

全新AI芯片,能效超GPU的100倍
电子说
描述
最近硬件业界有些热闹:IBM研发出能效超GPU 100倍的新型存储器,英特尔预计2020年发布第一批独立GPU,清华的Thinker芯片论文入选ISCA-18。从学术界到产业界,芯片研究者的探索从未停止,进展也在切实发生。英特尔中国研究院院长宋继强博士,清华大学教授、微纳电子学系主任魏少军博士对未来AI芯片趋势进行了展望。
芯片是当前科技、产业和社会关注的热点,也是 AI 技术发展过程中不可逾越的关键阶段。无论哪种 AI 算法,最终的应用必然通过芯片来实现。
在刚刚结束的计算机体系结构顶会ISCA 2018上,2017年的图灵奖得主、体系结构领域的两位宗师级人物John L. Hennessy和David A. Patterson在演讲中指出,随着摩尔定律和登纳德缩放比例定律(Dennard Scaling)的放缓甚至停滞,单处理器核心的性能每年的提升已降为3%左右——相比上世纪60年代的黄金时期,那时候由于体系结构的创新,计算机性能每年提升在60%左右。
通用处理器性能提升的形势看上去已经十分严峻,但接下来我们要带来一些好消息。从IBM、英特尔到微软,从学术界到产业界,芯片研究者的探索从未停止,进展也切切实实在发生。
IBM Nature论文:全新AI芯片,能效超GPU的100倍
在最近发表在Nature上的一篇论文中,IBM Research AI团队用大规模的模拟存储器阵列训练深度神经网络(DNN),达到了与GPU相当的精度。研究人员相信,这是在下一次AI突破所需要的硬件加速器发展道路上迈出的重要一步。

未来人工智能将需要大规模可扩展的计算单元,无论是在云端还是在边缘,DNN都会变得更大、更快,这意味着能效必须显著提高。虽然更好的GPU或其他数字加速器能在某种程度上起到帮助,但这些系统都不可避免地在数据的传输,也就是将数据从内存传到计算处理单元然后回传上花费大量的时间和能量。
模拟技术涉及连续可变的信号,而不是二进制的0和1,对精度具有内在的限制,这也是为什么现代计算机一般是数字型的。但是,AI研究人员已经开始意识到,即使大幅降低运算的精度,DNN模型也能运行良好。因此,对于DNN来说,模拟计算有可能是可行的。
但是,此前还没有人给出确凿的证据,证明使用模拟的方法可以得到与在传统的数字硬件上运行的软件相同的结果。也就是说,人们还不清楚DNN是不是真的能够通过模拟技术进行高精度训练。如果精度很低,训练速度再快、再节能,也没有意义。
在IBM最新发表的那篇Nature论文中,研究人员通过实验,展示了模拟非易失性存储器(NVM)能够有效地加速反向传播(BP)算法,后者是许多最新AI进展的核心。这些NVM存储器能让BP算法中的“乘-加”运算在模拟域中并行。
研究人员将一个小电流通过一个电阻器传递到一根导线中,然后将许多这样的导线连接在一起,使电流聚集起来,就实现了大量计算的并行。而且,所有这些都在模拟存储芯片内完成,不需要数字芯片里数据在存储单元和和处理单元之间传输的过程。
IBM的大规模模拟存储器阵列,训练深度神经网络达到了GPU的精度。来源:IBM Research
由于当前NVM存储器的固有缺陷,以前的相关实验都没有在DNN图像分类任务上得到很好的精度。但这一次,IBM的研究人员使用创新的技术,改善了很多不完善的地方,将性能大幅提升,在各种不同的网络上,都实现了与软件级的DNN精度。
单独看这个大规模模拟存储器阵列里的一个单元,由相变存储器(PCM)和CMOS电容组成,PCM放长期记忆(权重),短期的更新放在CMOS电容器里,之后再通过特殊的技术,消除器件与器件之间的不同。研究人员表示,这种方法是受了神经科学的启发,使用了两种类型的“突触”:短期计算和长期记忆。
