

神经网络是在许多用例中提供了精确状态的机器学习算法
电子说
描述
神经网络是在许多用例中提供了精确状态的机器学习算法。但是,很多时候,我们正在构建的网络的准确性可能并不令人满意,也可能不会让我们在数据科学竞赛中处于领先地位。因此,我们一直在寻找更好的方法来提高我们的模型的性能。有很多技术可以帮助我们实现这一点。
检查过度拟合
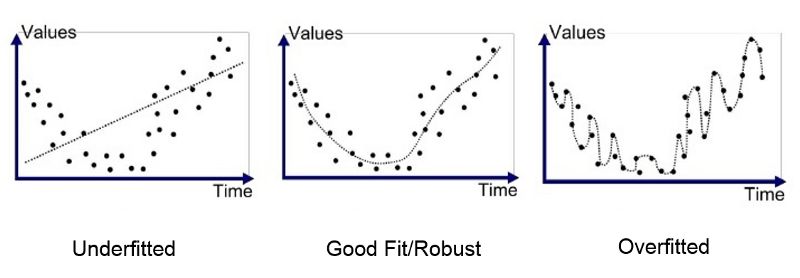
确保你的神经网络在测试数据上表现良好的第一步是验证你的神经网络不会过度拟合。什么是过度拟和?当模型开始从训练数据中记忆数值而不是从训练数据中学习时,就会发生过拟合。因此,当您的模型遇到以前从未见过的数据时,它不能很好地执行它们。
为了让你更好的理解,让我们来打个比方。我们都会有一个善于记忆的同学,假设数学考试即将来临。你和你擅长记忆的朋友从课本上开始学习。你的朋友决定背诵课本上的每个公式、问题和答案,但你比他聪明,所以你决定建立在直觉的基础上,解决问题,学习这些公式是如何发挥作用的。测试一天到来,如果试卷的问题是采取直接从课本,那么你的朋友会做得更好,但如果问题涉及新的应用知识,你会做得更好,而你依赖记忆的朋友会失败得很惨。
如何鉴别你的模型是否过度拟和?你只需要交叉检验训练准确度和测试准确度如果训练准确度远远高于测试准确度,那么你就可以假设你的模型过度拟和了。你也可以将预测点画在图表上来验证。以下是一些防止过度拟和的技术:
数据规范化(L1或L2)。
退出——在神经元之间随机删除连接,迫使网络找到新的路径并进行归纳。
早期停止——加速神经网络的训练,减少测试集的误差。
超参数调优
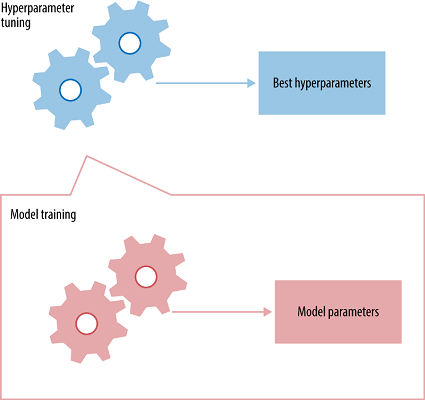
超参数是必须初始化到网络的值,这些值是神经网络在训练时无法学习到的。例如:在卷积神经网络中,一些超参数是内核大小、神经网络中的层数、激活函数、丢失函数、使用的优化器(梯度下降、RMSprop)、批处理大小、要训练的周期数等。
每一个神经网络都将有其最好的超参数集,以达到致最大的准确性。你可能会问,“有这么多超参数,我如何选择?”不幸的是,没有直接的方法来辨别出每一个神经网络的最佳超参数集,所以它主要是通过反复试验得到的。但是,对于下面提到的超参数有一些实践技巧:
学习速率
选择一个最优的学习速率很重要,因为它决定了你的网络是否收敛到全局最小值。选择一个高学习率几乎不会让你达到全局最优,因为你很有可能超过它。因此,你总是在全局最小点附近,但从不收敛于它。选择一个低的学习速率可以帮助神经网络收敛到全局最小值,但是需要花费大量的时间。因此,你必须对网络进行长时间的训练。一个低的学习速率也会使网络容易陷入局部最小值,例如,网络会收敛到局部最小值,由于学习速率小,无法从中挣脱出来。因此,在设置学习率时必须小心。
网络架构
在所有的测试用例中,没有一个永远带来高准确性的标准的体系结构。你必须进行实验,尝试不同的架构,从结果中获得推断,然后再尝试。我的一个建议是使用经过验证的架构,而不是构建自己的架构。例如:对于图像识别任务,你可以使用VGG net, Resnet,谷歌的Inception network等。这些都是开源的,并且已经被证明非常准确,因此,你可以复制他们的架构并根据你的目的调整它们。
优化器和损失函数
有无数可供选择的选项。事实上,你甚至可以在必要时定义自定义损失函数。常用的优化方法有RMSprop、 Stochastic Gradient Descent和Adam。这些优化器似乎适用于大多数用例。如果你的用例是一个分类任务,那么通常使用的损失函数是分类交叉熵。如果您正在执行一个回归任务,均方误差是常用的损失函数。可以自由地尝试这些优化器的超参数,也可以使用不同的优化器和损失函数。
批处理大小和epoch的数量
同样,对于所有用例来说,没有标准的批处理大小和epoch数量。你必须尝试不同的方法。在一般的实践中,批量大小的值设置为8、16、32,而epoch的数量取决于开发人员的偏好和他拥有的计算能力。
