

使用更“时尚”的数据开启机器学习的 Hello World 之门
描述
本期 AI Adventure 中,Yufeng 会带领我们会按照之前分享的最佳实践来试着完整走一遍机器学习的整个流程。工作量有点大,但是聪明的你应该没问题。
使用 MNIST 数据* 来训练模型常常被看作是机器学习界的「Hello World」例子(使用标准的 MNIST 数据训练手写字符的识别模型),今天我们跟着 Yufeng 一起,使用更“时尚”的数据开启机器学习的 Hello World 之门。
* 段注:MNIST 是一个手写数字图像的数据集,每幅图像都由一个整数标记。它主要用于机器学习算法的性能对标。
“潮”起来的 Machine Learning
Zalando(来自德国的电子商务公司)决意要让 MNIST 再“火”一把,前段时间 Zalando 旗下的研究部门发布了叫做 Fashion-MNIST 的一个数据集。这是一个和 MNIST 具有相同格式的数据集,唯一的不同在于手写字符被替换成了服饰、鞋子、挎包等等内容。它仍然有 10 个种类,图像也仍然是 28x28 像素。
在 GitHub 查看更多对 Fashion-MNIST 数据集的介绍(中文):
https://github.com/zalandoresearch/fashion-mnist/blob/master/README.zh-CN.md
我们一起训练一个模型,然后用它来甄别所属的服饰品类吧!
线性 Classifier
我们先从构建一个线性的 classifier 开始,来看看怎么操作。同以往一样,我们用 TensorFlow 的评估器框架(链接参见段后) 来简化编程和维护。回忆一下,我们会经历加载数据、创建 classifier,然后运行训练和评估等操作。另外还会用本地模型直接做一些预测,官方文档参考:
https://tensorflow.google.cn/get_started/get_started_for_beginners?hl=zh-CN
下面从创建模型开始,我们首先把数据集中的图像从 28x28 的像素排布转为 1x784 的形式,然后将之称为特征列 pixels。此操作类似于 AIA 第三期:无需数学知识,轻松搞定鸢尾花辨识模型 中出现的 flower_features。
feature_columns = [ tf.feature_column.numeric_column( "pixels", shape=784)]classifier = tf.estimator.LinearClassifier( feature_columns=feature_columns, n_classes=10, model_dir=logdir)
下一步创建线性的 classifier。我们有 10 种品类需要做标记,而不是之前鸢尾花案例中的三种。
要开始训练,我们需要配置数据集和输入函数。TensorFlow 有内置的函数接受一个 NumPy 型的数组用于生成输入函数,此处我们就用它来简化一下。
