

卷积神经网络的介绍和应用用欧姆蛋来详细介绍
电子说
描述
▌介绍
关于卷积神经网络从交通灯识别到更实际的应用,我经常听到这样一个问题:“会否出现一种深度学习“魔法”,它仅用图像作为单一输入就能判断出食物质量的好坏?”简而言之,在商业中需要的就是这个:
当企业家面对机器学习时,他们是这样想的:欧姆蛋的“质量(quality)”是好的。
这是一个不适定问题的例子:解决方案是否存在,解决方案是否唯一且稳定还没办法确定,因为“完成”的定义非常模糊(更不用说实现了)。虽然这篇文章并不是关于高效沟通或是项目管理,但有一点是很有必要的:永远不要对没有明确范围的项目作出承诺。解决这种模棱两可的问题,一个好办法是先构建一个原型模式,然后再专注于完成后续任务的架构,这就是我们的策略。
▌问题定义
在我的原型实现中关注的是欧姆蛋(omelette),并构建了一个可扩展的数据管道,该管道输出煎蛋的感知“质量”。可以这样来概括:
问题类型:多类别分类,6 种离散的质量类别:[good, broken_yolk, overroasted, two_eggs, four_eggs, misplaced_pieces]。
数据集:人工收集了 351 个 DSLR 相机拍摄的各种煎蛋,其中:训练集包含 139 张图像;训练过程中的测试集包含 32 张图像;测试集包含 180 张图像。
标签:每张照片都标有主观的质量等级。
度量标准:分类交叉熵。
必要的知识:三个蛋黄没有破损,有一些培根和欧芹,没有烧焦或残碎的食物,则可以定义为“好的”煎蛋。
完成的定义:在两周的原型模式设计后,测试集上产生的最佳交叉熵。
结果可视化:用于测试集上低维度数据展示的 t-SNE 算法。
相机采集的输入图像
本文的主要目标就是用一个神经网络分类器获取提取的信号,并对其进行融合,让分类器就测试集上每一项的类概率进行 softmax 预测。下面是一些我们提取并发现有用的信号:
关键成分掩码(Mask R-CNN):Signal #1.