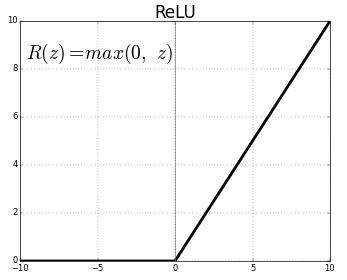
激活函数——激活函数将非线性函数的输入映射到输出。激活函数非常重要,且选择正确的激活函数有助于你的模型更好地学习。如今,纠正线性单元(ReLU)是使用最广泛的激活函数,因为它解决了梯度消失的问题。早些时候S状弯曲和双曲正切是使用最广泛的激活函数。但是,他们遭受了梯度消失的问题,例如:梯度反向传播的过程中,当他们到达开始层时梯度的数值就开始减少。这阻止了神经网络扩展到更大的规模与更多的层。ReLU能够克服这个问题,从而使神经网络能有更大的规模。
整体算法
如果单个神经网络并不像你预期中那么准确,你可以创建一个神经网络的集合并结合它们的预测能力。你可以选择不同的神经网络架构,在数据的不同部分对它们进行训练,并对它们进行集成,使用它们的集体预测能力来获得测试数据的高准确度。假设,你正在构建一个猫与狗的分类器,0表示猫,1表示狗。当将不同的猫和狗的分类器组合在一起时,基于各个分类器之间的皮尔逊相关性,集成算法的精度得到了提高。让我们来看一个例子,取3个模型并测量它们各自的准确性:
Ground Truth: 1111111111Classifier 1: 1111111100 = 80% accuracyClassifier 2: 1111111100 = 80% accuracyClassifier 3: 1011111100 = 70% accuracy
三种模型的皮尔逊相关系数很高。因此,组合它们并不能提高准确性。如果我们使用多数投票对上述三个模型进行组合,我们将得到以下结果:
Ensemble Result: 1111111100 = 80% accuracy
现在让我们来看看皮尔逊相关系数很低的3个模型:
Ground Truth: 1111111111Classifier 1: 1111111100 = 80% accuracyClassifier 2: 0111011101 = 70% accuracyClassifier 3: 1000101111 = 60% accuracy
当我们把这三个模型合在一起时,我们得到了以下的结果:
Ensemble Result: 1111111101 = 90% accuracy
由此可见,低皮尔逊相关系数的模型组合能够得出比高皮尔逊相关系数组合更精确的结果。
数据不足的问题
在执行上述所有技巧之后,如果你的模型在测试数据集中仍然没有表现得更好,那么可以将其归因于缺少训练数据。在许多用例中,可用的培训数据的数量是有限的。如果你无法收集更多的数据,那么可以使用数据增强技术。

如果你正在处理一个图像数据集,您可以通过剪切图像、翻转图像、随机剪切图像等方式来增加训练数据的新图像。这可以为神经网络提供不同的示例。
-
神经网络教程(李亚非)2012-03-20 0
-
神经网络50例2012-11-28 0
-
分享机器学习卷积神经网络的工作流程和相关操作2019-02-14 0
-
神经网络资料2019-05-16 0
-
机器学习神经网络参数的代价函数2019-05-22 0
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 0
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 0
-
如何设计BP神经网络图像压缩算法?2019-08-08 0
-
神经网络和反向传播算法2019-09-12 0
-
反馈神经网络算法是什么2020-04-28 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
卷积神经网络简介:什么是机器学习?2023-02-23 0
-
不可错过!人工神经网络算法、PID算法、Python人工智能学习等资料包分享(附源代码)2023-09-13 0
-
BP神经网络模型与学习算法2017-09-08 937
-
卷积神经网络算法是机器算法吗2023-08-21 522
全部0条评论

快来发表一下你的评论吧 !
