

介绍时序分析概念,那为什么需要OCV呢?
描述
今天我们要介绍的时序分析概念是on chip variations,简称OCV。OCV会对时序分析提出更严格的要求。那为什么需要OCV呢,因为制造工艺的限制,同一芯片上不同位置的MOS晶体管的性能会有一些差异。库中的PVT是一个"点",比如1.2V,250℃,工艺1.0。 但实际芯片的PVT永远不会落在一个点上,而是一个范围;比如说有时序关系的几个cell,可能这几个cell的PVT是1.18V,20℃,工艺0.98。而那个cell的PVT是1.21V,35℃,工艺1.01。这些cell的PVT都不在那个点上,怎么去分析呢?这时候就需要OCV了。
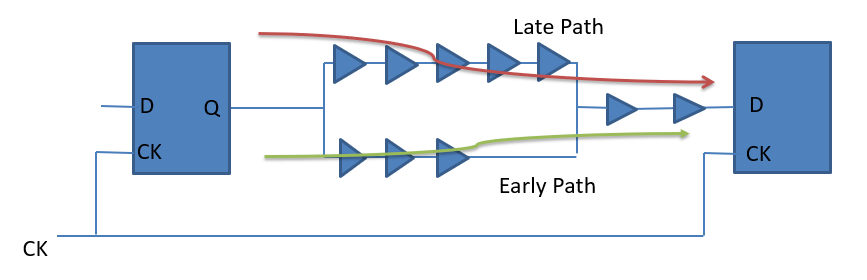
还是参照single mode和bc-wc那张图,OCV的检查方式更加严格,如下所示:
For setup :Launch clock path :late path from max lib Data Path :late path from max libCapture Clock path :early path from min libFor Hold:Launch clock path :early path from min libData Path :early path from min libCapture Clock path :late path from max lib
OCV for setup check
还是原来BC-WC分析模式那张图:
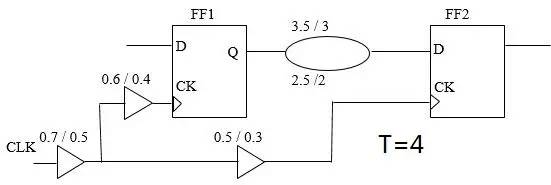
假设PVT情况可以在整个chip上变化, (暂时不考虑CPPR)
clock period = 4Launch clock late path (max) = 0.7 + 0.6 = 1.3Data late path (max) = 3.5Capture clock early path (min) = 0.5 + 0.3 = 0.8Setup = 0.2 Data arrival time = 1.3 + 3.5 = 4.8Data required time = 4 + 0.8 - 0.2 = 4.6Slack =Data required time - Data arrival time= 4.6 - 4.8 = -0.2
OCV for Hold check
对于Hold check, 可以参考下图分析模式:
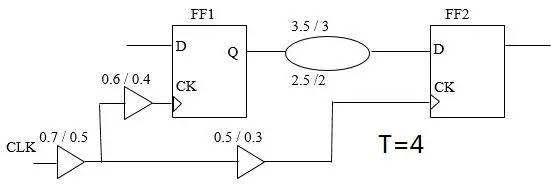
Launch clock early path (min) = 0.5 + 0.4 = 0.9Data early path (min) = 2Capture clock late path (max) = 0.7 + 0.5 = 1.2Hold = 0.2 Data arrival time = 0.9 + 2 = 2.9Data required time =1.2+0.2 = 1.4Slack = Data arrival time - Data required time= 2.9 - 1.4 = 1.5
通过上诉的描述,大家对OCV的分析模式有一定了解了吧,OCV其实是一种相对悲观的分析模式,为了使design和fabrication之间的结果更加接近,现在又诞生了AOCV,SOCV等更高级的分析模式。
时序分析概念是timing derate. 我们可以称为时序增减因子。我们知道在芯片的生产过程中,由于刻蚀,不同点的温度,金属不均匀,串扰,晶体管沟道长度等影响因素,导致片上各个位置单元延迟不一样。因此,我们需要一个缩放因子来让设计更加严格。
timing derate是计算OCV的一种简单方法,在某单一条件(BC-WC)下,把指定path的delay放大或者缩小一些,这个比率就是derate。比如说:
-late
setup ==> data path * 1.1
hold ==> clock path * 1.1
-early
setup ==> clock path * 0.9
hold ==> data path * 0.9
以下图为例:
在setup check中,
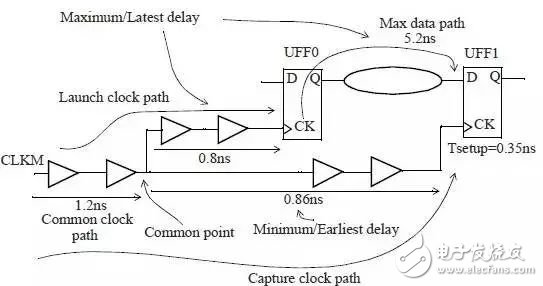
Date arrival time即data path和launch clock path需要使用-late 选项,使得路径变慢。
Date require time即capture clock path需要使用 -early 选项,加快路径延迟。
