了几百个他们认为与预测照片"有趣性"最相关的标签。我们还添加了与评分者质量得分关联度最高的标签。
有了这个标签子集之后,我们需要设计一个紧凑高效的模型,在电量和发热严格受限的条件下于设备端预测任意给定图像的标签。这项工作提出了不小的难题,因为计算机视觉所依托的深度学习技术通常需要强大的桌面 GPU,并且移动设备上运行的算法远远落后于桌面设备或云端的最新技术。为了在设备端模型上进行此项训练,我们首先收集了大量照片,然后再次使用 Google 基于服务器的强大识别模型来预测上述每个"有趣"标签的置信度。我们随后训练了一个 MobileNet 图像内容模型 (ICM) 来模仿基于服务器的模型的预测。这个紧凑模型能够识别照片中最有趣的元素,同时忽略不相关的内容。
最后一步是使用 5000 万成对比较短片作为训练数据,利用 ICM 预测的照片内容预测输入照片的质量得分。得分通过逐段线性回归模型进行计算,将 ICM 输出转换为帧质量得分。视频片段中的帧质量得分取平均值即为瞬间得分。给定一组成对比较短片,我们模型计算出的人类偏好的视频片段的瞬间得分应当更高一些。训练模型的目的是使其预测结果尽可能与人类的成对比较结果一致。
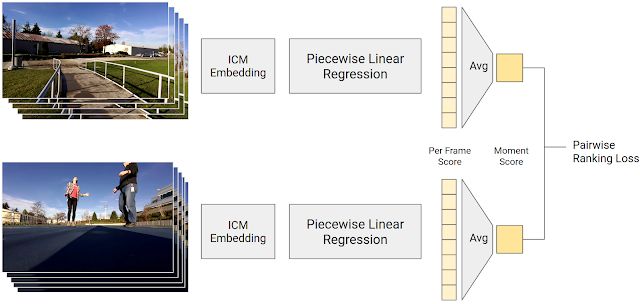
生成帧质量得分的训练过程图示。逐段线性回归模型将 ICM 嵌入映射为帧质量得分,视频片段中的所有帧质量得分取平均值即为瞬间得分。人类偏好的视频片段的瞬间得分应当更高。
通过此过程,我们训练出一个将 Google 图像识别技术与人类评分者智慧(5000 万条关于内容有趣性的评估意见)完美融合的模型。
这种基于数据的得分在识别有趣(和无趣)瞬间方面已经做得很好,我们在此基础上又做了一些补充,针对我们希望 Clips 捕捉的事件的整体质量得分增加了一些奖励,这些事件包括脸部(特别是因经常出现而比较"熟悉"的脸部)、微笑和宠物。在最新版本中,我们为客户特别想捕捉的某些活动(如拥抱、亲吻、跳跃和跳舞)增加了奖励。要识别到这些活动,需要扩展 ICM 模型。
拍照控制
基于这款强大的场景"有趣性"预测模型,Clips 相机可以决定哪些瞬间需要实时捕捉。它的拍照控制算法遵循以下三大原则:
重视耗电量和发热:我们希望 Clips 的电池能够续航大约三小时,同时不想设备过热,因此设备不能一直全速运转。Clips 大部分时间都处于每秒拍摄一帧的低电耗模式。如果这一帧的质量超出根据 Clips 最近拍摄量所设置的阈值,它将进入高电耗模式,以 15 fps 的速度进行拍摄。Clips 随后会在遇到第一次质量高峰时保存短片。
避免冗余:我们不希望 Clips 一次捕捉所有瞬间,而忽略了其他内容。因此,我们的算法将这些瞬间聚合成视觉相似的组,并限制每一集群中短片的数量。
后见之明的好处:查看拍摄的所有短片之后再选择最佳短片显然要简单得多。因此,Clips 捕捉的瞬间要比预期展示给用户的多。当短片要传输到手机时,Clips 设备会花一秒时间查看其拍摄成果,只把最好和最不冗余的内容传输过去。
机器学习的公平性
除了确保视频数据集展现人口群体多样性之外,我们还构建了多项测试来评估我们算法的公平性。我们通过从不同性别和肤色中均匀采样,同时保持内容类型、时长和环境条件等变量恒定,来创建可控的数据集。然后,我们使用此数据集测试算法在应用到其他群体时是否具备类似性能。为了帮助检测提升瞬间质量模型时可能发生的任何公平性回归,我们为自动系统增加了公平性测试。对软件进行的任何变更都要进行这些测试,并且要求必须通过。但需要注意的是,由于我们无法针对每一个可能的场景和结果进行测试,因此,这种方法并不能确保公平性。但实现机器学习算法的公平性毕竟任重而道远,无法一蹴而就,而这些测试将有助于促进目标的最终实现。
结论
大多数机器学习算法都是围绕客观特性评估而设计,例如,判断照片中是否有猫咪。在我们的用例中,我们的目标是捕捉一个更难捉摸、更主观的特性,即判断个人照片是否有趣。因此,我们将照片的客观、语义内容与主观人类偏好相结合,在 Google Clips 中实现了人工智能。此外,Clips 的设计目标是与人协同,而不是自主工作;为了获得良好的拍摄效果,拍摄人仍要具备取景意识并确保相机对准有趣的拍摄内容。我们对 Google Clips 的出色表现感到欣慰,期待继续改进算法来捕捉"完美"瞬间!
致谢
本文介绍的算法由众多 Google 工程师、研究员和其他人共同构想并实现。图片由 Lior Shapira 制作。同时感谢 Lior 和 Juston Payne 提供视频内容。
-
[转帖]纪念不平凡的2008,超印速免费为您印制10本博客书2008-12-03 0
-
[分享]纪念不平凡的2008,超印速免费为您印制10本博客书2008-12-03 0
-
[原创]纪念不平凡的2008,超印速免费为您印制10本博客书2008-12-19 0
-
游标自动捕捉问题2016-06-28 0
-
SuperEye一款内置CPU的相机--mangotree出品2018-03-31 0
-
解决延时摄影系统难题带来全商市场商机2018-09-11 0
-
那位高人可以指点一下,labview如何实现像cad一样的图形元素自动捕捉,线/圆等图元自动捕捉。2019-05-15 0
-
自动对焦在智能手机的应用2019-07-16 0
-
智能家居解决各平台互联互通仍是一个难题2021-05-21 0
-
LED面临哪些技术上的难题?如何去攻克?2021-06-03 0
-
业余摄影师巧捉鹭鸶捕捉地鼠精彩瞬间2010-03-31 601
-
尼康D7200相机拥有2416万的有效像素,能瞬间捕捉被摄物体留住感动瞬间2018-09-18 2409
-
自动驾驶芯片赛道的玩家众多 已形成百舸争流之势2019-11-20 394
-
自动驾驶尚余1%的难题无法攻克?英伟达:必须建超算中心2022-11-18 626
全部0条评论

快来发表一下你的评论吧 !
