

Apollo一路走来,正在走出高成本的科研范畴迈向实用领域
描述
百度Apollo目前历经四代,分别是Apollo1.0、1.5、2.0、2.5。




Apollo一路走来,正在走出高成本的科研范畴,迈向实用领域。在Apollo1.5版上,激光雷达是最核心的,不仅完成传统的局部导航,还完成通常由摄像头完成的障碍物识别。2.0版上,增加交通信号灯检测和障碍物分类。RTK与激光雷达点云融合定位,MPC模型预测法做控制算法,RNN做交通场景预测。Apollo重点模块集中在障碍物感知、预测、高精度定位、路径规划、控制的工作。
这样一辆车,总成本100多万人民币(含改装成本),显然只能做科研,即使做共享出行,成本都太高了。
2.5版上,Apollo有了重大改变,从高成本科研阶段进入实用化的阶段,从以前的低速园区应用,演进到低成本方案的高速公路应用。在Github上Apollo2.5是这样说的 Vehicles with this version can drive autonomously on highways at higher speed with limited HD map support. The highway needs to have clear white painted lane marks with minimum curvatures. The performance of vision based perception will degrade significantly at night or with strong light flares.Be cautious when driving autonomously, Especially at night or in poor vision environment. Please test Apollo 2.5 with the support from Apollo engineering team. 在高精度地图支持下,车辆可以在高速公路上以较高的速度自动驾驶,高速公路应该车道线清晰,曲率不高。在强烈阳光和低照度下请谨慎,请在Apollo工程团队的支持下测试Apollo2.5。
和原来数十万元的系统成本相比,Apollo2.5仅用一个广角摄像头和一个毫米波雷达就完成了高速公路自动驾驶,总体成本下降了90%,已经具备量产条件。
Apollo2.5的基础是百度的低成本“相对地图”,这种地图和凯迪拉克超级巡航上的激光雷达地图类似。

