

一文快速了解机器学习任务中的重要成分和结构
电子说
描述
▌基本概念
我们从一个实例来了解机器学习的基本概念。假设我们现在面临这样一个任务(Task) ,任务的内容是识别手写体的数字。对于计算机而言,这些手写数字是一张张图片,如下所示:

对人来说,识别这些手写数字是非常简单的,但是对于计算机而言,这种任务很难通过固定的编程来完成,即使我们把我们已经知道的所有手写数字都存储到数据库中,一旦出现一个全新的手写数字(从未出现在数据库中),固定的程序就很难识别出这个数字来。所以,在这里,我们的任务指的就是这类很难通过固定编程解决的任务。
要解决这类任务,我们的计算机需要有一定的“智能”,但是在我们的认知中,只有人类才具备这种“高级智能”(某些灵长类动物虽然具备一定的运用工具的能力,但我们认为那距离我们所说的智能还有很远的距离),所以如果我们想让计算机具备这种“智能”,由于这是人造的事物,我们称这种智能为人工智能(Artificial Intelligence, AI) 。
正式地讲,人工智能,是指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序的手段实现的类人智能技术。 机器学习可以帮助我们解决这类任务 ,所以我们说,机器学习是一种人工智能技术。
那么机器学习是怎么解决这类任务的呢?
机器学习(Machine learning)是一类基于数据或者既往的经验,优化计算机程序的性能标准的方法。这是机器学习的定义,看起来可能难以理解,我们对它进行分解:
1、首先,对于手写数字识别这个任务来说,数据或者既往的经验就是我们已经收集到的手写数字,我们要让我们的程序从这些数据中学习到一种能力/智能 ,这种能力就是:通过学习,这个程序能够像人一样识别手写数字。
2、性能标准,就是指衡量我们的程序的这种能力高低的指标了。在识别任务中,这个指标就是识别的精度。给定100个手写数字,有99个数字被我们的“智能”程序识别正确,那么精度就是 99% 。
3、优化,就是指我们基于既往的经验或者数据,让我们的“智能”程序变得越来越聪明,甚至比人类更加聪明。
机器学习,就是能够从经验中不断“学习进步”的算法,在很多情况下,我们将这些经验用数值描述,因此,经验=数据 ,这些收集在一起的数据被成为数据集(Dataset) ,在这些已有的数据集上学习的过程我们称之为训练(Train) ,因此,这个数据集又被称为训练集 。
很显然,我们真正关心的并不是机器学习算法在训练集上的表现,我们希望我们的“智能”程序对从未见过的手写字也能够正确的识别,这种在新的样本(数据)上的性能我们称之为泛化能力(generalization ability) ,对于一个任务而言,泛化能力越强,这个机器学习算法就越成功。
根据数据集的不同,机器学习可以分成如下三类:
监督学习(Supervised learning):数据集既包含样本(手写字图片),还包含其对应的标签(每张手写字图片对应的是那个数字)
无监督学习(Unsupervised learning):与监督学习相对,数据集仅包含样本,不包含样本对应的标签,机器学习算法需要自行确定样本的类别归属
强化学习(Reinforcement learning):又称为增强学习,是一种半监督学习,强调如何基于环境而行动,以取得最大化的预期利益。
当前大热的神经网络,深度学习等等都是监督学习,随着大数据时代的到来以及GPU带来的计算能力的提升,监督学习已经在诸如图像识别,目标检测和跟踪,机器翻译,语音识别,自然语言处理的大量领域取得了突破性的进展。
然而,当前在无监督学习领域并没有取得像监督学习那样的突破性进展。由于在无人驾驶领域主要应用的机器学习技术仍然是监督学习,本文将重点讲监督学习的相关内容。
在本文中,为了便于理解,我们使用手写数字识别来描述处理的任务,实际上,机器学习算法能够处理的任务还有很多,例如:分类,回归,转录,机器翻译,结构化输出,异常检测,合成与采样, 缺失值填补等等。这些任务看似不同,却有着一个共性,那就是很难通过人为设计的确定性程序来解决。
▌监督学习
经验风险最小化
监督学习,本质上就是在给定一个集合 (X,Y) 的基础上去学得一个函数:
y=f(x)