tf.estimator.inputs.numpy_input_fn( x={'pixels': X}, y=Y, batch_size=batch_size, num_epochs=epochs, shuffle=shuffle)DATA_SETS = input_data.read_data_sets( "/tmp/fashion-mnist")
接着用 input_data 模块把数据集载入,将函数参数指向数据集下载的位置。
然后通过调用 classifier.train() 把 classifier、输入函数和数据集都结合起来。
classifier.train( input_fn=train_input_fn, steps=num_steps)accuracy_score = classifier.evaluate( input_fn=eval_input_fn)['accuracy']
最终,我们进行一次评估来看看模型表现如何。使用经典 MNIST 数据集时,此模型常常得到 91% 左右的准确度。然后,由于时尚版 MNIST 有更复杂的数据集,所以只得到了略高于 80% 的精确度,甚至有时更低一些。
怎样才能改善呢?如 AIA 第六期:通过深度神经网络再识 Estimator 中提到的那样进行就好了。
转为深度模型
切换到 DNNClassifier 就是换一行代码的功夫,现在重新开始训练,然后评估看看是否深度模型会比线性的好一些。
classifier = tf.estimator.DNNClassifier( feature_columns=feature_columns, n_classes=10, hidden_units=[100, 75, 50], model_dir=logdir )
正如第五期:通过 TensorBoard 将模型可视化 中讨论的那样,我们应当用 TensorBoard 来横向并且比较一下两个模型。
tensorboard --logdir=models/fashion_mnist/
浏览器打开 http://localhost:6006
TensorBoard
看看 Tensorboard,似乎深度模型并没有比线性模型好到哪里去!这很可能是对超参数的微调不到位导致的,参见 AIA 第二期:机器学习常见的七个步骤。
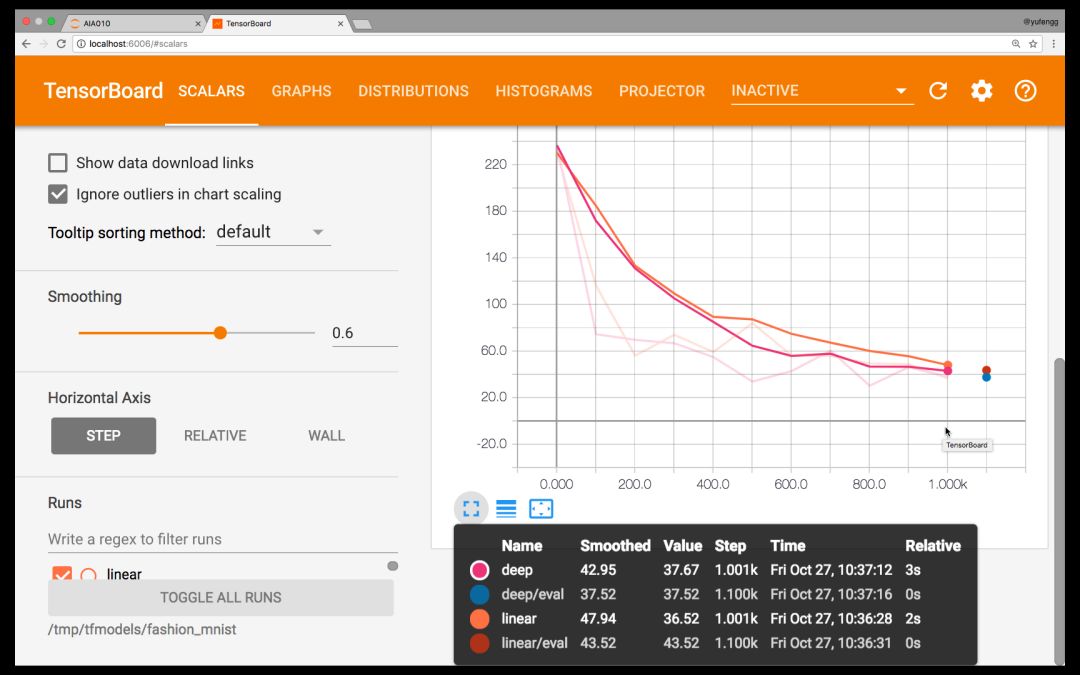
看起来好像是要一路飙到底…
也许是我们的模型需要更大一些来容纳如此搞复杂度的模型?抑或训练应该更少一些?我们来试试看。经过屡次调试微参数,模型的失真度突破性降低了,并且比线性模型得到的精度更高。
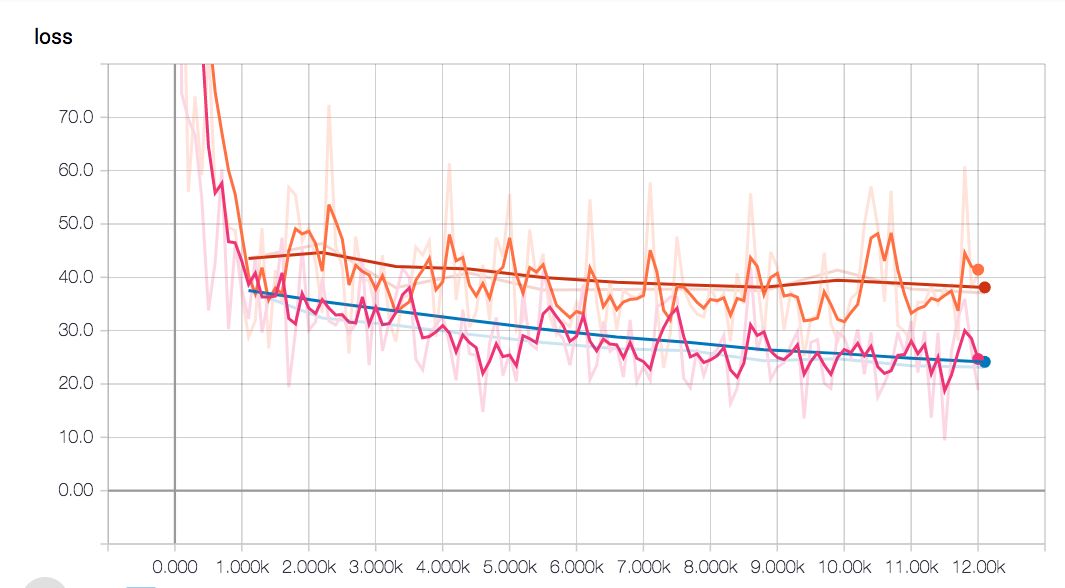
深度模型(蓝色对比线性的红色线)的失真度保持较低状态
达到这一精度之前在训练中多了些步骤,但是最终得到更高精度又使得这些付出非常值得。
由图可见线性模型的平缓期来得比深度网络要早。这是由于深度模型复杂度更高,它们需要的训练时间更长。
此时,模型差不多满足我们的要求了。我们可以将其导出,然后产生一个可伸缩的时尚版 MNIST classifier API。至于如何导出,可以参照第四期中给出的详细步骤。
预测