按照每个成分分组的关键成分计数(基本上是不同成分计数的矩阵):Signal #2.
移除盛欧姆蛋盘子的 RGB 颜色和背景,不添加到模型中。这就比较明显了:只需用损失函数在这些图像上训练一个卷积网络分类器,在低维嵌入一个选定模型图像到当前图像之间的 L2 距离。但是这次训练只用了 139 张图像,因此无法验证这一假设。
▌通用 50K 管道视图(50K Pipeline Overview)
我省略了几个重要步骤,诸如数据发现和探索性分析,基线和 MASK R-CNN 的主动标记管道(这是我为半监督的实例注释所起的名称,启发来自Polygon-RNN demo video-https://www.youtube.com/watch?v=S1UUR4FlJ84)。50K 管道视图如下:
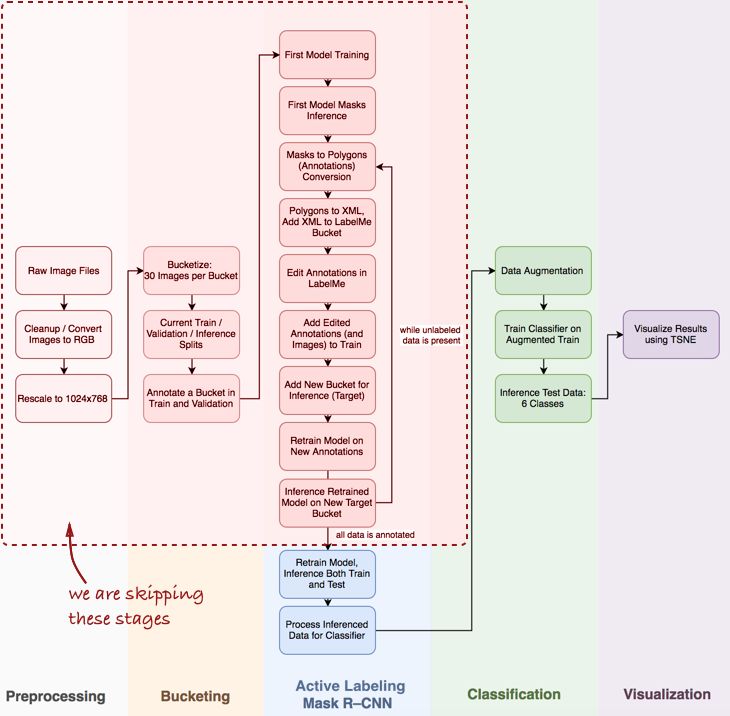
Mask R-CNN 以及管道的分类步骤
主要有三个步骤:[1]用于成分掩码推断的 MASK R-CNN,[2]基于 Keras 的卷积网络分类器,[3]t-SNE 算法的结果数据集可视化。
步骤一:Mask R-CNN 和掩码推断
Mask R-CNN 最近较为流行。从最初的 Facebook’s 论文开始,再到 Kaggle 上的 Data Science Bowl 2018 ,MASK R-CNN 证明了其强大的体系结构,比如分割(对象感知分割)。本文所使用的基于 Keras 的 MRCNN 代码结构良好、文档完整、工作迅速,但是速度比预期的要慢。
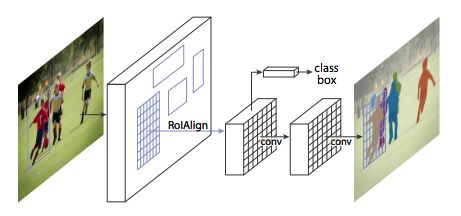
最新论文所展现的 MRCNN 框架
MRCNN 由两个部分组成:主干网络和网络头,它继承了 Faster R-CNN 架构。不管是基于特征金字塔网络(FPN)还是 ResNet 101,卷积主干网络都是整个图像的特征提取器。在此之上的是区域提议网络(RPN),它为头部采样感兴趣区域(ROI)。网络头部对每个 ROI 进行包围盒识别和掩码预测。在此过程中,RoIAlign 层精细地将 RPN 提取的多尺度特征与输入内容进行匹配。