这些基于NVM的芯片在训练全连接层方面展现出了极强的潜力,在计算能效 (28,065 GOP/sec/W) 和通量(3.6 TOP/sec/mm^2)上,超过了当前GPU的两个数量级。
这项研究表明了,基于模拟存储器的方法,能够实现与软件等效的训练精度,并且在加速和能效上有数量级的提高,为未来设计全新的AI芯片奠定了基础。研究人员表示,他们接下来将继续优化,处理全连接层和其他类型的计算。
英特尔首款独立GPU最早2020年问世,曝光14nm独立GPU原型
另一芯片大厂英特尔自然也不会回避这场游戏。
昨天,英特尔发推正式确认,其首款独立GPU最早将于2020年问世,并附上了一张英特尔首席架构师Raja Koduri的照片。
Raja Koduri在去年11月加入英特尔,此前曾在AMD担任高级副总裁、RTG负责人。Raja Koduri有超过25年的视觉和加速计算技术,将推进英特尔的“计算和图形领先”战略。
Raja Koduri
不过,英特尔的推特并没有说明这些GPU的发展方向,也没有透露哪一款产品将率先上市,但预计数据中心和游戏PC都是目标。
英特尔此前在2018年ISSCC会议(国际固态电路会议)上展示了首个14nm 独立GPU原型,它是一个双芯片解决方案。第一个芯片包含两个关键部件:GPU本身和一个系统代理;第二个芯片是一个与系统总线连接的FPGA。目前,GPU组件基于英特尔的Gen 9架构,并具有三个执行单元(EU)集群。这三个集群连接到一个复杂电源/时钟(power/clock)管理机制,该机制有效地管理每个EU的电源和时钟速度。
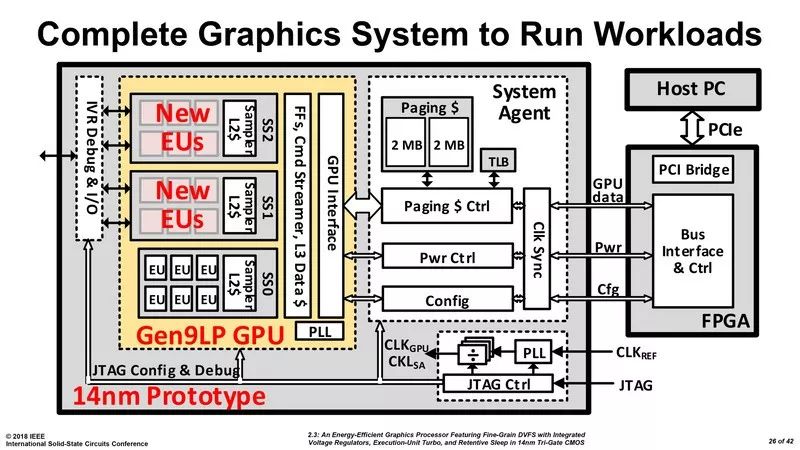

还有一个双时钟机制,可以使时钟速度(即升压状态)增加一倍,超过现在的Gen 9 EU可以在英特尔iGPU上处理的时钟速度。一旦达到合适的能效水平,英特尔将使用新一代的EU,并利用新工艺流程扩大EU数量,开发更大型的独立GPU。
Raja Koduri长期以来一直是图形行业受人尊敬的领导者,他的加盟表明英特尔有意再次认真对待图形产品。尽管很少有人质疑英特尔芯片设计的能力,但从头开始构建新的GPU架构不是一件小事,英特尔在三年内会推出图形产品的难度非常大。
Shrout Research的分析师Ryan Shrout表示,英特尔把目标定在2020年,目的是与AMD的Radeon和Nvidia的GeForce产品竞争。但英特尔需要与AMD和英伟达保持同样的性能和效率,或者至少在20%的差距内。
微软:云计算招聘AI芯片工程师
微软在芯片领域最近也有动作。
3月下旬,微软在其Azure公共云部门发布了至少三个职位空缺,寻找适合AI芯片功能的应聘者。后来,该部门又挂出一个硅谷项目经理的职位空缺,以及“一个软件/硬件协同设计和人工智能加速优化工程师”职位。
在与亚马逊AWS和谷歌云竞争之际,微软愿意不惜一切代价打造一个功能齐全的云服务。专门的处理器是微软证明其在云计算领域为企业提供人工智能服务的一种方式。
半导体领域对微软来说并不是全新的领域。微软已经通过FPGA芯片增强云计算的AI计算能力,并推出Project Brainwave项目。现在,这些芯片可用于使用Azure的即用型机器学习软件进行AI模型的训练和运行。
去年微软表示,它正在为HoloLens的下一个版本构建定制AI芯片,但这不在其云计算部门之内。
微软的一位发言人告诉CNBC,新的职位空缺不属于FPGA计划的一部分,但与公司在设计自己的云硬件方面所做的工作有关,该计划名为Project Olympus。
谷歌由于在云计算市场上落后于AWS和微软,首次提出了在云计算中为人工智能开发定制芯片的想法,并且推出的TPU已经进行了第三次迭代,成为了GPU的一种替代方案。然而,这是一个代价非常高昂的努力。
