

简要解释one hot编码这一机器学习中极为常见的技术
电子说
描述
编者按:数据科学家Rakshith Vasudev简要解释了one hot编码这一机器学习中极为常见的技术。
图片来源:imgur
你可能在有关机器学习的很多文档、文章、论文中接触到“one hot编码”这一术语。本文将科普这一概念,介绍one hot编码到底是什么。
一句话概括:one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
通过例子可能更容易理解这个概念。
假设我们有一个迷你数据集:
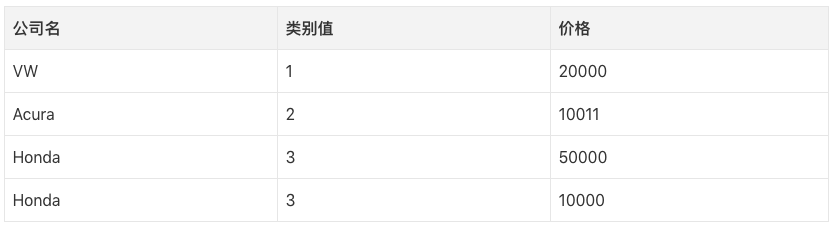
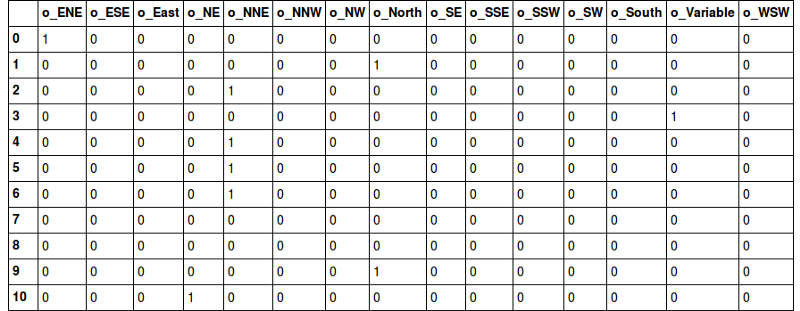
其中,类别值是分配给数据集中条目的数值编号。比如,如果我们在数据集中新加入一个公司,那么我们会给这家公司一个新类别值4。当独特的条目增加时,类别值将成比例增加。
在上面的表格中,类别值从1开始,更符合日常生活中的习惯。实际项目中,类别值从0开始(因为大多数计算机系统计数),所以,如果有N个类别,类别值为0至N-1.
sklear的LabelEncoder可以帮我们完成这一类别值分配工作。
现在让我们继续讨论one hot编码,将以上数据集one hot编码后,我们得到的表示如下:
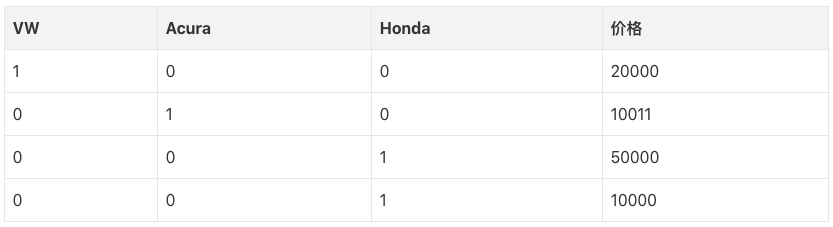
在我们继续之前,你可以想一下为什么不直接提供标签编码给模型训练就够了?为什么需要one hot编码?
标签编码的问题是它假定类别值越高,该类别更好。“等等,什么!”
让我解释一下:根据标签编码的类别值,我们的迷你数据集中VW > Acura > Honda。比方说,假设模型内部计算平均值(神经网络中有大量加权平均运算),那么1 + 3 = 4,4 / 2 = 2. 这意味着:VW和Honda平均一下是Acura。毫无疑问,这是一个糟糕的方案。该模型的预测会有大量误差。
我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征,原因正在于此。
当然,如果我们在设计网络的时候考虑到这点,对标签编码的类别值进行特别处理,那就没问题。不过,在大多数情况下,使用one hot编码是一个更简单直接的方案。
另外,如果原本的标签编码是有序的,那one hot编码就不合适了——会丢失顺序信息。
最后,我们用一个例子总结下本文:
假设“花”的特征可能的取值为daffodil(水仙)、lily(百合)、rose(玫瑰)。one hot编码将其转换为三个特征:is_daffodil、is_lily、is_rose,这些特征都是二进制的。
-
《计算机研究与发展》—机器学习的可解释性2022-01-25 822
-
FPGA技术与数字系统设计基础,学习这一门必看2018-05-26 0
-
基于深度学习技术的智能机器人2018-05-31 0
-
可解释的机器学习——打开机器学习黑匣子2020-05-20 0
-
机器学习的相关资料下载2021-12-14 0
-
HOT-51-一个学习板的原理图2017-02-07 697
-
机器学习应用中的常见问题分类问题你了解多少2018-03-29 14605
-
详谈机器学习的决策树模型2020-07-06 3119
-
如何通过XGBoost解释机器学习2020-10-12 1583
-
关于机器学习模型的六大可解释性技术2022-02-26 1873
-
机器学习模型的可解释性算法详解2022-02-16 4049
-
可解释机器学习2022-06-17 243
-
可以提高机器学习模型的可解释性技术2023-02-08 911
-
编码器在伺服的作用与常见伺服编码器2023-05-25 2740
-
什么是特征工程?机器学习的特征工程详解解读2023-12-28 167
全部0条评论

快来发表一下你的评论吧 !