需要注意的是:考虑time derate需要在某个单一条件下,比如说BC或者WC条件下,把指定path的延迟再放大或者缩小一点,要么是BC,要么是WC,不要把BC和WC混在一起,再OCV,那样太过于悲观。
setup check 一般是工作在WC PVT条件下,因此不需要在late path上,即launch clock path以及data path上再加time derate,因为在WC条件下,launch clock path以及data path上的延迟已经是所有条件下最差的delay了,没有必要再加大延迟,但是WC条件下capture clock path上的delay肯定不是最小的,因此需要加快。
所以上面的timing path做setup check,time derate只需要这样设置:
set_timing_derate -early 0.9
set_timing_derate -late 1.0
我们可以计算一下设了timing derate以后setup check的变化:
上图中:launch clock path = (1.2+0.8)*1.0 = 2.0
max data path = 5.2 * 1.0 =5.2
capture clock path = (1.2 + 0.86) *0.9 = 1.854
所以最小时钟周期 T = 2.0 + 5.2 -1.854 + 0.385= 5.731
可以看到:考虑timing derate以后,会降低整个design的工作频率。
在Hold check中
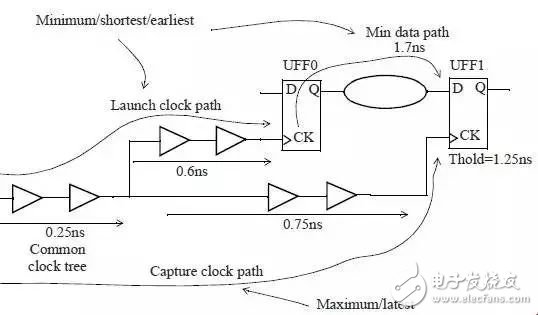
考虑time derate的情况与setup正好相反,
Data require time中的capture clock path使用-late选项,使路径变慢。
Data arrival time中的data path和launch clock path使用-early选项,使路径加快
实际上,Hold check一般在BC条件下,因此,launch clock path与data path不需要再进一步减小delay, 因为已经是最小delay, 但是BC条件下的capture clock path需要derate. 可以使用如下设置
set_timing_derate -early 1.0
set_timing_derate -late 1.2
这样添加time derate后
Launch clock path = 0.85 * 1.0 = 0.85
Min data path = 1.7 * 1.0 = 1.7
Capture clock path = 1.0 * 1.2 = 1.2
所以slack=0.85+1.7-1.2-1.25=0.1
介绍的时序分析概念是CPPR(CRPR)。全称Clock Path Pessimism Removal(Clock Reconvergence Pessimism Removal),中文名“共同路径悲观去除”。它的作用是去除clock path上的相同路径上的悲观计算量。如下图所示:
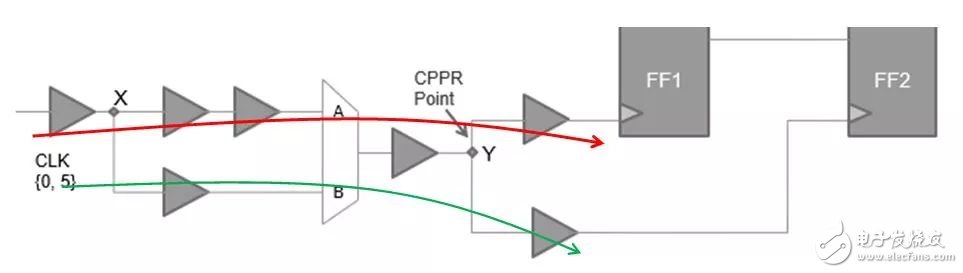
由于STA是穷举型的分析路径,在分析setup timing时,clock launch path会选择红色的路径,clock capture path则会选择绿色的路径,这本身就是不合理的情况,一个mux不可能同时存在两条经过的路径,所以我们需要去除这个计算的悲观量。
CPPR不仅仅存在于OCV,在以下几种情况它都可以存在:
Single Mode without set_timing_derate
BC-WC Mode without set_timing_derate
OCV Mode without set_timing_derate
Single Mode with set_timing_derate
BC-WC Mode with set_timing_derate
OCV mode with set_timing_derate
我们再看上一个计算timing derate的例子:
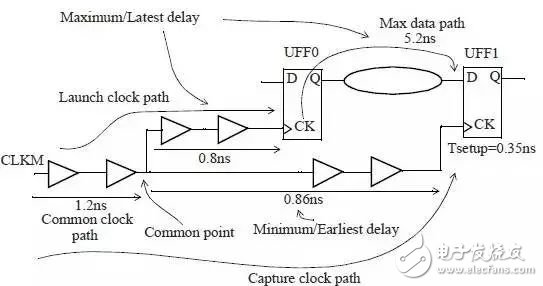
大家肯定发现了对于path最前端那1.2ns的延迟,在setup分析时,launch clock path中没有被derate, 而在capture clock path中被time derate 1.2*0.9 =1.08. 显然这是相互矛盾的。