在 MNIST 问题中, X 就表示我们收集到的所有的手写数字图片的集合,Y 表示这些图片对应的真实的数字,函数 f 则表示输入一张手写字图片,输出这张图片表示的数值这样的一个映射关系。
很显然,这样的映射关系中的 x 有着一个极其巨大的取值域(甚至有无限种可能取值), 所以我们可以把我们已有的样本集合 (X,Y) 理解为从某个更大甚至是无限的母体中,根据某种未知的概率分布 p,以独立同分布随机变量方式来取样。现在,我们假定存在一个损失函数(Loss function) L ,这个损失函数可以表述为:
L(f(x),y)
这个损失函数描述的是我们学得的函数 f(x) 的输出和 x 样本对应的真实值 y 之间的距离,很显然,这个损失越小,表示我们学得的函数 f 更贴近于真实映射 g 。以损失函数为基础,我们定义风险 :
函数 f 的风险,就是损失函数的期望值。 由于我们以手写字分类为例,所以这里各个样本的概率分布 p 是离散的,我们可以用如下公式定义风险:
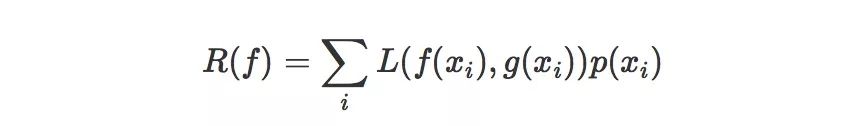
如果是连续的,则可以使用定积分和概率密度函数来表示。这里的 xi 是指整个样本空间的所有可能取值,所以,现在的目标就变成了: 在很多可能的函数中,去寻找一个 f,使得风险 R(f) 最小 。
然而,真实的风险是建立在对整个样本空间进行考量的,我们并不能获得整个样本空间,我们有的只是一个从我们要解决的任务的样本空间中使用独立同分布的方法随机采样得到的子集 (X,Y),那么,在这个子集上,我们可以求出这个真实分布的近似值,比如说经验风险 :
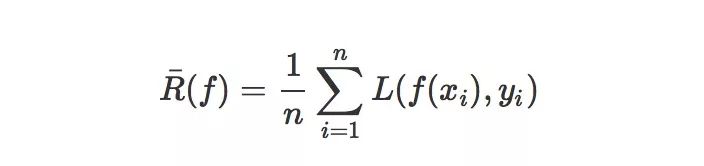
其中 (xi,yi) 是我们已有的数据集中的样本,所以,我们选择能够最小化经验风险的函数 f 这样的一个策略就被称之为经验风险最小化原则 。
很显然,当训练数据集足够大的时候,经验风险最小化这一策略能够保证很好的学习效果——这也就是我们当代深度神经网络取得很多方面的成功的一个重要原因。专业的说,我们把我们已有的数据集的大小称之为样本容量 。不论是什么应用领域,规范的大数据集合,就意味着我们的机器学习任务已经成功了一半。
模型,过拟合,欠拟合
那么学习这个 f 需要一个载体 , 这个载体的作用就是,用它我们可以表述各种各样的函数 f 这样我们就可以通过调整这个载体去选择一个最优的 f ,这个最优的 f 能够使经验风险最小化,这个载体我们专业地说,就是机器学习中的模型(model) , 单纯地说模型的抽象概念可能让人难以理解,我们选取一种模型的实例来看。
我们以人工神经网络(artificial neural network,ANN)为例来讨论。首先,我们知道我们现在需要的是一个模型,这个模型具有能够描述各种各样的函数的能力,下图是一个神经网络:
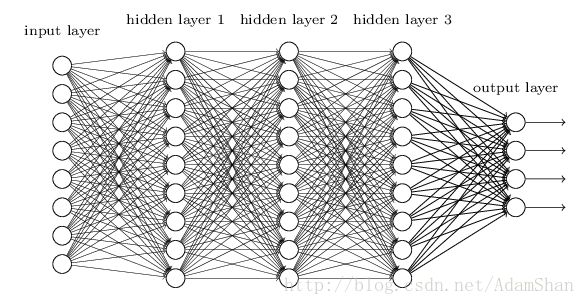
它看起来很复杂,让人费解,那么我们把它简化,如下图:
我们把这个模型理解成一个黑箱,这个黑箱里有很多参数:(w1,w2,w3,...,wn),我们用 W 来描述这个黑箱中的参数,这些参数叫模型参数,即使模型内部的结构不变,仅仅修改这些参数,模型也能表现出不同的本领。
具体来说:对于手写字识别任务,我们在手写字数据集上通过一定的算法调整神经网络的参数,使得神经网络拟合出一个函数 f ,这个 f 是经验风险最小化的函数,那么我们训练出来的这个“黑箱”就可以用于手写字识别了;另一方面,对于车辆识别来说,假设我们有车辆数据集,相同的思路,我们可以训练出一个黑箱来最做车辆识别。如下图所示:

在前文中我们知道,考量一个机器学习模型的关键在于其泛化能力,一个考量泛化能力的重要指标就是模型的训练误差和测试误差的情况:
训练误差:模型在训练集上的误差
测试误差:模型在从未“见过的”测试集上的误差
这两个误差,分别对应了机器学习任务中需要解决的两个问题: 欠拟合和过拟合 。当训练误差过高时,模型学到的函数并没有满足经验风险最小化 ,对手写字识别来说,模型即使在我们的训练集中识别的精度也很差,我们称这种情况为欠拟合。