Moor Insights & Strategy的分析师Patrick Moorhead估计,谷歌在其TPU项目上已经花费了2亿至3亿美元。跟英特尔、谷歌一样,微软做AI芯片的过程也将非常艰辛。
不过,现在微软已经表明了它的支出意愿,上个季度的资本支出达到了创纪录的35亿美元。
宋继强、魏少军:AI芯片尚在发展初期,拥有巨大创新空间
通过芯片技术来大幅增强人工智能研发的条件已经成熟,未来十年将是AI芯片发展的重要时期,不论是架构上还是设计理念上都将有巨大的突破。
赛灵思在今年3月宣布将推出新一代AI芯片架构 ACAP(Adaptive Compute Acceleration Platform),这是一款高度集成的多核异构计算平台,能根据各种应用于工作负载的需求对硬件层进行灵活变化;英伟达在终端侧和服务中心分别提供不同性能和能效比的GPU芯片。
英特尔中国研究院院长宋继强博士,清华大学教授、微纳电子学系主任魏少军博士在今年的《人工智能》杂志第二期《AI 芯片:从历史看未来》中写道,架构创新是AI芯片面临的一个不可回避的课题。
我们要回答一个重要问题:是否会出现像通用 CPU 那样独立存在的 AI 处理器?如果存在的话,它的架构是怎样的? 如果不存在,那么目前以满足特定应用为主要目标的 AI 芯片就一定只能以 IP 核的方式存在,最终被各种各样的 SoC 所集成。这样是一种快速满足具体应用要求的方式。
从芯片发展的大趋势来看,现在还是 AI 芯片的初级阶段,无论是科研还是产业应 用都有巨大的创新空间。从确定算法、领域的 AI 加速芯片向具备更高灵活性、适应性的智能芯片发展是科研发展的必然方向。神经拟态芯片技术和可重构计算芯片技术允许硬件架构和功能随软件变化而变化,实现以高能效比支持多种智能任务,在实现 AI 功能时具有独到的优势,具备广阔的前景。
下文选自《AI芯片:从历史看未来》文章第四节和第五节。
四、AI 芯片的发展趋势
AI 应用落地还有很长的路要走,而对于芯片从业者来讲,当务之急是研究芯片架 构问题。从感知、传输到处理,再到传输、执行,这是 AI 芯片的一个基本逻辑。但是智慧处理的基本架构是什么?还没有人能够说得清,研究者只能利用软件系统、处理器等去模仿。软件是实现智能的核心,芯片是支撑智能的基础。我们认为,短期内以异构计算(多种组合方式)为主来加速各类应用算法的落地(看重能效比、性价比、可靠性);中期要发展自重构、自学习、自适应的芯片来支持算法的演进和类人的自然智能;长期则朝着通用 AI 芯片的方面发展。
通用 AI 计算
AI 的通用性实际上有两个层级:第一个层级是可以处理任意问题;第二个层级是同时处理任意问题。第一层的目标是让一种 AI 的算法可以通过不同的设计、数据和训 练方法来处理不同的问题。例如现在流行的深度增强学习方法,大家用它训练下棋、打扑克、视觉识别、语音识别、行为识别、运动导航等等。但是,不同的任务使用不同的数据集来独立训练,模型一旦训练完成,只适用于这种任务,而不能用于处理其它任务。 所以,我们可以说这种 AI 的算法和训练方法是通用的,而它训练出来用于执行某个任 务的模型(是对具体解决这个任务的算法的表示,可以理解为程序中的一个模块)是不通用的。第二层的目标是让训练出来的模型可以同时处理多种任务,就像人一样可以既会下棋,又会翻译,还会驾驶汽车和做饭。这个目标更加困难,首先是还没有发现哪一个算法可以如此全能,其次是如何保证新加入的能力不会影响原有能力的稳定性,反而 可以弥补原来能力的不足,从而更好的完成任务。例如,我们知道多模态数据融合可以比只使用单模态数据有更好的准确性和鲁棒性。
通用 AI 芯片