在实际应用中,特别是在原型设计中,经过预先训练的卷积神经网络是其关键所在。在许多实际场景中,数据科学家通常有数量有限的注释数据集,有些甚至没有任何注释。相反,卷积网络需要大量的标记数据集进行收敛(如 ImageNet 数据集包含 120 万标记图像)。这就是需要迁移学习的用处所在:冻结卷积层的权重,只对分类器进行再训练。对于小型数据集来说,冻结卷积层权重可以避免过拟合。
经过一次(epoch )训练所取得的样本如下图所示:
实例分割的结果:所有关键成分都被检测到
下一步是裁剪碟子部分,并从中为每一成分提取二维二进制掩码:
带有目标碟子及如二进制掩码一样关键成分部分
这些二进制掩码紧接着组成一个 8 通道图像( MRCNN 定义了 8 个掩码类别)。Signal #1 如下图所示:
Signal #1:由二进制掩码组成的 8 通道图像。不同的颜色只为了能更好进行可视化观察。
对于 Signal #2,MRCNN 推断出每一种成分的量,并将其打包成一个特征向量。
步骤二:基于 Keras 的卷积神经网络分类器
我们已经使用 Keras 从头构建了一个 CNN 分类器。其目标是整合几个信号(Signal#1 和 Signal#2,未来还会再添加更多数据),并让网络对食物的质量类别做出预测。真实的体系结构如下:
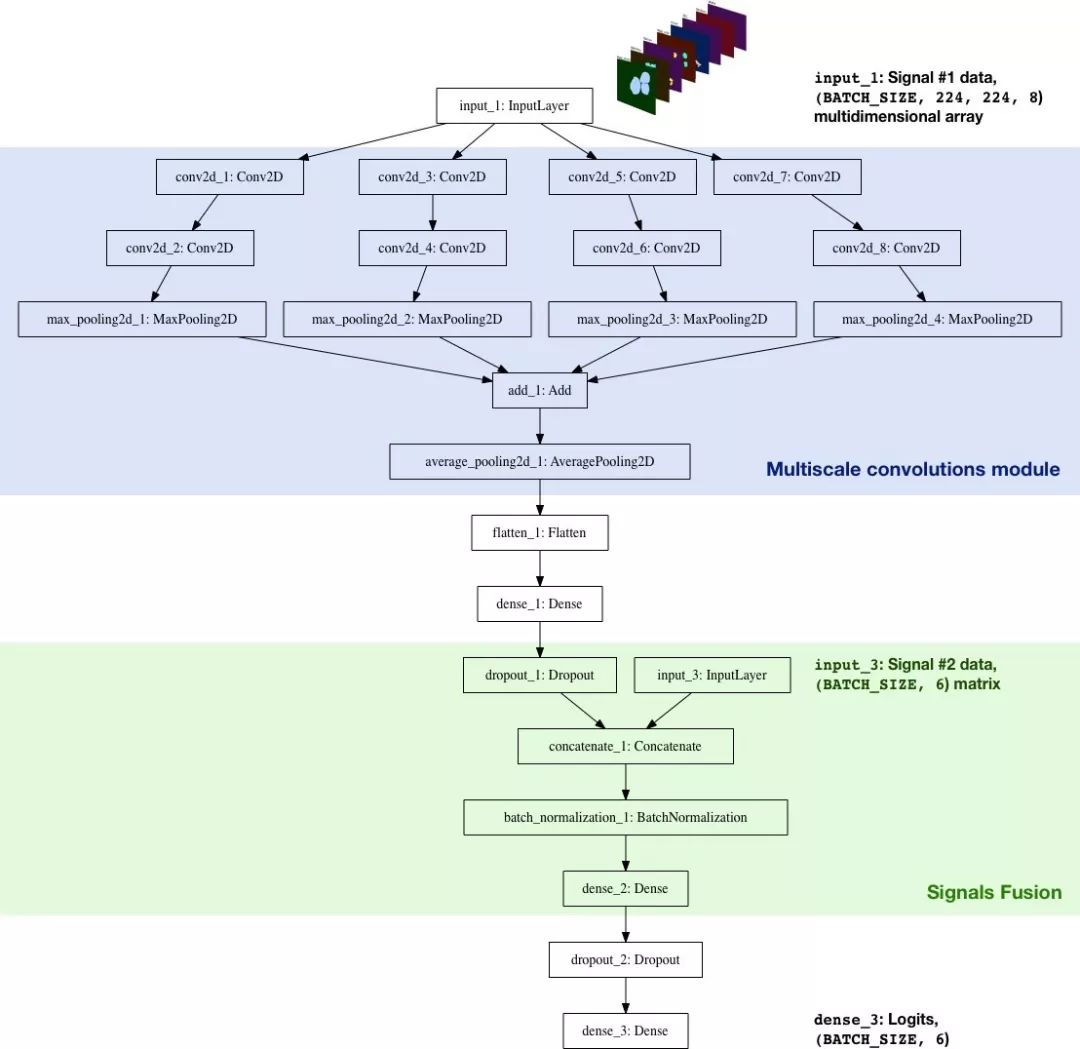
分类器架构的特点如下:
多尺度卷积模块:最初,卷积层的内核大小为 5*5,结果不如人意,但有几种不同内核(3*3,5*5,7*7,11*11)的卷积层的 AveragePooling2D 效果更好。另外,在每层前增加了大小为 1*1 的卷积层来降低维度,它类似于 Inception 模块。