当训练误差低但是测试误差高,即训练误差和测试误差的差距过大时,我们称之为过拟合,此时模型学到了训练集上的一些“多余的规律”,表现为在训练数据集上识别精度很高,在测试数据集(未被用于训练,或者说未被用于调整模型参数的数据集合)上识别精度不高。
模型的容量(capacity) 决定了模型是否倾向于过拟合还是欠拟合。模型的容量指的是模型拟合各种函数的能力,很显然,越复杂的模型就能够表述越复杂的函数(或者说规律,或者说模式)。那么对于一个特定的任务(比如说手写字识别),如何去选择合适的模型容量来拟合相应的函数呢?这里就引入了 奥卡姆剃刀原则 :
奥卡姆剃刀原则:在同样能够解释已知观测现象的假设中,我们应该挑选”最简单”的那一个。
这可以理解为一个简约设计原则,在处理一个任务是,我们应当使用尽可能简单的模型结构。
“一定的算法”–>梯度下降算法
前面我们说到我们可以通过 一定的算法 调整神经网络的参数,这里我们就来介绍一下这个 定向(朝着经验风险最小化的方向)调整模型参数的算法——梯度下降算法 。
要最小化经验风险 R¯(f),等同于最小化损失函数,在机器学习中,损失函数可以写成每个样本的损失函数的总和:
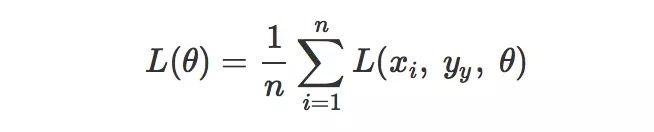
其中 θ 表示模型中的所有参数,现在我们要最小化 L(θ),我们首先想到的是求解导数,我们把这个 L对 θ 的导数记作 L′(θ) 或者 dLdθ , 导数 L′(θ) 就代表了函数 L(θ) 在 θ 处的斜率,我们可以把函数的输入输出关联性用斜率来描述:
L(θ+α)≈L(θ)+αL′(θ)
其中, α 是一个变化量,利用这个公式,我们就可以利用导数来逐渐使 L 变小,具体来说,我们只要让 α 的符号和导数的符号相反,即:
sign(α)=−sign(L′(θ))
这样, L(θ+α) 就会比原来的 L(θ) 更小:
L(θ+α)=L(θ)−|αL′(θ)|
这种通过向导数的反方向移动一小步来最小化目标函数(在我们机器学习中,也就是损失函数)的方法,我们称之为 梯度下降(gradient descent) 。
对于神经网络这种复杂的模型来说,模型包含了很多参数,所以这里的 θ 就表示一个参数集合,或者说参数向量, 所以我们要求的导数就变成了包含所有参数的偏导数的向量 ▽θL(θ)。
这里的 α 就可以理解为我们进行梯度下降的过程中的步长了,我们将学习的步长称为学习率(learning rate) , 它描述了梯度下降的速度。
▌小结
在本文中,我们没有介绍任何一种具体的机器学习算法和模型,但是我们快速的了解了机器学习任务中的重要成分和结构,以下我们来进行一个小的总结:
首先,机器学习是用来完成特定的任务的:比如说手写字识别,行人检测,房价预测等等。这个任务必须要有一定的性能度量 ,比如说识别精度,预测误差等等。
然后,为了处理这个任务 ,我们需要设计模型 ,这个模型能够从数据中基于一定的策略 (比如说经验风险最小化原则) 和一定的算法 (比如说梯度下降算法) 去 学习一个函数 。
最后,这个函数要能够处理这个任务中的各种各样的情况(包括没有出现在训练集中的情况),这个模型要有很好的泛化能力 ,这样,我们的机器学习任务就成功了。
-
[转]物联网和机器学习究竟有哪些真实应用价值?2017-04-19 0
-
【下载】《机器学习》+《机器学习实战》2017-06-01 0
-
人工智能和机器学习的前世今生2018-08-27 0
-
干货 | 这些机器学习算法,你了解几个?2019-09-22 0
-
了解时钟结构在STM32中的重要性2021-08-02 0
-
机器学习的基础内容2021-08-20 0
-
一文了解LVGL的学习路线2021-12-07 0
-
机器学习的基础内容介绍2022-01-12 0
-
Verilog系统任务的相关资料推荐2022-02-09 0
-
任务和函数的区别?2022-02-09 0
-
机器学习的基础内容汇总2022-02-28 0
-
机器学习简介与经典机器学习算法人才培养2022-04-28 0
-
什么是机器学习? 机器学习基础入门2022-06-21 0
-
深度学习是什么?了解深度学习难吗?让你快速了解深度学习的视频讲解2018-08-23 987
全部0条评论

快来发表一下你的评论吧 !
