

关于基于动态连续数据的GPU调试系统的设计和实现
描述
0 引言
随着GPU技术的发展,GPU结构变得越来越复杂,对硬件的调试成为一个越来越困难的任务。硬件调试的困难在于硬件本身的不透明性。在发生问题的时候,工程师没有办法像软件调试那样,看到硬件内部发生了什么,也不能像软件调试那样,半路设一个断点,把硬件停下来。
为方便对硬件的调试,GPU设计人员开发出很多种硬件调试方法来降低硬件调试的难度,传统上有DebugBus、扫描路径法、ARM CoreSightTM技术。这些方法的目的都是用某种方法将硬件内部信息暴露给工程师,降低硬件的不透明性,但其暴露出的信息都是硬件内部某个时间点的静态信息,对硬件工程师的帮助是有限的。
本文提出一种新的调试架构,相对于传统技术,它能够提供一段时间内的动态数据给工程师,让工程师能够了解在这段时间内硬件内部状况是如何变化的,使得工程师能迅速定位到造成问题的异常变化。甚至更进一步,工程师可以将得到的信息导入模拟环境,在模拟环境里面重现硬件的问题。
1 传统硬件调试方式及其缺陷
1.1 DebugBus
DebugBus技术是最早在芯片设计中引进的调试技术[1-2]。其基本原理是在硬件设计中添加一批状态寄存器,每个模块都把自己的状态编码后送到这个状态寄存器中。当发生问题的时候,工程师读取状态寄存器中的状态码,从而可以分析问题发生的原因。
DebugBus技术缺陷在于,状态寄存器的位是有限的,所以能反映模块的状态也是有限的,工程师通过状态码只能大概了解模块的真实情况。
1.2 基于扫描路径法的可测性设计技术
基于扫描路径法的可测性设计技术是可测性设计(DFT)技术的一个重要方法[3-5],这种方法能够从芯片外部设定电路中各个触发器的状态,并通过简单的扫描链设计,扫描观测触发器是否工作在正常状态,以此来检测电路的正确性。
这种技术的缺陷在于它速度太慢,因为它是一个串行的操作,不能一次读出全部数据,导致工程师不能得到一个即时的数据[6]。
1.3 ARM CoreSightTM技术
CoreSightTM技术是ARM公司在2004年推出的一个新的调试体系架构,以提供更为强大的调试能力[7]。
CoreSightTM技术比较适合于软件调试,因为它提供给工程师的是模块之间的指令和寄存器传递序列,软件工程师可以知道自己送给硬件的命令是如何在硬件各个模块之间传递。但硬件开发工程师更多的是想了解模块和模块之间完整的会话信息,甚至是模块内部的一些信号[8-9]。
2 新调试系统硬件部分
对于硬件开发工程师来说,要调试硬件问题需要得到大量硬件内部模块和模块之间的会话信息,这些信息最好是某个时间段内连续的信息,而不是简单的某个时间点的信息。
但是要把所有这些信息收集给调试人员,就需要解决两个问题:
第一,每个时钟周期产生的信息是大量的,为了不影响后面的时序,必须在一个时钟周期内处理完。但硬件带宽的限制又决定了这些不可能在一个周期内处理完。这也是过去技术上只能提供简略信息的主要原因。
第二,由于每个时钟周期都产生大量的信息,因此我们要处理的整体信息量非常巨大,导致这些信息的存储就是一个问题。