更大的内核:更大的内核更容易从输入图像中提取更大范围的特征(本身可以看作一个具有 8 个滤波器的激活层:每个部分的二进制掩码基本上就是一个滤波器)。
信号整合:该模型只使用了一个非线性层对两个特征集合:处理过的二进制掩码(Signal#1)和成分数(Signal#2)。Signal#2 提高了交叉熵(将交叉熵从 0.8 提高到[0.7,0.72]))
Logits:在 TensorFlow 中,这是 tf.nn.softmax_cross_entropy_with_logits 计算 batch 损失的层。
步骤三:使用 t-SNE 对结果进行可视化处理
使用 t-SNE 算法对结果进行可视化处理,它是一种较为流行的数据可视化技术。t-SNE 最小化了低维嵌入数据点和原始高维数据(使用非凸损失函数)的联合概率之间的 KL 散度。
为了将测试集的分类结果可视化,我导出了测试集图像,提取了分类器的 logits 层,并将 t-SNE 算法应用于结果数据集。效果相当不错,如下图所示:
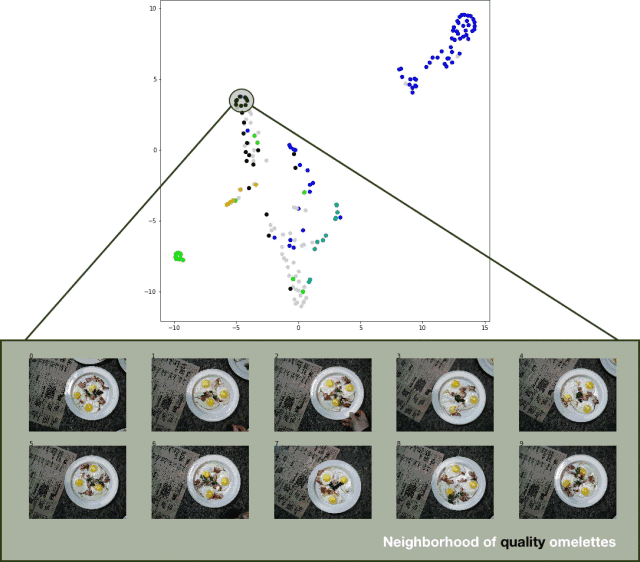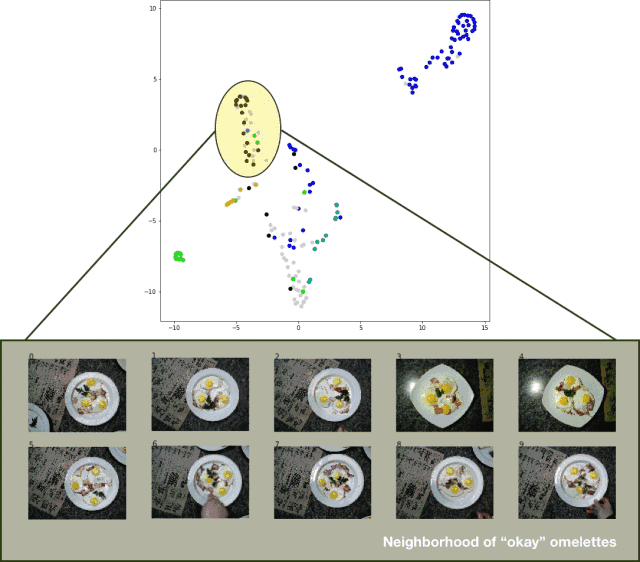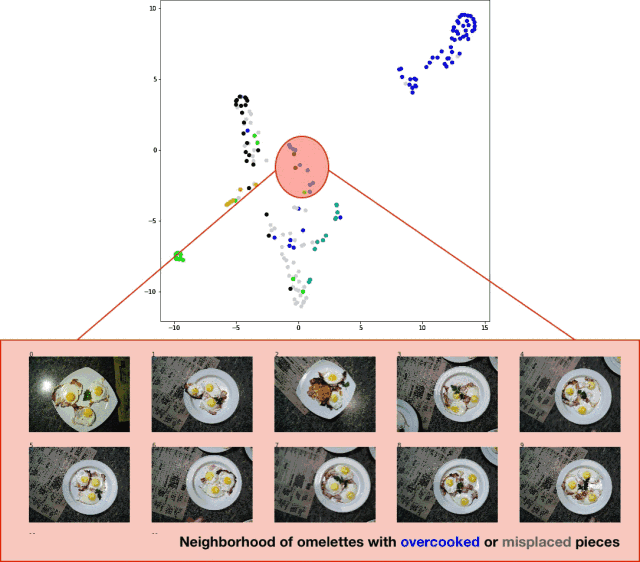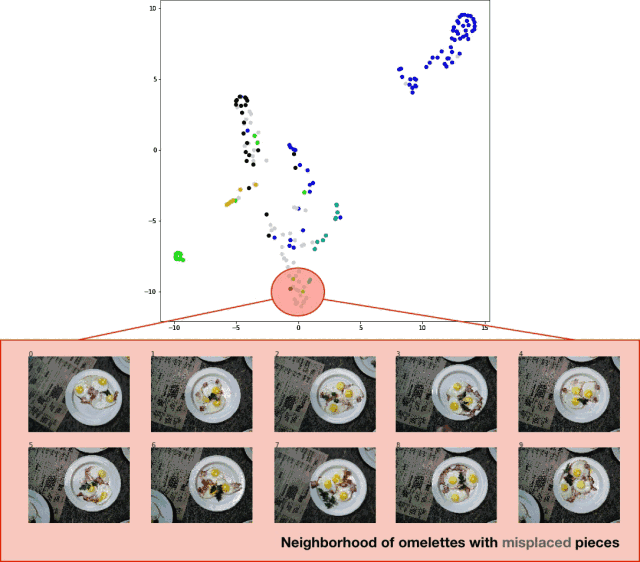
分类器测试集预测结果的 t-SNE 算法可视化效果
虽然结果并不是特别完美,但这种方法确实有效。 亟待改进的地方如下:
更多数据。卷积神经网络需要大量的数据,而这里用于训练的样本只有 139 个,本文使用的数据增强技术特别好(使用 D4 或 dihedral, symmetry 产生 2 千多张增强图像)。但是,想要一个良好的性能,更多真实的数据尤为重要。
合适的损失函数。为了简单起见,本文使用了分类交叉熵损失函数。也可以使用更合适的损失函数——三重损失函数(triplet loss),它能够更好地利用类内差异。