我们快速回顾一下用评估器做预测的方法。很大程度上,它就像是我们训练和评估的方式;这也是评估器(框架)的极大优势——通用一致的函数接口。
X = DATA_SETS.test.images[5000:5005]predict_input_fn = tf.estimator.inputs.numpy_input_fn( x={'pixels': X}, batch_size=1, num_epochs=1, shuffle=False)predictions = classifier.predict( input_fn=predict_input_fn)
注意我们这次把 batch_size 指定为 1,num_epochs 指定为 1,shuffle 值为 false。这是因为我们想要按着顺序一个一个的预测,一次在所有数据上进行预测。我从评估所用数据集中间挑选了 5 幅图像用于预测。
我选择这 5 幅的原因不仅仅是因为它们在正中间,还因为这些模型中有两个是不正确的。两个都应该是衬衫,但却被模型认为第三个是包而第五个是大衣。由此,仅仅考虑图像的纹理变化这个因素,你能看到这些样本比起手写数字来说是多么有挑战性。
后续步骤
你可以在这个 Gist(链接在段后)上看到本次分享中所用来训练和生成图像的代码。你的模型表现如何?你所最终采用的参数又是什么样的?在评论当中分享一下吧!
https://gist.github.com/yufengg/2b2fd4b81b72f0f9c7b710fa87077145
精彩提要
后续的几期将会着眼于机器学习生态的工具,从而帮助你创建自己的操作流程和工具链。与此同时也会展示更多可以用来解决机器学习问题的模型体系结构。我非常期待能在后面的分享中继续为你分析解答!在那之前,不要忘了多使用机器学习!
-
微雪Arduino系列教程五:Hello World2016-04-27 0
-
让机器向“时尚达人”学习的技巧概述2019-09-16 0
-
扒一扒C语言hello world背后的内幕2022-09-30 0
-
Android开发之“hello World”的实现2011-08-24 5497
-
NB3000_Hello_World2016-02-18 598
-
Hello_World.Constraint2016-02-22 421
-
MICROCHIP MINUTES 4 - HELLO WORLD2018-06-07 2665
-
如何用多种编程语言写“Hello,World!”程序2020-01-09 3701
-
基于Nios 的 hello world2021-11-30 422
-
HELLO WORLD!2021-12-03 487
-
STM32开发入门(二)——Hello World2021-12-07 446
-
ZYNQ学习笔记_ZYNQ简介和Hello World2021-12-22 732
-
如何编写第一个hello world程序2022-03-02 7889
-
Zynq上使用Vitis的双ARM Hello World2022-12-14 731
-
如何在鸿蒙开发板上输出Hello World2023-01-15 1110
全部0条评论

快来发表一下你的评论吧 !