对于上诉设计,考虑CPPR之后,我们必须减去一个CPP因子=1.2-1.08=0.12
所以最小时钟周期T=5.731-0.12 = 5.611
使用方法:
set_analysis_mode -cppr {none|both|setup|hold}
介绍的时序分析概念是AOCV。全称Stage Based Advanced OCV。我们知道,在OCV分析过程中,我们会给data path,clock path上设定单一的timing derate值。随着工艺演变的加速,我们发现这种设置方法是过于悲观的,大家可以想象下,OCV是片上误差,就代表一条path上有的cell delay大于标准值,那也有的cell delay会小于标准值。因此不能一味的加大或减小delay来模拟片上误差。
如下图所示,对于下面这样一条buffer链,假设8个buffer处于不同的PVT条件下,OCV会将8个buffer都选用最差的条件来分析(同一derate参数),而AOCV则会采用不同的timing derate值来分析。

AOCV有它专门的libary库,我们称为AOCV table。按照维度分为两种,一种是一位的只以stage count作为计算的表格,如下图所示:
version: 2.0
object_type: lib_cell
object_spec: LIB/BUF1X
rf_type: rise fall
delay_type: cell
derate_type: late
path_type: data
depth: 1 2 3 4 5
distance:
table: \
1.123 1.090 1.075 1.067 1.062
depth就代表着stage count,从表格中我们可以看到随着;路径的深入,derate的效应会减小。那我们怎么来计算stage count呢?
通常这个计算方法比较复杂,不同的电路情况对应着不同的count计算方式:如下timing path,我们将L1,L2,DFF1,U1,U2,U3的stage count设成6,而C1,C2,C3,C4的stage count需要设成4,这边需要说明的是B1,B2由于是common point,所以在计算stage count时需要忽略。
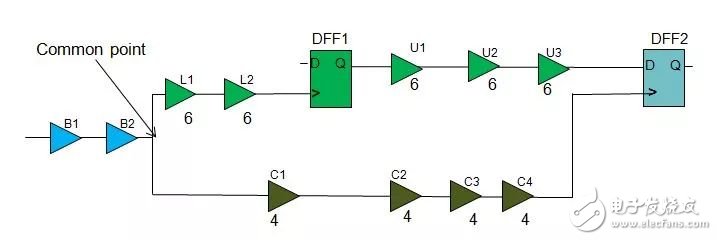
另外一种是以distance和stage count混合组成的二维AOCV table. 它在计算derate时同时考虑了timing path的距离因素,当然这个虽然更加精确,但是会增加runtime,所以一般现在一维表格用的更多。
version: 2.0
object_type: lib_cell
object_spec: LIB/BUF1X
rf_type: rise fall
delay_type: cell
derate_type: late
path_type: data
depth: 1 2 3 4 5
distance: 500 1000 1500 2000
table: \
1.123 1.090 1.075 1.067 1.062 \
1.124 1.091 1.076 1.068 1.063 \
1.125 1.092 1.077 1.070 1.065 \
1.126 1.094 1.079 1.072 1.067
使用方法:
set_analysis_mode -aocv true
-
时序分析中的一些基本概念2017-02-11 3976
-
时序分析基本概念介绍——时序库Lib,除了这些你还想知道什么?2017-12-15 10559
-
详细介绍时序基本概念Timing arc2018-01-02 23591
-
时序分析基本概念介绍2019-05-14 5425
-
FPGA设计中时序分析的基本概念2022-03-18 2129
-
静态时序分析的基本概念和方法2023-06-28 797
-
介绍时序分析的基本概念lookup table2023-07-03 746
-
时序分析概念min pulse width介绍2023-07-03 1362
-
clock gate时序分析概念介绍2023-07-03 1680
-
SOCV时序分析概念简析2023-07-03 1596
-
AOCV时序分析概念介绍2023-07-03 1276
-
介绍时序分析基本概念MMMC2023-07-04 1587
-
时序分析Slew/Transition基本概念介绍2023-07-05 1674
-
时序分析基本概念介绍—时序库Lib2023-07-07 1781
全部0条评论

快来发表一下你的评论吧 !
