

AI自学就可用更少步数复原任意3阶魔方
电子说
描述
魔术方块是非常有趣的益智玩具,但从难度来说,并不比其他棋类游戏困难,如果人工智能(AI)算法可以在国际象棋或围棋中轻松打败人类,那么复原魔术方块也不是这么困难的事。
但是事实上对于算法来说,要解出魔术方块的谜题和下棋是完全不同种类的任务。
过去在棋类游戏中展现出超人类表现的算法,都是属于传统的「强化学习」(RL)系统,这类型 AI 在确定某些特定的一步是实现整体目标的积极步骤时,便会获得奖励,进而使系统产生追求最大利益的习惯性行为,然而当 AI 无法确定这一步是否有益时,强化学习自然就无法发挥作用。
如果还是无法理解,试着这么想吧:在进行棋类游戏时,系统可以轻易去判定一个动作究竟是属于「好棋」或「坏棋」,但是在转动魔术方块时,你能够说出有任何特定的一步,是改善整体难题的关键吗?
从外观上来看,魔术方块是个很单纯的益智玩具,然而因为 3D 立体的特性,这让一般常见的 3 阶魔术方块就已有着惊人的近 4.33×1019 组合,而在其中,只有六面都是相同颜色的状态才能成为「正确解答」。
过去人们已经研究出许多不同算法和策略来解决这项难题,但 AI 研究人员真正的目标还是希望能像 AlphaGo Zero 那样,让 AI 在没有任何历史知识的情况下,学会自行应对随机的魔术方块难题。
而近期加利福尼亚大学 Stephen McAleer 和团队透过一种被称为「自学叠代」(autodidactic iteration)的 AI 技术打造出「DeepCube」系统,成功让 AI 在面对任何乱序的 3 阶魔术方块时都可以成功找出正确解答。
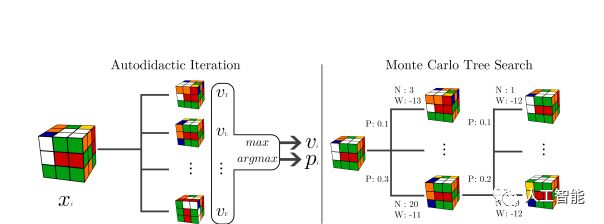
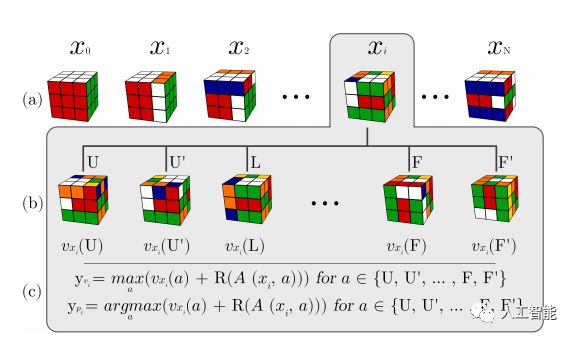
根据团队解释,自学叠代是一种全新的强化学习算法,与过去棋类游戏算法的处理方式不同,它采取了「反着看」的内部奖励判断机制:当 AI 提出一个动作建议时,算法便会跳至完成的图形开始往前推导,直到到达提出的动作建议,藉以判断每一步动作的强度。
虽然听来相当的繁杂,但这让系统能够更熟悉每一步动作,并得以评估出整体强度,一但获得足够数量的数据,系统便能以传统的树状搜索方式去找出如何移动最好的方法。
团队在研究中发现,DeepCube 系统在训练中自己找出了许多与人类玩家相同的策略,并在经过 44 个小时的自学训练后,已经能够在没有任何人为干预下,在平均 30 步以内复原任何随机乱序魔术方块──这些「最佳解答」不是和人类最佳表现一样好,就是比这些表现更好。
McAleer 和团队打算未来将在更大、更难解决的 16 阶魔术方块上进行测试,这项全新的系统将有助于 AI 应用更全面化,像是生物物理学上重要的蛋白质摺叠(Protein Folding)问题或也有望得以解决。
-
魔方复原2013-11-11 0
-
[每周一练]labVIEW_3D魔方(1202-1208)2013-12-01 0
-
【深联华杯】魔方复原2014-01-03 0
-
解魔方机器人2017-02-28 0
-
LEGO魔方机器人2018-05-09 0
-
神马? 解魔方只要 3 秒?简直不敢相信我的眼睛!#高速魔方机器人#2018-10-11 0
-
开源2个基于树莓派的魔方还原机器人2021-01-23 0
-
C语言的算法设计之魔方阵2022-05-05 0
-
【开源分享】基于RT-Thread和N32G457的电子魔方2022-06-13 0
-
魔方教程2016-05-17 592
-
继围棋、德扑之后,AI现在又在魔方领域碾压人类2019-07-22 2516
-
诺丁汉大学用深度学习复原魔方2021-03-03 1401
全部0条评论

快来发表一下你的评论吧 !