由USHR为凯迪拉克制作的激光雷达地图专为高速公路无人驾驶设计,地图的内容包括车道数量、车道宽度、水平宽度、速度上限、速度下限、海拔高度、顺坡斜率、边坡斜率、航向角、水平曲率半径等,精度为10厘米。在凯迪拉克超级巡航里包括6自由度的MEMS IMU,使用天宝的RTX服务和一台天宝的单频双星(GPS/GLONASS)接收机,使用4G通讯来矫正定位,包括精确卫星时钟,轨道和电离层信息,定位精度可达1.8米。
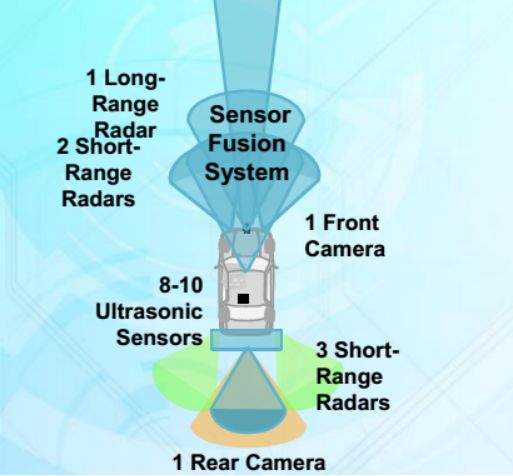
凯迪拉克使用6个毫米波雷达,包括1个长距超声波雷达,可能是德国大陆汽车的ARS-410,5个短距离毫米波雷达,可能是大陆的SRR520。前后两个摄像头也由大陆提供,8-10个超声波雷达,当然车内还有一个驾驶者状态监控摄像头。图中未标出360环视系统,实际上凯迪拉克超级巡航也有360环视系统。这套系统远优于特斯拉的Autopilot 2.5辅助驾驶系统。
中国的高速公路路况不同于美国,中国的高速公路有三大杀手,一是大货车,二是无视交通法规的司机,三是豪车飙车。对这三大杀手,必须做出对应,这就是场景决策或者说行为决策。大货车由于国情因素,超载是不可避免的,不超载就会亏本。超载情况下,刹车性能大幅度下降,加上大货车都是气刹,反应速度远低于小型车的液压刹车,此外大货车在高速上方向打的稍微急一点就可能翻车,会压垮临近车道的车。所以高速上尽量不跟大货车,尽量不与大货车平行。然而高速上也忌讳随意变道,或者见大车就超。需要在两者之间做一个平衡,找一个最优策略。
有些司机,在高速逆行或倒车,如果按照一般无人车的原则是遇到障碍物就减速,而面对逆行或倒车,减速不是最优策略,换道才是,不过也要看是否具备换道条件。最后是那些不在意超速罚款的豪车,四处穿插变道,任意超出,无人车要尽量远离这些车辆。
如何让无人车面对这些场景时做出最优选择?
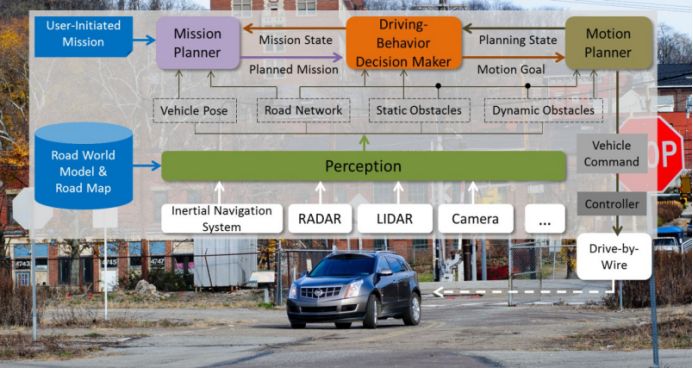
行为决策,第一种方法为人为编程法(Manual Programing),包括FSM(Finite State Machines)有限状态机、行为树、目标导向、效用系统、Rule Based、HSM(Hierarachical State Machines)层次状态机。
FSM有限状态机,这是目前AI游戏界最常用的方法,也是小公司无人驾驶最常用的,简单高效,最大的优点是可视化,缺点是无法对应太多的场景,一般不超过10个,在高速上场景比较简单,尚可使用,低速市区则完全不能用。
第二种是Optimisation最优法,包括CCO(Chance Control Optiminsation)。
第三种是Graph 搜索法,包括A+法(宝马),RRTS(快速扩展随机树法)。
第四种Model Predictive Control (MPC)法,例如Interactive Multi Model-Extended Kalman Filter (IMM-EKF)。
第五种Partially Observable Markov Decision Process (POMDP),部分可观察马尔科夫决策过程法,降低对传感器的依赖性。
Waymo使用POMDP来做行为决策,Waymo的 behavior prediction team由Stephane Ross领导,主要用POMDP来预测行人、车辆和骑自行车者的未来行为。预测行为与行为决策是联为一体的。
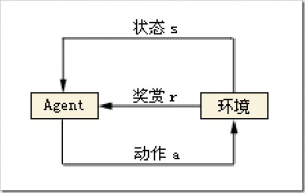
这实际上一种强化学习。深度学习算法一般可分为三大类,即非监督学习(unsupervised learning)、监督学习(supervised leaning)和强化学习。根据Agent当前状态,选择了动作a,这时与环境发生了交互,Agent观测到下一个状态,并收到了一定的奖赏r(有好有坏)。如此反复的与环境进行交互,在一定条件下,Agent会学习到一个最优/次优的策略。这实际上就是个马尔科夫决策过程(MDP),也就是阿尔法狗背后的算法。
而无人车的决策都来自传感器得到的信息,这些信息都不能完整地描述环境,只是环境的一部分,因此需要使用POMDP,即部分观察马尔科夫决策过程。强化学习过程可以使用一个马氏决策过程(M arkov decision process,MDP)表示,MDP由四元组
如果Agent在学习过程中,无需学习MDP的模型知识,直接学习最优策略, 我们称这类方法为模型无关(Model free) ;如果在学习过程中,先学习MDP的模型知识,然后再根据这些推导、学习出最优策略,我们称之为模型有关( Model based)。其中前者是研究的重点,因为在实际中主要遇到的问题。是如何在模型不知的情况下学习到最优策略。前者的算法主要有TD(λ), Q—learning 算法,后者主要有Dyna、Prioritized Sweeping、Sarsa 算法等。
无人车的POMDP一般包括状态建模、行为建模、观察建模、转移函数建模、收益建模。状态建模包括行人、车辆、骑车人可能的行为目标点,映射到POMDP模型的七元组的S。将汽车的行为,恒速、加速、减速、左转、右转组合为多种行为。将车辆位置、速度和周围移动目标的位置集合映射到POMDP模型的七元组的Z。汽车的收益建模包括安全、舒适、高效三个目标。
为了加快测试过程,百度开发了强大的仿真系统。在Apollo 中,对仿真平台的定位是不仅仅是真实,而是要能够进一步:能够发现无人车算法中的问题。因为在整个算法迭代闭环中,光有拟真是不够的,还需要能够发掘问题,发现了问题后才能去解决问题,也就是回到了开发过程。如此这样,从开发到仿真再回到开发,仿真平台同我们的开发过程串联成一个闭环。只有闭环的东西才能构成持续迭代和持续优化状态。所以仿真平台在整个无人车算法迭代中的地位非常重要。
Apollo 仿真器的静态世界的表达,正是直接使用了 Apollo 相对地图数据。所以它是真实的,且是具有足够低成本的。
相对低速场景,高速公路场景要简单的多,更容易实现低成本可量产的无人驾驶。未来国内第一辆量产的L4无人车,很有可能是百度Apollo与中国本土车企打造的。
-
4-20mA一路转多路信号隔离放大低成本、小体积解决方案2010-02-22 0
-
电子竞赛,一路走来2012-02-24 0
-
一路信号反相的问题2013-07-05 0
-
怎样从一路正弦多普勒信号中得到另一路的余弦多普勒信...2013-11-22 0
-
一路继电器2015-01-20 0
-
LED驱动电路双路输出时,如何解决一路带载,另外一路空载飘的问题?2017-03-28 0
-
“一路带一路”为什么门槛如此之高!!!2017-06-19 0
-
duplink分出两路(A,B)一路用于显示,另一路图像分析。但不做图像分析所耗的延迟会在显示那一路上体现出来是为什么?2014-12-17 0
-
DM368能否配置,同时输出两路视频信号[一路LCD,一路CVBS] ?2018-05-28 0
-
功能模式一路切 2 路、A 路切 B 路LED恒流驱动器2019-04-29 0
-
如何使用STM32输出一路PWM波形?2021-11-19 0
-
隔离电源两路+15V,把其中一路反着接变-15V,可以与另外一路供地吗?2022-09-03 0
-
交错并联LLC反向运行一路驱动信号被另一路拉低2023-11-02 0
-
使用AD9643的其中一路,另一路空余,模拟输入该如何连接?2023-12-07 0
-
碳基芯片正在阔步走来2020-11-05 4617
全部0条评论

快来发表一下你的评论吧 !