更全面的分类器体系结构。当前的分类器基本上是一个原型模式,旨在解释输入二进制掩码,并将多个特征集整合到单个推理管道。
更好的标签。我在手动图像标记(6 种类别的质量)方面的确不在行:分类器在十几个测试集图像上的表现超出了我的预期。
▌反思
在实际应用中,企业没有数据、注释,也没有需要完成的明确任务,但这种现象非常普遍,这不可否认。这对你来说是一件好事:你要做的就是拥有工具和足够多的 GPU 硬件、商业和技术知识、预训练模型以及其他对企业有价值的东西。
从小事做起:一个可以用 LEGO 代码块构建的原型模式,可以进一步提高交流的效率——为企业提供这种方案,这是作为一位数据科学家的职责。
-
神经网络基本介绍2018-01-04 0
-
卷积神经网络入门资料2019-02-12 0
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 0
-
卷积神经网络如何使用2019-07-17 0
-
什么是图卷积神经网络?2019-08-20 0
-
卷积神经网络的优点是什么2020-05-05 0
-
请问为什么要用卷积神经网络?2020-06-13 0
-
卷积神经网络CNN介绍2020-06-14 0
-
卷积神经网络的层级结构和常用框架2020-12-29 0
-
卷积神经网络一维卷积的处理过程2021-12-23 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
卷积神经网络为什么适合图像处理?2022-09-08 0
-
【科普】卷积神经网络(CNN)基础介绍2017-11-16 10852
-
什么是神经网络?什么是卷积神经网络?2023-02-23 2544
-
卷积神经网络的介绍 什么是卷积神经网络算法2023-08-21 1425
全部0条评论

快来发表一下你的评论吧 !