为了解决这些问题,设计了一个双时钟系统。当我们发现需要存储信息的时候,我们就把全局时钟停止,从而使得各个模块停止工作。同时我们用另外一套时钟系统驱动调试模块收集和压缩信息。当信息收集完成以后,就把相关的数据发送到存储模块去存储。当存储完成时候,再重新激活全局时钟,让各个模块继续工作。
由于采用了双时钟系统,提供了足够的时间来进行信息的收集和存储。因此在存储媒介上,我们放弃了价格昂贵但容量偏小的闪存,而是选择了从板载内存中分配一块较大的区间,这样就能在成本范围内提供能够存放足够多信息的存储空间。
根据以上设计,我们把新的调试系统分成了5个模块。
2.1 会话取样模块
会话取样模块负责将模块和模块之间的会话传给会话监控模块或者会话记录模块。假设我们有两个模块A和B,一般情况下,模块A和模块B之间通过接口C连接,互相传递信息,如图1所示。

将会话取样模块放在接口C上,通过它来检查模块A和模块B之间是否有会话,如果有会话发生,那么就把会话内容传给会话存储模块,并由会话存储模块将内容整理存储到存储媒介上,如图2所示。

2.2 会话监控模块
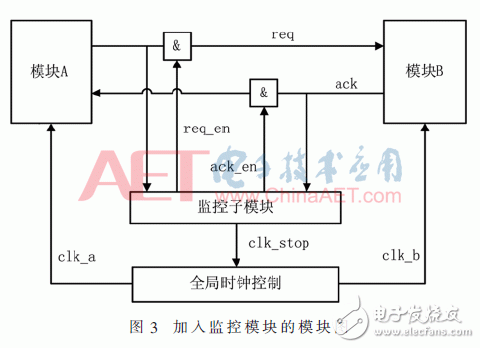
会话监控模块负责监控模块之间的会话,一旦它发现模块A和模块B之间发生了会话,那么会话监控模块就会通知全局时钟控制模块,把所有模块的时钟中止,如图3所示。
2.3 会话记录模块
会话记录模块负责在全局时钟停止时,将会话的内容记录到内存中。我们没有采用传统上的内部Cache的模式,因为虽然内存中记录比较慢,但是可以提供极大的记录空间,可以记录相当长时间的会话。只要内存足够大,就可以记录足够长的会话。
会话记录模块会把会话记录循环写入对于软件分配给硬件的内存,同时它提供两个寄存器给软件用于判断是否有信息写入。一个寄存器表示内存中未处理信息的头部,一个寄存器表示内存中未处理信息的尾部。会话记录模块在写入信息前,会检查未处理信息的尾部是否和未处理信息头部重合,如果是,说明内存中信息已经满了,那么记录模块会停下等待软件把信息读走。
由于各个模块之间会话大小不同,因此在存储的数据结构上,我们没有采取固定长度的数据结构,而是设计了一种变长的数据结构。它分为头部和数据两块。头部是一个固定结构,表面数据包的信息,而其后跟随着一个变长的数据流。它包含了三部分信息:
(1)模块ID:记录了信息来自哪个模块。
(2)数据长度:会话信息的大小。
(3)时间戳:会话发生的时间,可以用于仿真模型。
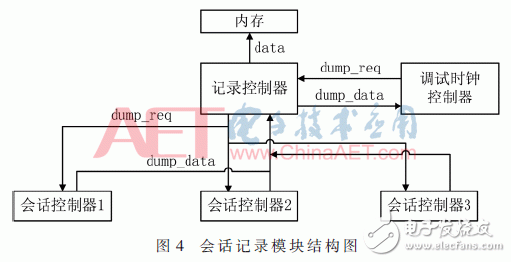
在实际应用中,内存控制器只有一个输入,为了协调各个模块的写入顺序,我们专门设计了一个记录控制器,用来接收各个会话记录模块的输出,并转送到内存控制器中,如图4所示。
2.4 全局时钟控制器
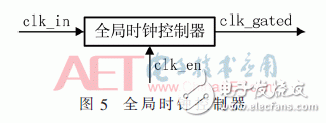
该模块用来控制各个模块的时钟。一旦一个会话记录的请求发生,那么全局时钟控制器就会向各个模块发出时钟停止信号,中止各个模块的运行,在会话记录完成后,才会发出时钟继续的信号。
图5就是全局时钟控制器的模块图,这是整个架构设计中最基本的一块。
2.5 调试时钟模块