“通用 AI 芯片”就是能够支持和加速通用 AI 计算的芯片。关于通用 AI(有时也 成为强 AI)的研究希望通过一个通用的数学模型,能够最大限度概括智能的本质。那么,什么是智能的本质?目前比较主流的看法,是系统能够具有通用效用最大化能力:即系统拥有通用归纳能力,能够逼近任意可逼近的模式,并能利用所识别到的模式取得一个效用函数的最大化效益。这是很学术化的语言,如果通俗地说,就是让系统通过学习和训练,能够准确高效地处理任意智能主体(例如人)能够处理的任务。通用 AI 的难点 主要有两个,一个是通用性(算法和架构),第二个是实现复杂度。
通用 AI 芯片的复杂度来自于任务的多样性和对自学习、自适应能力的支持。所以, 我们认为通用 AI 芯片的发展方向不会是一蹴而就地采用某一种芯片来解决问题,因为理论模型和算法尚未完善。最有效的方式是先用一个多种芯片设计思路组合的灵活的异构系统(heterogeneous system of AI chips)来支持,各取所长,取长补短。当架构成熟,就可以考虑设计SoC(System on Chip)来在一个芯片上支持通用 AI。
五、面临的挑战
AI 芯片是当前科技、产业和社会关注的热点,也是 AI 技术发展过程中不可逾越 的关键阶段。无论哪种 AI 算法,最终的应用必然通过芯片来实现,不论是 CPU 还是文 中提及的各种 AI 芯片。由于目前的 AI 算法都有各自的长处和短处,只有给它们设定一个合适的应用边界才能最好地发挥它们的作用。因此,确定应用领域就成为发展 AI 芯 片的重要前提。遗憾的是,AI 的“杀手”级应用目前尚未出现,已经存在的一些应用 对于老百姓的日常生活来说也还不是刚需,也还不存在适应各种应用的“通用”算法。其实,也不需要全部通用,能像人一样可以同时拥有数十种能力,并且可以持续学习改进,就已经很好了。因此,AI 芯片的外部发展还有待优化。
架构创新是 AI 芯片面临的一个不可回避的课题。我们要回答一个重要问题:是否 会出现像通用 CPU 那样独立存在的 AI 处理器?如果存在的话,它的架构是怎样的? 如果不存在,那么目前以满足特定应用为主要目标的 AI 芯片就一定只能以 IP 核的方式存在,最终被各种各样的 SoC 所集成。这样是一种快速满足具体应用要求的方式。
从芯片发展的大趋势来看,现在还是 AI 芯片的初级阶段,无论是科研还是产业应用都有巨大的创新空间。从确定算法、领域的 AI 加速芯片向具备更高灵活性、适应性的智能芯片发展是科研发展的必然方向。神经拟态芯片技术和可重构计算芯片技术允许 硬件架构和功能随软件变化而变化,实现以高能效比支持多种智能任务,在实现 AI 功能时具有独到的优势,具备广阔的前景。
-
中国企业的崛起!全球AI芯片Top24榜单7家中国公司上榜2018-05-07 0
-
AI芯片界的领头羊进军机器人行业2018-06-11 0
-
ai芯片和gpu的区别2021-07-27 0
-
当AI遇上FPGA会产生怎样的反应2021-09-17 0
-
GPU八大主流的应用场景2021-12-07 0
-
IBM全新AI芯片设计登上Nature,解决GPU的算力瓶颈2018-06-13 1301
-
浅析GPU、FPGA、ASIC三种主流AI芯片的区别2019-03-07 29123
-
AI优化的FPGA和GPU的芯片级对比2021-03-29 2478
-
GTC2022大会亮点:NVIDIA发布全新AI计算系统—DGX H1002022-03-24 1595
-
壁仞科技发布首款通用GPU芯片BR1002022-08-10 1583
-
NVIDIA GTC 2023:GPU算力是AI的必需品2023-03-22 2929
-
曦思N100:功能强大的AI全流程处理GPU2023-05-26 2182
-
AMD甩出最强AI芯片 单个GPU跑大模型2023-06-20 634
-
国产AI芯片进展几何?国产AI芯片之争才刚刚开始2023-07-04 1651
-
ai芯片和gpu芯片有什么区别?2023-08-08 4032
全部0条评论

快来发表一下你的评论吧 !