在全局时钟被中止的时候,虽然其他模块都停止工作了,但是会话记录模块、会话取样模块、内存控制器等一系列模块都还要继续工作,因为系统为他们单独设置了这么一个时钟模块,在全局时钟被中止时,继续为其他模块提供时钟中断。
3 新调试系统的软件部分
软件部分的功能就是根据工程师的需求配置相应的调试环境,并将硬件产生的信息存储到相应的文件中去。
虽然新调试系统解决了存储时间较长的问题,但是为了提高调试效率,在存储过程中,我们采用多Buffer轮替的方式来提高数据的读取效率。
4 应用的成果
在新一代GPU的结构中加上了新的硬件调试架构,取得了初步的成果。
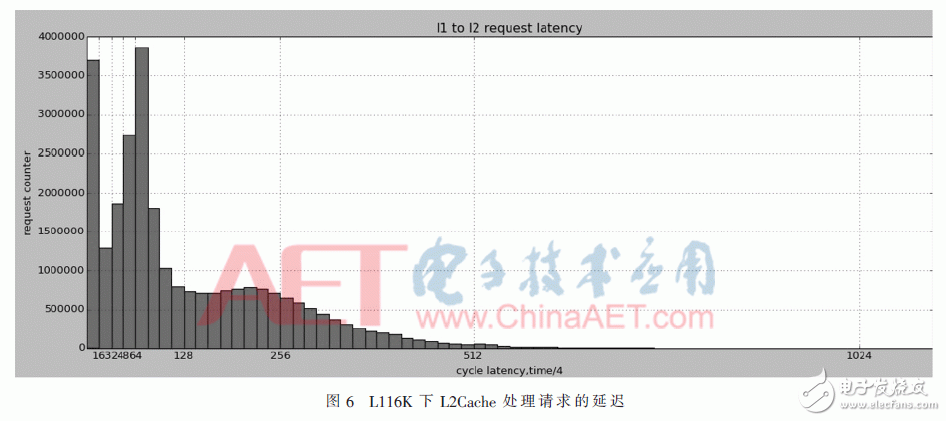
在这次设计开发中,在FPGA上通过大量的应用,利用新的调试系统对L2Cache进行了研究,获取了大量的数据。图6是在不同的L1Cache设计下,L2 Cache和内存存储模块(MXU)之间会话后的分析结果。从图中,我们可以清晰地看到在实际中,L2 Cache是如何处理接收的请求,以及其中的4个bank各自的负载情况如何,使得硬件开发人员可以清晰地发现Cache设计中存在的问题,并为优化Cache结构提供了充分的数据基础。
另外,我们也在FPGA上重现了一些硬件随机问题,并且获取了相应的数据。在把这些数据导入我们的RTL仿真环境后,成功地在模拟环境中重现了这些硬件问题。现在通过调试系统获取信息进行模拟重现,解决了过去硬件开发人员调试硬件问题由于硬件封装而只能通过间接信息分析来调试的问题。硬件开发人员可以根据波形来分析出问题的原因,极大地提高开发人员调试的速度。
5 结语
利用这种双时钟架构,我们能否更进一步开发单步调试系统,使得硬件调试象软件调试一样,可以设断点,停下后即时查看硬件状态。如果能实现,那将更进一步简化硬件调试能力,提高硬件开发水平,这也是我们下一步的研究方向之一。
-
轮胎动态试验台在线测控系统的研制2009-04-16 0
-
基于labview的动态波形数据连续显示2012-12-13 0
-
GPU2016-01-16 0
-
采集的动态数据 绘制成XY图,如何实现连续?2016-06-13 0
-
NVIDIA Tesla P40动态GPU内存分配可能吗?2018-09-25 0
-
从一个文本数据的文件夹中,怎样实现数据的连续提取2018-11-03 0
-
什么电源管理适用于FPGA、GPU和ASIC系统2019-10-09 0
-
如何利用FPGA实现高速连续数据采集系统设计?2021-04-08 0
-
如何对RK GPU进行调试呢2022-02-15 0
-
动态模块加载的调试经验分享2022-03-22 0
-
动态二进制翻译系统的调试器框架2009-04-01 571
-
基于模拟器远程调试系统的研究与实现2009-08-05 723
-
支持并发访问可动态更新的GPU无锁跳步哈希表2021-06-24 535
-
非连续数据网络通信系统设计与实现2021-06-24 447
-
单片机系统硬件的静态调试和动态调试综述2021-07-18 887
全部0条评论

快来发表一下你的评论吧 !
